 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosine meets Softmax: A tough-to-beat baseline for visual grounding
Paper and Code

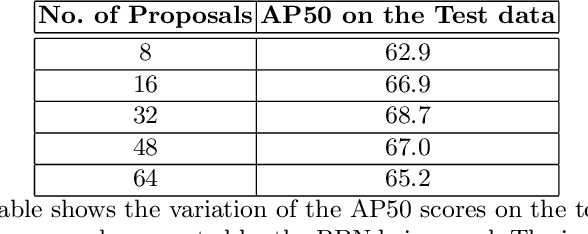

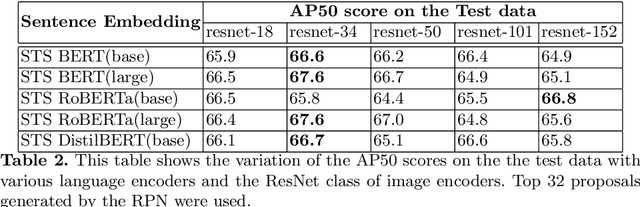
In this paper, we present a simple baseline for visual grounding for autonomous driving which outperforms the state of the art methods, while retaining minimal design choices. Our framework minimizes the cross-entropy loss over the cosine distance between multiple image ROI features with a text embedding (representing the give sentence/phrase). We use pre-trained networks for obtaining the initial embeddings and learn a transformation layer on top of the text embedding. We perform experiments on the Talk2Car dataset and achieve 68.7% AP50 accuracy, improving upon the previous state of the art by 8.6%. Our investigation suggests reconsideration towards more approaches employing sophisticated attention mechanisms or multi-stage reasoning or complex metric learning loss functions by showing promise in simpler alternatives.