 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Efficiency of Language Agent Teams with Adaptive Task Graphs
May 07, 2026Large language models (LLMs) are increasingly deployed in teams, yet existing coordination approaches often occupy two extremes. Highly structured methods rely on fixed roles, pipelines, or task decompositions assigned a priori. In contrast, fully unstructured teams enable adaptability and exploration but suffer from inefficiencies such as error propagation, inter-agent conflicts, and wasted resources (measured in time, tokens, or file operations). We introduce Language Agent Teams for Task Evolution (LATTE), a framework for coordinating LLM teams inspired by distributed systems, where processors must operate under partial observability and communication constraints. In LATTE, a team of agents collaboratively construct and maintain a shared, evolving coordination graph which encodes sub-task dependencies, individual agent assignment, and the current state of sub-task progress. This protocol maintains consistency while empowering agents to dynamically allocate work, adapt coordination, and discover new tasks. Across multiple collaborative tasks and a variety of base models, we demonstrate how LATTE reduces token usage, wall-clock time, communication, and coordination failures (e.g. file conflicts and redundant outputs) while matching or exceeding the accuracy of standard designs including MetaGPT, decentralized teams, top-down Leader-Worker hierarchies, and static decompositions.
Is this the real life? Is this just fantasy? The Misleading Success of Simulating Social Interactions With LLMs
Mar 08, 2024Recent advances in large language models (LLM) have enabled richer social simulations, allowing for the study of various social phenomena with LLM-based agents. However, most work has used an omniscient perspective on these simulations (e.g., single LLM to generate all interlocutors), which is fundamentally at odds with the non-omniscient, information asymmetric interactions that humans have. To examine these differences, we develop an evaluation framework to simulate social interactions with LLMs in various settings (omniscient, non-omniscient). Our experiments show that interlocutors simulated omnisciently are much more successful at accomplishing social goals compared to non-omniscient agents, despite the latter being the more realistic setting. Furthermore, we demonstrate that learning from omniscient simulations improves the apparent naturalness of interactions but scarcely enhances goal achievement in cooperative scenarios. Our findings indicate that addressing information asymmetry remains a fundamental challenge for LLM-based agents.
A Systematic Comparison of Syllogistic Reasoning in Humans and Language Models
Nov 01, 2023



A central component of rational behavior is logical inference: the process of determining which conclusions follow from a set of premises. Psychologists have documented several ways in which humans' inferences deviate from the rules of logic. Do language models, which are trained on text generated by humans, replicate these biases, or are they able to overcome them? Focusing on the case of syllogisms -- inferences from two simple premises, which have been studied extensively in psychology -- we show that larger models are more logical than smaller ones, and also more logical than humans. At the same time, even the largest models make systematic errors, some of which mirror human reasoning biases such as ordering effects and logical fallacies. Overall, we find that language models mimic the human biases included in their training data, but are able to overcome them in some cases.
Probing for Incremental Parse States in Autoregressive Language Models
Nov 17, 2022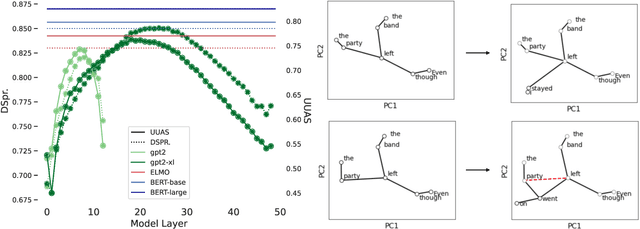
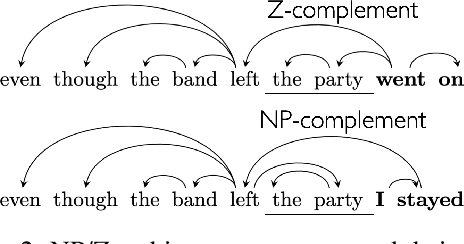
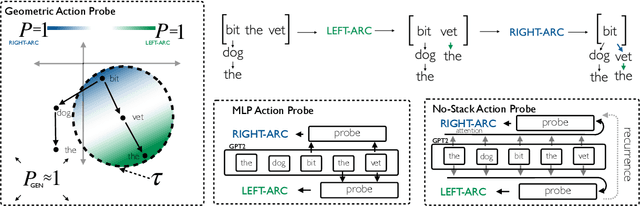
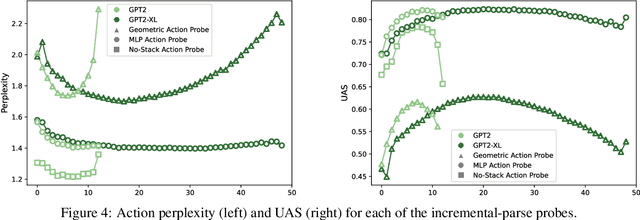
Next-word predictions from autoregressive neural language models show remarkable sensitivity to syntax. This work evaluates the extent to which this behavior arises as a result of a learned ability to maintain implicit representations of incremental syntactic structures. We extend work in syntactic probing to the incremental setting and present several probes for extracting incomplete syntactic structure (operationalized through parse states from a stack-based parser) from autoregressive language models. We find that our probes can be used to predict model preferences on ambiguous sentence prefixes and causally intervene on model representations and steer model behavior. This suggests implicit incremental syntactic inferences underlie next-word predictions in autoregressive neural language models.
When Does Syntax Mediate Neural Language Model Performance? Evidence from Dropout Probes
Apr 20, 2022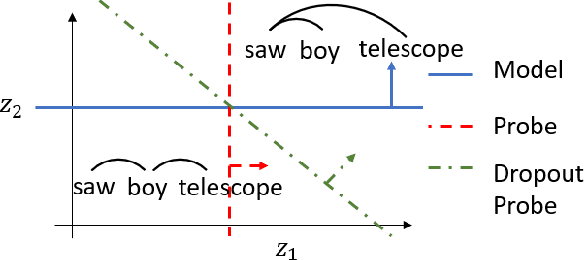
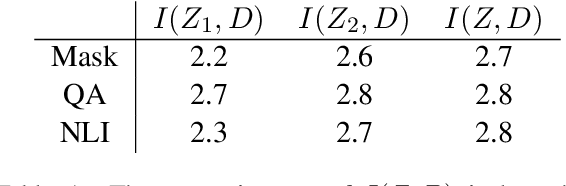
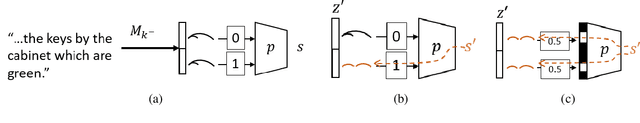

Recent causal probing literature reveals when language models and syntactic probes use similar representations. Such techniques may yield "false negative" causality results: models may use representations of syntax, but probes may have learned to use redundant encodings of the same syntactic information. We demonstrate that models do encode syntactic information redundantly and introduce a new probe design that guides probes to consider all syntactic information present in embeddings. Using these probes, we find evidence for the use of syntax in models where prior methods did not, allowing us to boost model performance by injecting syntactic information into representations.