 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Guided Complexity-Controlled Abstractions
Oct 27, 2023



Neural networks often learn task-specific latent representations that fail to generalize to novel settings or tasks. Conversely, humans learn discrete representations (i.e., concepts or words) at a variety of abstraction levels (e.g., "bird" vs. "sparrow") and deploy the appropriate abstraction based on task. Inspired by this, we train neural models to generate a spectrum of discrete representations, and control the complexity of the representations (roughly, how many bits are allocated for encoding inputs) by tuning the entropy of the distribution over representations. In finetuning experiments, using only a small number of labeled examples for a new task, we show that (1) tuning the representation to a task-appropriate complexity level supports the highest finetuning performance, and (2) in a human-participant study, users were able to identify the appropriate complexity level for a downstream task using visualizations of discrete representations. Our results indicate a promising direction for rapid model finetuning by leveraging human insight.
An Information Bottleneck Characterization of the Understanding-Workload Tradeoff
Oct 11, 2023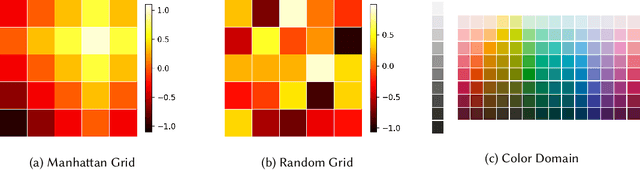
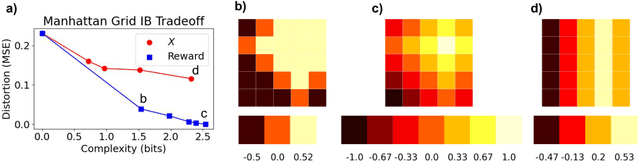
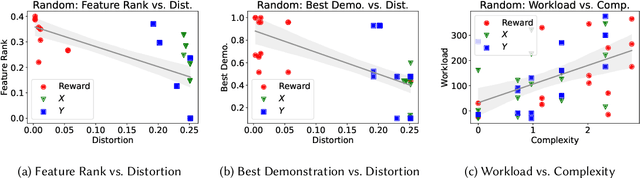
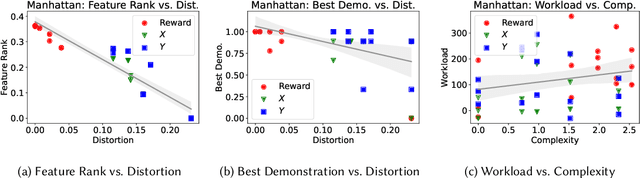
Recent advances in artificial intelligence (AI) have underscored the need for explainable AI (XAI) to support human understanding of AI systems. Consideration of human factors that impact explanation efficacy, such as mental workload and human understanding, is central to effective XAI design. Existing work in XAI has demonstrated a tradeoff between understanding and workload induced by different types of explanations. Explaining complex concepts through abstractions (hand-crafted groupings of related problem features) has been shown to effectively address and balance this workload-understanding tradeoff. In this work, we characterize the workload-understanding balance via the Information Bottleneck method: an information-theoretic approach which automatically generates abstractions that maximize informativeness and minimize complexity. In particular, we establish empirical connections between workload and complexity and between understanding and informativeness through human-subject experiments. This empirical link between human factors and information-theoretic concepts provides an important mathematical characterization of the workload-understanding tradeoff which enables user-tailored XAI design.
Towards True Lossless Sparse Communication in Multi-Agent Systems
Nov 30, 2022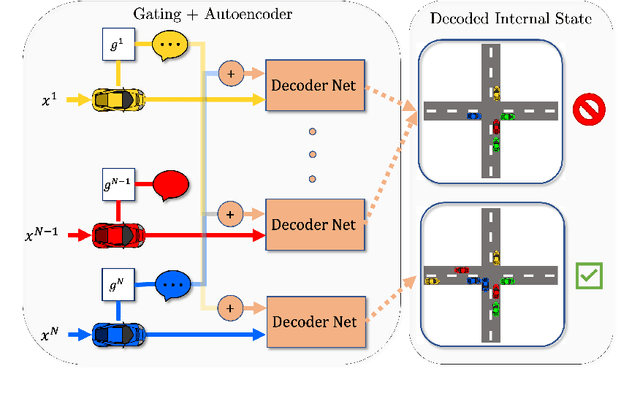
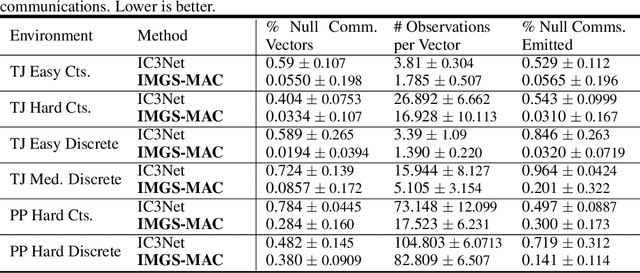
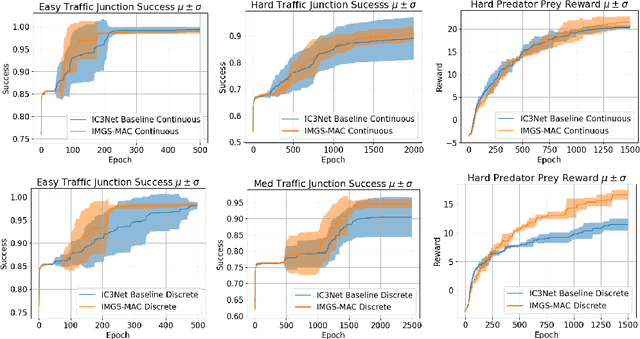

Communication enables agents to cooperate to achieve their goals. Learning when to communicate, i.e., sparse (in time) communication, and whom to message is particularly important when bandwidth is limited. Recent work in learning sparse individualized communication, however, suffers from high variance during training, where decreasing communication comes at the cost of decreased reward, particularly in cooperative tasks. We use the information bottleneck to reframe sparsity as a representation learning problem, which we show naturally enables lossless sparse communication at lower budgets than prior art. In this paper, we propose a method for true lossless sparsity in communication via Information Maximizing Gated Sparse Multi-Agent Communication (IMGS-MAC). Our model uses two individualized regularization objectives, an information maximization autoencoder and sparse communication loss, to create informative and sparse communication. We evaluate the learned communication `language' through direct causal analysis of messages in non-sparse runs to determine the range of lossless sparse budgets, which allow zero-shot sparsity, and the range of sparse budgets that will inquire a reward loss, which is minimized by our learned gating function with few-shot sparsity. To demonstrate the efficacy of our results, we experiment in cooperative multi-agent tasks where communication is essential for success. We evaluate our model with both continuous and discrete messages. We focus our analysis on a variety of ablations to show the effect of message representations, including their properties, and lossless performance of our model.
Towards Human-Agent Communication via the Information Bottleneck Principle
Jun 30, 2022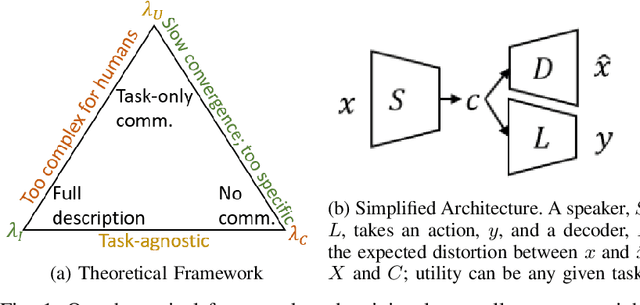
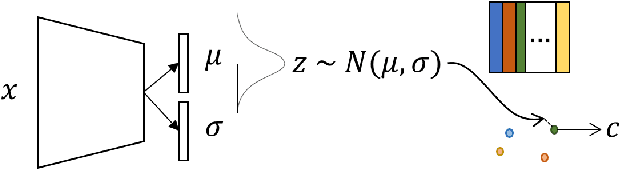
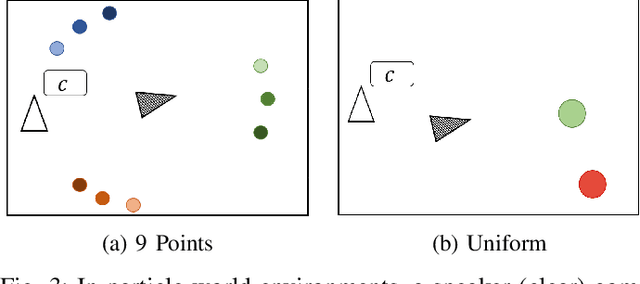

Emergent communication research often focuses on optimizing task-specific utility as a driver for communication. However, human languages appear to evolve under pressure to efficiently compress meanings into communication signals by optimizing the Information Bottleneck tradeoff between informativeness and complexity. In this work, we study how trading off these three factors -- utility, informativeness, and complexity -- shapes emergent communication, including compared to human communication. To this end, we propose Vector-Quantized Variational Information Bottleneck (VQ-VIB), a method for training neural agents to compress inputs into discrete signals embedded in a continuous space. We train agents via VQ-VIB and compare their performance to previously proposed neural architectures in grounded environments and in a Lewis reference game. Across all neural architectures and settings, taking into account communicative informativeness benefits communication convergence rates, and penalizing communicative complexity leads to human-like lexicon sizes while maintaining high utility. Additionally, we find that VQ-VIB outperforms other discrete communication methods. This work demonstrates how fundamental principles that are believed to characterize human language evolution may inform emergent communication in artificial agents.
Prototype Based Classification from Hierarchy to Fairness
May 27, 2022
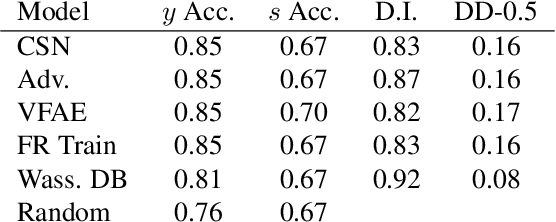
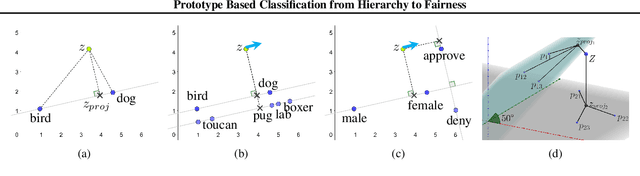
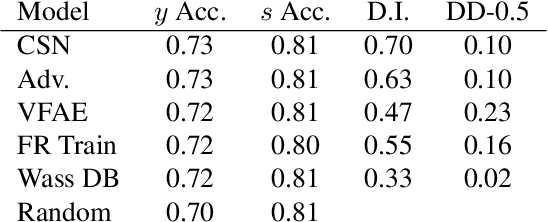
Artificial neural nets can represent and classify many types of data but are often tailored to particular applications -- e.g., for "fair" or "hierarchical" classification. Once an architecture has been selected, it is often difficult for humans to adjust models for a new task; for example, a hierarchical classifier cannot be easily transformed into a fair classifier that shields a protected field. Our contribution in this work is a new neural network architecture, the concept subspace network (CSN), which generalizes existing specialized classifiers to produce a unified model capable of learning a spectrum of multi-concept relationships. We demonstrate that CSNs reproduce state-of-the-art results in fair classification when enforcing concept independence, may be transformed into hierarchical classifiers, or even reconcile fairness and hierarchy within a single classifier. The CSN is inspired by existing prototype-based classifiers that promote interpretability.
When Does Syntax Mediate Neural Language Model Performance? Evidence from Dropout Probes
Apr 20, 2022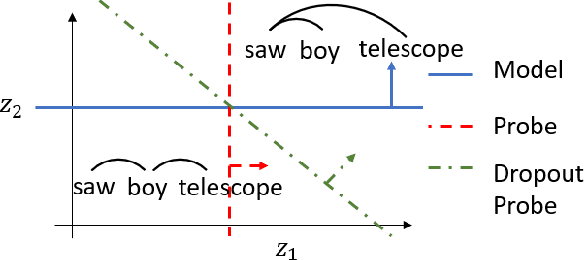
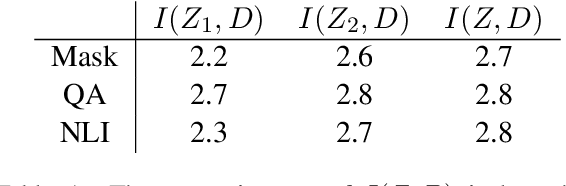
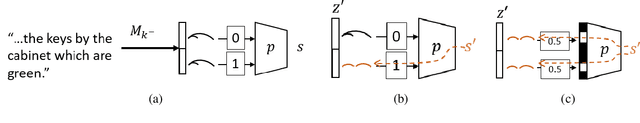

Recent causal probing literature reveals when language models and syntactic probes use similar representations. Such techniques may yield "false negative" causality results: models may use representations of syntax, but probes may have learned to use redundant encodings of the same syntactic information. We demonstrate that models do encode syntactic information redundantly and introduce a new probe design that guides probes to consider all syntactic information present in embeddings. Using these probes, we find evidence for the use of syntax in models where prior methods did not, allowing us to boost model performance by injecting syntactic information into representations.
Probe-Based Interventions for Modifying Agent Behavior
Jan 26, 2022Neural nets are powerful function approximators, but the behavior of a given neural net, once trained, cannot be easily modified. We wish, however, for people to be able to influence neural agents' actions despite the agents never training with humans, which we formalize as a human-assisted decision-making problem. Inspired by prior art initially developed for model explainability, we develop a method for updating representations in pre-trained neural nets according to externally-specified properties. In experiments, we show how our method may be used to improve human-agent team performance for a variety of neural networks from image classifiers to agents in multi-agent reinforcement learning settings.
The Enforcers: Consistent Sparse-Discrete Methods for Constraining Informative Emergent Communication
Jan 19, 2022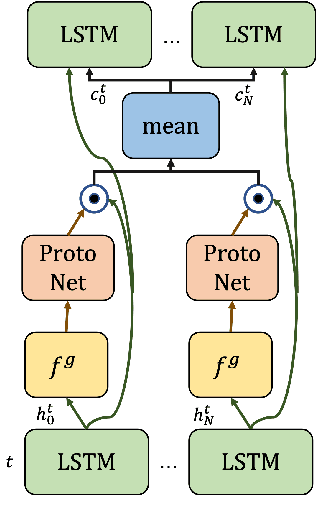
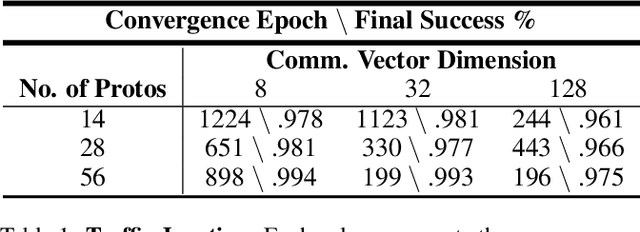
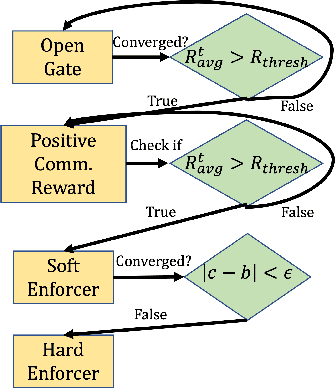
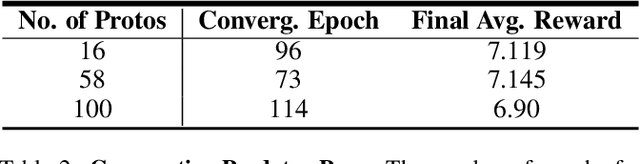
Communication enables agents to cooperate to achieve their goals. Learning when to communicate, i.e. sparse communication, is particularly important where bandwidth is limited, in situations where agents interact with humans, in partially observable scenarios where agents must convey information unavailable to others, and in non-cooperative scenarios where agents may hide information to gain a competitive advantage. Recent work in learning sparse communication, however, suffers from high variance training where, the price of decreasing communication is a decrease in reward, particularly in cooperative tasks. Sparse communications are necessary to match agent communication to limited human bandwidth. Humans additionally communicate via discrete linguistic tokens, previously shown to decrease task performance when compared to continuous communication vectors. This research addresses the above issues by limiting the loss in reward of decreasing communication and eliminating the penalty for discretization. In this work, we successfully constrain training using a learned gate to regulate when to communicate while using discrete prototypes that reflect what to communicate for cooperative tasks with partial observability. We provide two types of "Enforcers" for hard and soft budget constraints and present results of communication under different budgets. We show that our method satisfies constraints while yielding the same performance as comparable, unconstrained methods.
Emergent Discrete Communication in Semantic Spaces
Aug 05, 2021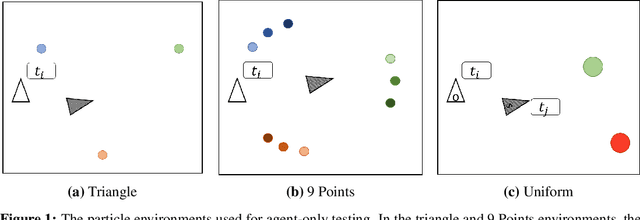
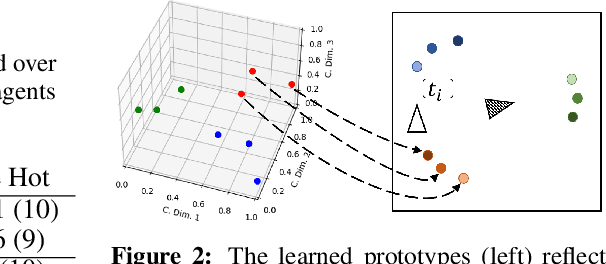

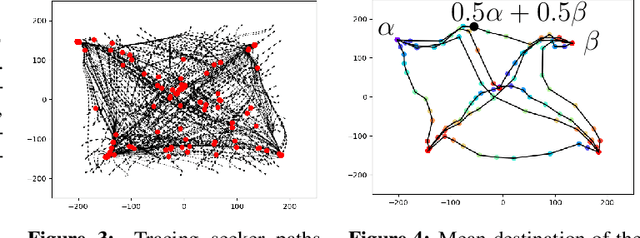
Neural agents trained in reinforcement learning settings can learn to communicate among themselves via discrete tokens, accomplishing as a team what agents would be unable to do alone. However, the current standard of using one-hot vectors as discrete communication tokens prevents agents from acquiring more desirable aspects of communication such as zero-shot understanding. Inspired by word embedding techniques from natural language processing, we propose neural agent architectures that enables them to communicate via discrete tokens derived from a learned, continuous space. We show in a decision theoretic framework that our technique optimizes communication over a wide range of scenarios, whereas one-hot tokens are only optimal under restrictive assumptions. In self-play experiments, we validate that our trained agents learn to cluster tokens in semantically-meaningful ways, allowing them communicate in noisy environments where other techniques fail. Lastly, we demonstrate both that agents using our method can effectively respond to novel human communication and that humans can understand unlabeled emergent agent communication, outperforming the use of one-hot communication.
What if This Modified That? Syntactic Interventions via Counterfactual Embeddings
May 28, 2021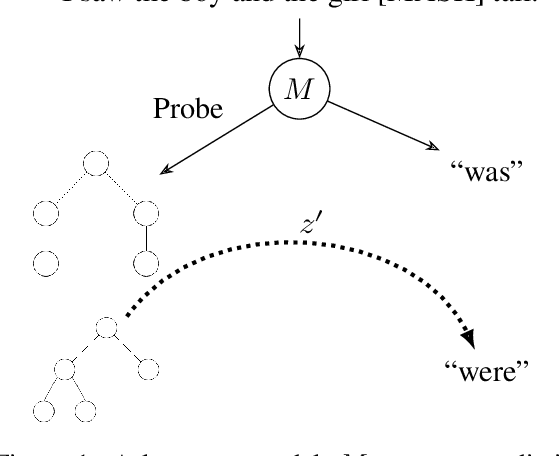

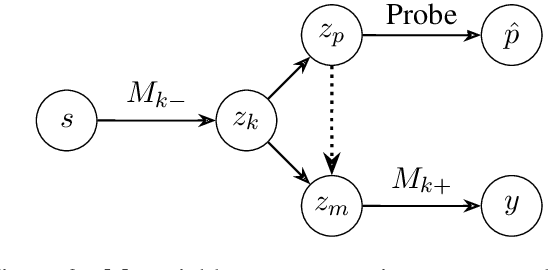
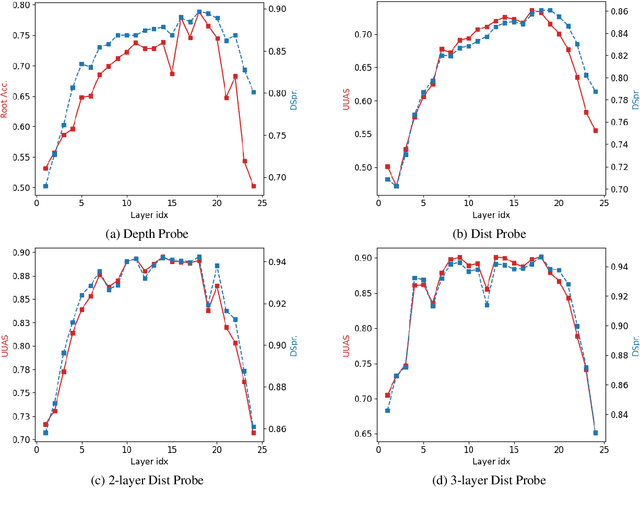
Neural language models exhibit impressive performance on a variety of tasks, but their internal reasoning may be difficult to understand. Prior art aims to uncover meaningful properties within model representations via probes, but it is unclear how faithfully such probes portray information that the models actually use. To overcome such limitations, we propose a technique, inspired by causal analysis, for generating counterfactual embeddings within models. In experiments testing our technique, we produce evidence that suggests some BERT-based models use a tree-distance-like representation of syntax in downstream prediction tasks.