 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndian Commercial Truck License Plate Detection and Recognition for Weighbridge Automation
Nov 23, 2022



Detection and recognition of a licence plate is important when automating weighbridge services. While many large databases are available for Latin and Chinese alphanumeric license plates, data for Indian License Plates is inadequate. In particular, databases of Indian commercial truck license plates are inadequate, despite the fact that commercial vehicle license plate recognition plays a profound role in terms of logistics management and weighbridge automation. Moreover, models to recognise license plates are not effectively able to generalise to such data due to its challenging nature, and due to the abundant frequency of handwritten license plates, leading to the usage of diverse font styles. Thus, a database and effective models to recognise and detect such license plates are crucial. This paper provides a database on commercial truck license plates, and using state-of-the-art models in real-time object Detection: You Only Look Once Version 7, and SceneText Recognition: Permuted Autoregressive Sequence Models, our method outperforms the other cited references where the maximum accuracy obtained was less than 90%, while we have achieved 95.82% accuracy in our algorithm implementation on the presented challenging license plate dataset. Index Terms- Automatic License Plate Recognition, character recognition, license plate detection, vision transformer.
The Enforcers: Consistent Sparse-Discrete Methods for Constraining Informative Emergent Communication
Jan 19, 2022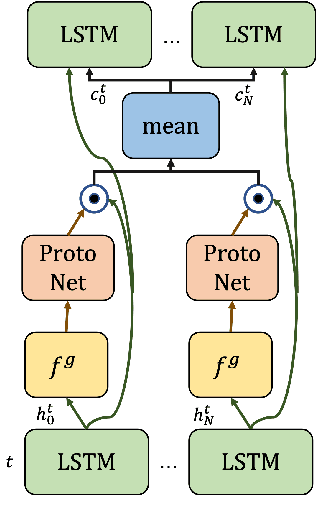
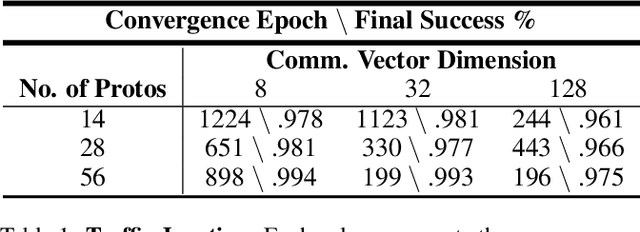
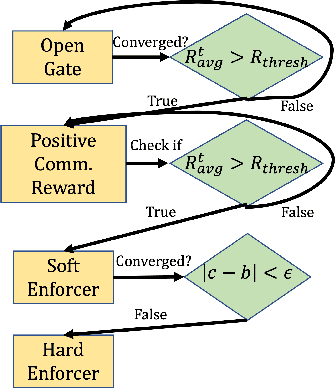
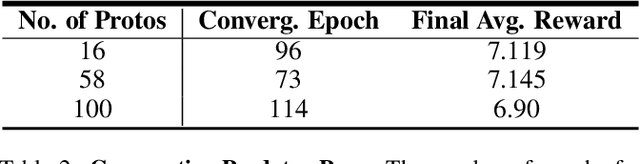
Communication enables agents to cooperate to achieve their goals. Learning when to communicate, i.e. sparse communication, is particularly important where bandwidth is limited, in situations where agents interact with humans, in partially observable scenarios where agents must convey information unavailable to others, and in non-cooperative scenarios where agents may hide information to gain a competitive advantage. Recent work in learning sparse communication, however, suffers from high variance training where, the price of decreasing communication is a decrease in reward, particularly in cooperative tasks. Sparse communications are necessary to match agent communication to limited human bandwidth. Humans additionally communicate via discrete linguistic tokens, previously shown to decrease task performance when compared to continuous communication vectors. This research addresses the above issues by limiting the loss in reward of decreasing communication and eliminating the penalty for discretization. In this work, we successfully constrain training using a learned gate to regulate when to communicate while using discrete prototypes that reflect what to communicate for cooperative tasks with partial observability. We provide two types of "Enforcers" for hard and soft budget constraints and present results of communication under different budgets. We show that our method satisfies constraints while yielding the same performance as comparable, unconstrained methods.
Emergent Discrete Communication in Semantic Spaces
Aug 05, 2021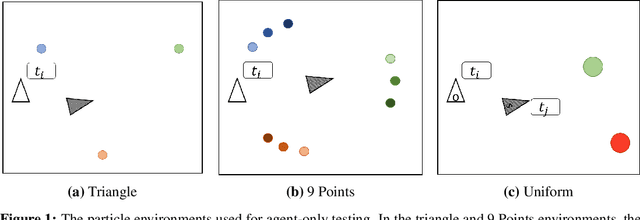
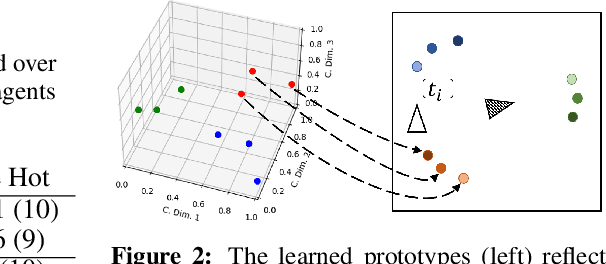

Neural agents trained in reinforcement learning settings can learn to communicate among themselves via discrete tokens, accomplishing as a team what agents would be unable to do alone. However, the current standard of using one-hot vectors as discrete communication tokens prevents agents from acquiring more desirable aspects of communication such as zero-shot understanding. Inspired by word embedding techniques from natural language processing, we propose neural agent architectures that enables them to communicate via discrete tokens derived from a learned, continuous space. We show in a decision theoretic framework that our technique optimizes communication over a wide range of scenarios, whereas one-hot tokens are only optimal under restrictive assumptions. In self-play experiments, we validate that our trained agents learn to cluster tokens in semantically-meaningful ways, allowing them communicate in noisy environments where other techniques fail. Lastly, we demonstrate both that agents using our method can effectively respond to novel human communication and that humans can understand unlabeled emergent agent communication, outperforming the use of one-hot communication.
Adaptive Agent Architecture for Real-time Human-Agent Teaming
Mar 07, 2021
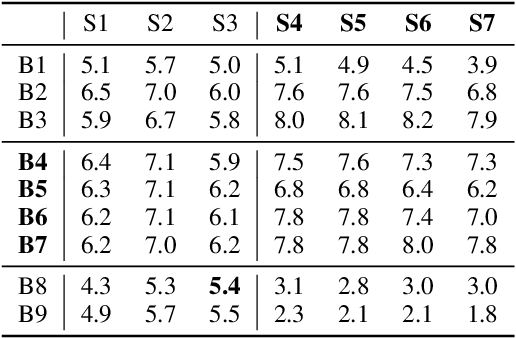
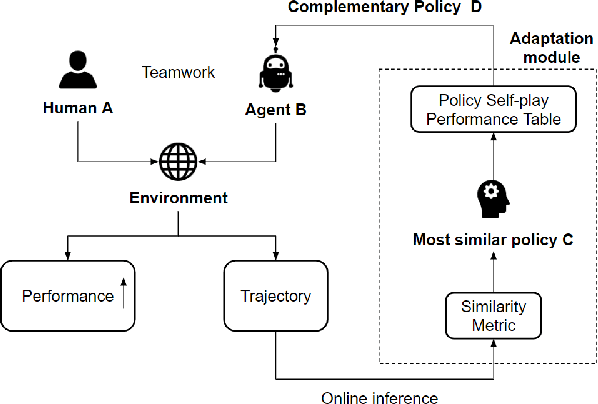
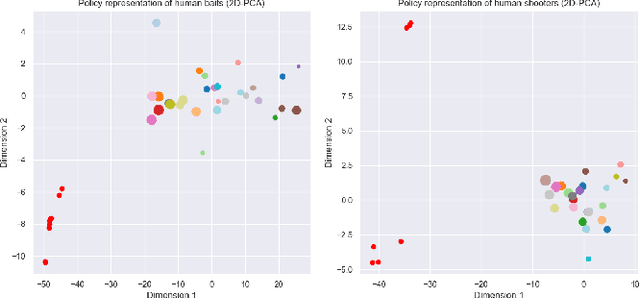
Teamwork is a set of interrelated reasoning, actions and behaviors of team members that facilitate common objectives. Teamwork theory and experiments have resulted in a set of states and processes for team effectiveness in both human-human and agent-agent teams. However, human-agent teaming is less well studied because it is so new and involves asymmetry in policy and intent not present in human teams. To optimize team performance in human-agent teaming, it is critical that agents infer human intent and adapt their polices for smooth coordination. Most literature in human-agent teaming builds agents referencing a learned human model. Though these agents are guaranteed to perform well with the learned model, they lay heavy assumptions on human policy such as optimality and consistency, which is unlikely in many real-world scenarios. In this paper, we propose a novel adaptive agent architecture in human-model-free setting on a two-player cooperative game, namely Team Space Fortress (TSF). Previous human-human team research have shown complementary policies in TSF game and diversity in human players' skill, which encourages us to relax the assumptions on human policy. Therefore, we discard learning human models from human data, and instead use an adaptation strategy on a pre-trained library of exemplar policies composed of RL algorithms or rule-based methods with minimal assumptions of human behavior. The adaptation strategy relies on a novel similarity metric to infer human policy and then selects the most complementary policy in our library to maximize the team performance. The adaptive agent architecture can be deployed in real-time and generalize to any off-the-shelf static agents. We conducted human-agent experiments to evaluate the proposed adaptive agent framework, and demonstrated the suboptimality, diversity, and adaptability of human policies in human-agent teams.
Addressing reward bias in Adversarial Imitation Learning with neutral reward functions
Sep 20, 2020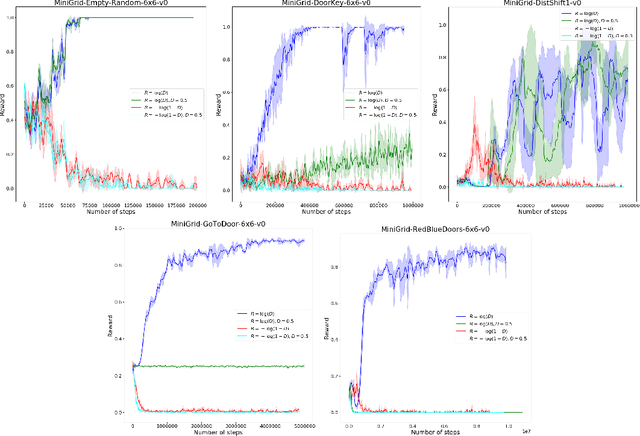
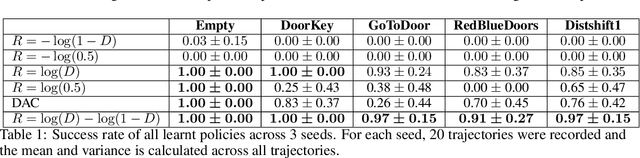
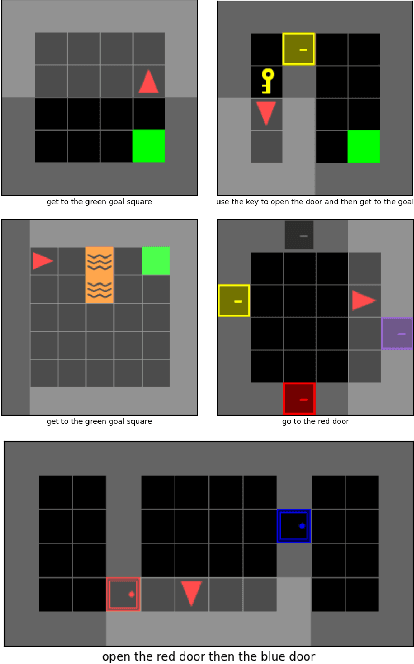
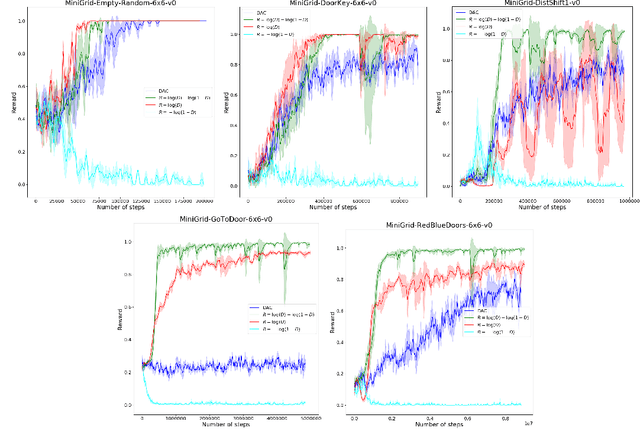
Generative Adversarial Imitation Learning suffers from the fundamental problem of reward bias stemming from the choice of reward functions used in the algorithm. Different types of biases also affect different types of environments - which are broadly divided into survival and task-based environments. We provide a theoretical sketch of why existing reward functions would fail in imitation learning scenarios in task based environments with multiple terminal states. We also propose a new reward function for GAIL which outperforms existing GAIL methods on task based environments with single and multiple terminal states and effectively overcomes both survival and termination bias.
Deep Variational Inference Without Pixel-Wise Reconstruction
Nov 16, 2016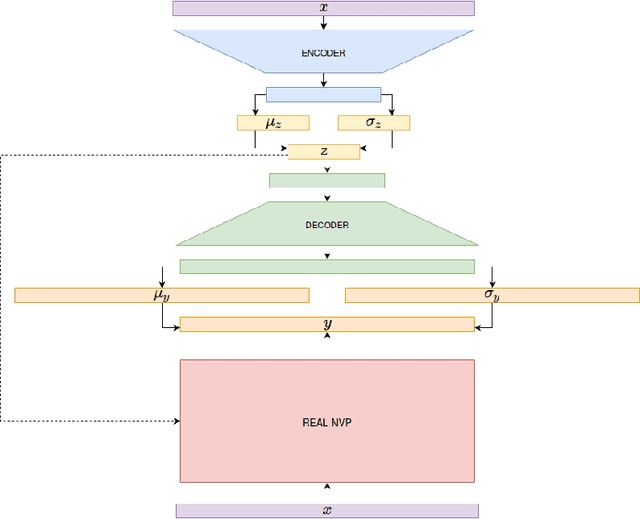
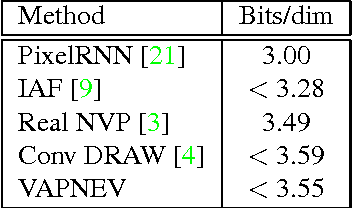
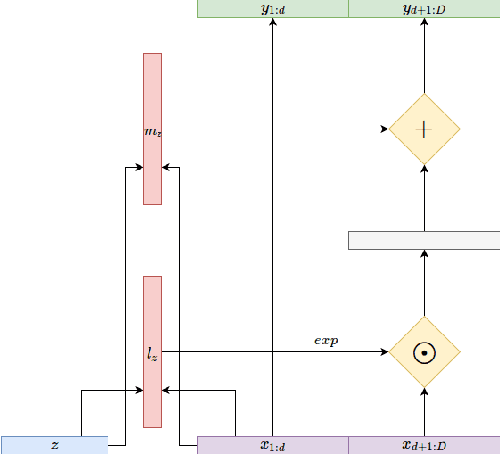
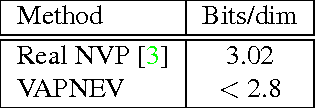
Variational autoencoders (VAEs), that are built upon deep neural networks have emerged as popular generative models in computer vision. Most of the work towards improving variational autoencoders has focused mainly on making the approximations to the posterior flexible and accurate, leading to tremendous progress. However, there have been limited efforts to replace pixel-wise reconstruction, which have known shortcomings. In this work, we use real-valued non-volume preserving transformations (real NVP) to exactly compute the conditional likelihood of the data given the latent distribution. We show that a simple VAE with this form of reconstruction is competitive with complicated VAE structures, on image modeling tasks. As part of our model, we develop powerful conditional coupling layers that enable real NVP to learn with fewer intermediate layers.