 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactored Levenberg-Marquardt for Diffeomorphic Image Registration: An efficient optimizer for FireANTs
Mar 19, 2026FireANTs introduced a novel Eulerian descent method for plug-and-play behavior with arbitrary optimizers adapted for diffeomorphic image registration as a test-time optimization problem, with a GPU-accelerated implementation. FireANTs uses Adam as its default optimizer for fast and more robust optimization. However, Adam requires storing state variables (i.e. momentum and squared-momentum estimates), each of which can consume significant memory, prohibiting its use for significantly large images. In this work, we propose a modified Levenberg-Marquardt (LM) optimizer that requires only a single scalar damping parameter as optimizer state, that is adaptively tuned using a trust region approach. The resulting optimizer reduces memory by up to 24.6% for large volumes, and retaining performance across all four datasets. A single hyperparameter configuration tuned on brain MRI transfers without modification to lung CT and cross-modal abdominal registration, matching or outperforming Adam on three of four benchmarks. We also perform ablations on the effectiveness of using Metropolis-Hastings style rejection step to prevent updates that worsen the loss function.
The LUMirage: An independent evaluation of zero-shot performance in the LUMIR challenge
Dec 17, 2025The LUMIR challenge represents an important benchmark for evaluating deformable image registration methods on large-scale neuroimaging data. While the challenge demonstrates that modern deep learning methods achieve competitive accuracy on T1-weighted MRI, it also claims exceptional zero-shot generalization to unseen contrasts and resolutions, assertions that contradict established understanding of domain shift in deep learning. In this paper, we perform an independent re-evaluation of these zero-shot claims using rigorous evaluation protocols while addressing potential sources of instrumentation bias. Our findings reveal a more nuanced picture: (1) deep learning methods perform comparably to iterative optimization on in-distribution T1w images and even on human-adjacent species (macaque), demonstrating improved task understanding; (2) however, performance degrades significantly on out-of-distribution contrasts (T2, T2*, FLAIR), with Cohen's d scores ranging from 0.7-1.5, indicating substantial practical impact on downstream clinical workflows; (3) deep learning methods face scalability limitations on high-resolution data, failing to run on 0.6 mm isotropic images, while iterative methods benefit from increased resolution; and (4) deep methods exhibit high sensitivity to preprocessing choices. These results align with the well-established literature on domain shift and suggest that claims of universal zero-shot superiority require careful scrutiny. We advocate for evaluation protocols that reflect practical clinical and research workflows rather than conditions that may inadvertently favor particular method classes.
Development of an isotropic segmentation model for medial temporal lobe subregions on anisotropic MRI atlas using implicit neural representation
Aug 24, 2025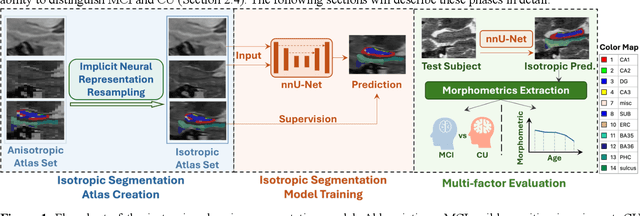

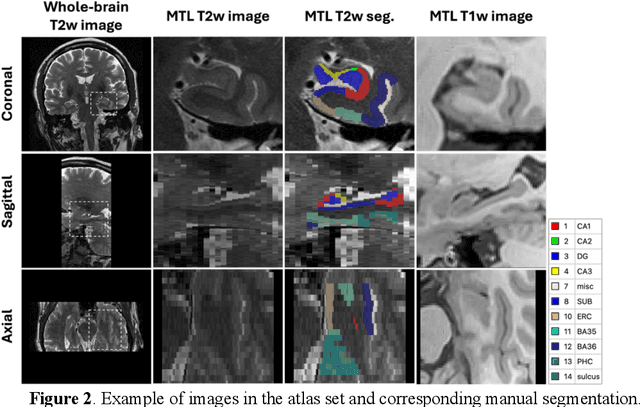
Imaging biomarkers in magnetic resonance imaging (MRI) are important tools for diagnosing and tracking Alzheimer's disease (AD). As medial temporal lobe (MTL) is the earliest region to show AD-related hallmarks, brain atrophy caused by AD can first be observed in the MTL. Accurate segmentation of MTL subregions and extraction of imaging biomarkers from them are important. However, due to imaging limitations, the resolution of T2-weighted (T2w) MRI is anisotropic, which makes it difficult to accurately extract the thickness of cortical subregions in the MTL. In this study, we used an implicit neural representation method to combine the resolution advantages of T1-weighted and T2w MRI to accurately upsample an MTL subregion atlas set from anisotropic space to isotropic space, establishing a multi-modality, high-resolution atlas set. Based on this atlas, we developed an isotropic MTL subregion segmentation model. In an independent test set, the cortical subregion thickness extracted using this isotropic model showed higher significance than an anisotropic method in distinguishing between participants with mild cognitive impairment and cognitively unimpaired (CU) participants. In longitudinal analysis, the biomarkers extracted using isotropic method showed greater stability in CU participants. This study improved the accuracy of AD imaging biomarkers without increasing the amount of atlas annotation work, which may help to more accurately quantify the relationship between AD and brain atrophy and provide more accurate measures for disease tracking.
Elucidating Optimal Reward-Diversity Tradeoffs in Text-to-Image Diffusion Models
Sep 09, 2024Text-to-image (T2I) diffusion models have become prominent tools for generating high-fidelity images from text prompts. However, when trained on unfiltered internet data, these models can produce unsafe, incorrect, or stylistically undesirable images that are not aligned with human preferences. To address this, recent approaches have incorporated human preference datasets to fine-tune T2I models or to optimize reward functions that capture these preferences. Although effective, these methods are vulnerable to reward hacking, where the model overfits to the reward function, leading to a loss of diversity in the generated images. In this paper, we prove the inevitability of reward hacking and study natural regularization techniques like KL divergence and LoRA scaling, and their limitations for diffusion models. We also introduce Annealed Importance Guidance (AIG), an inference-time regularization inspired by Annealed Importance Sampling, which retains the diversity of the base model while achieving Pareto-Optimal reward-diversity tradeoffs. Our experiments demonstrate the benefits of AIG for Stable Diffusion models, striking the optimal balance between reward optimization and image diversity. Furthermore, a user study confirms that AIG improves diversity and quality of generated images across different model architectures and reward functions.
Deep Implicit Optimization for Robust and Flexible Image Registration
Jun 11, 2024



Deep Learning in Image Registration (DLIR) methods have been tremendously successful in image registration due to their speed and ability to incorporate weak label supervision at training time. However, DLIR methods forego many of the benefits of classical optimization-based methods. The functional nature of deep networks do not guarantee that the predicted transformation is a local minima of the registration objective, the representation of the transformation (displacement/velocity field/affine) is fixed, and the networks are not robust to domain shift. Our method aims to bridge this gap between classical and learning methods by incorporating optimization as a layer in a deep network. A deep network is trained to predict multi-scale dense feature images that are registered using a black box iterative optimization solver. This optimal warp is then used to minimize image and label alignment errors. By implicitly differentiating end-to-end through an iterative optimization solver, our learned features are registration and label-aware, and the warp functions are guaranteed to be local minima of the registration objective in the feature space. Our framework shows excellent performance on in-domain datasets, and is agnostic to domain shift such as anisotropy and varying intensity profiles. For the first time, our method allows switching between arbitrary transformation representations (free-form to diffeomorphic) at test time with zero retraining. End-to-end feature learning also facilitates interpretability of features, and out-of-the-box promptability using additional label-fidelity terms at inference.
Neural Ordinary Differential Equation based Sequential Image Registration for Dynamic Characterization
Apr 02, 2024



Deformable image registration (DIR) is crucial in medical image analysis, enabling the exploration of biological dynamics such as organ motions and longitudinal changes in imaging. Leveraging Neural Ordinary Differential Equations (ODE) for registration, this extension work discusses how this framework can aid in the characterization of sequential biological processes. Utilizing the Neural ODE's ability to model state derivatives with neural networks, our Neural Ordinary Differential Equation Optimization-based (NODEO) framework considers voxels as particles within a dynamic system, defining deformation fields through the integration of neural differential equations. This method learns dynamics directly from data, bypassing the need for physical priors, making it exceptionally suitable for medical scenarios where such priors are unavailable or inapplicable. Consequently, the framework can discern underlying dynamics and use sequence data to regularize the transformation trajectory. We evaluated our framework on two clinical datasets: one for cardiac motion tracking and another for longitudinal brain MRI analysis. Demonstrating its efficacy in both 2D and 3D imaging scenarios, our framework offers flexibility and model agnosticism, capable of managing image sequences and facilitating label propagation throughout these sequences. This study provides a comprehensive understanding of how the Neural ODE-based framework uniquely benefits the image registration challenge.
FireANTs: Adaptive Riemannian Optimization for Multi-Scale Diffeomorphic Registration
Apr 01, 2024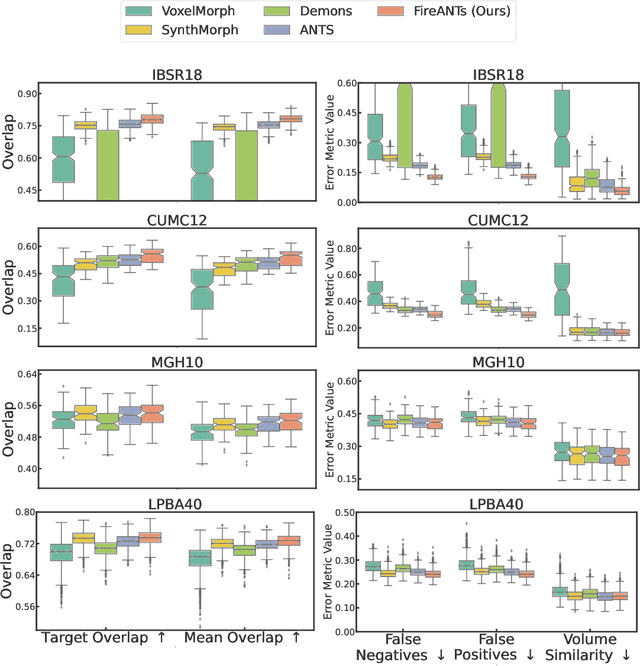
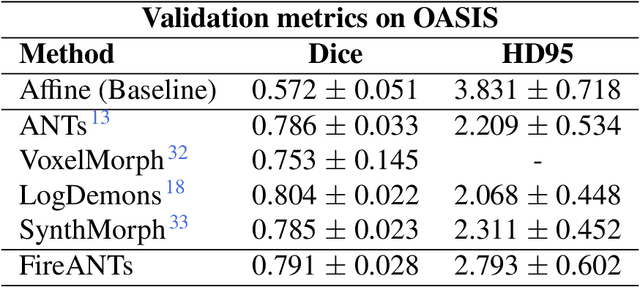
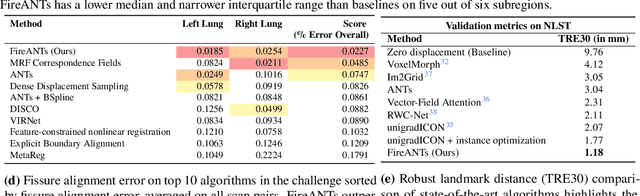

Diffeomorphic Image Registration is a critical part of the analysis in various imaging modalities and downstream tasks like image translation, segmentation, and atlas building. Registration algorithms based on optimization have stood the test of time in terms of accuracy, reliability, and robustness across a wide spectrum of modalities and acquisition settings. However, these algorithms converge slowly, are prohibitively expensive to run, and their usage requires a steep learning curve, limiting their scalability to larger clinical and scientific studies. In this paper, we develop multi-scale Adaptive Riemannian Optimization algorithms for diffeomorphic image registration. We demonstrate compelling improvements on image registration across a spectrum of modalities and anatomies by measuring structural and landmark overlap of the registered image volumes. Our proposed framework leads to a consistent improvement in performance, and from 300x up to 2000x speedup over existing algorithms. Our modular library design makes it easy to use and allows customization via user-defined cost functions.
Towards Establishing Dense Correspondence on Multiview Coronary Angiography: From Point-to-Point to Curve-to-Curve Query Matching
Dec 18, 2023Coronary angiography is the gold standard imaging technique for studying and diagnosing coronary artery disease. However, the resulting 2D X-ray projections lose 3D information and exhibit visual ambiguities. In this work, we aim to establish dense correspondence in multi-view angiography, serving as a fundamental basis for various clinical applications and downstream tasks. To overcome the challenge of unavailable annotated data, we designed a data simulation pipeline using 3D Coronary Computed Tomography Angiography (CCTA). We formulated the problem of dense correspondence estimation as a query matching task over all points of interest in the given views. We established point-to-point query matching and advanced it to curve-to-curve correspondence, significantly reducing errors by minimizing ambiguity and improving topological awareness. The method was evaluated on a set of 1260 image pairs from different views across 8 clinically relevant angulation groups, demonstrating compelling results and indicating the feasibility of establishing dense correspondence in multi-view angiography.
SplatArmor: Articulated Gaussian splatting for animatable humans from monocular RGB videos
Nov 17, 2023



We propose SplatArmor, a novel approach for recovering detailed and animatable human models by `armoring' a parameterized body model with 3D Gaussians. Our approach represents the human as a set of 3D Gaussians within a canonical space, whose articulation is defined by extending the skinning of the underlying SMPL geometry to arbitrary locations in the canonical space. To account for pose-dependent effects, we introduce a SE(3) field, which allows us to capture both the location and anisotropy of the Gaussians. Furthermore, we propose the use of a neural color field to provide color regularization and 3D supervision for the precise positioning of these Gaussians. We show that Gaussian splatting provides an interesting alternative to neural rendering based methods by leverging a rasterization primitive without facing any of the non-differentiability and optimization challenges typically faced in such approaches. The rasterization paradigms allows us to leverage forward skinning, and does not suffer from the ambiguities associated with inverse skinning and warping. We show compelling results on the ZJU MoCap and People Snapshot datasets, which underscore the effectiveness of our method for controllable human synthesis.
Mesh Strikes Back: Fast and Efficient Human Reconstruction from RGB videos
Mar 15, 2023Human reconstruction and synthesis from monocular RGB videos is a challenging problem due to clothing, occlusion, texture discontinuities and sharpness, and framespecific pose changes. Many methods employ deferred rendering, NeRFs and implicit methods to represent clothed humans, on the premise that mesh-based representations cannot capture complex clothing and textures from RGB, silhouettes, and keypoints alone. We provide a counter viewpoint to this fundamental premise by optimizing a SMPL+D mesh and an efficient, multi-resolution texture representation using only RGB images, binary silhouettes and sparse 2D keypoints. Experimental results demonstrate that our approach is more capable of capturing geometric details compared to visual hull, mesh-based methods. We show competitive novel view synthesis and improvements in novel pose synthesis compared to NeRF-based methods, which introduce noticeable, unwanted artifacts. By restricting the solution space to the SMPL+D model combined with differentiable rendering, we obtain dramatic speedups in compute, training times (up to 24x) and inference times (up to 192x). Our method therefore can be used as is or as a fast initialization to NeRF-based methods.