 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMesh Strikes Back: Fast and Efficient Human Reconstruction from RGB videos
Mar 15, 2023Human reconstruction and synthesis from monocular RGB videos is a challenging problem due to clothing, occlusion, texture discontinuities and sharpness, and framespecific pose changes. Many methods employ deferred rendering, NeRFs and implicit methods to represent clothed humans, on the premise that mesh-based representations cannot capture complex clothing and textures from RGB, silhouettes, and keypoints alone. We provide a counter viewpoint to this fundamental premise by optimizing a SMPL+D mesh and an efficient, multi-resolution texture representation using only RGB images, binary silhouettes and sparse 2D keypoints. Experimental results demonstrate that our approach is more capable of capturing geometric details compared to visual hull, mesh-based methods. We show competitive novel view synthesis and improvements in novel pose synthesis compared to NeRF-based methods, which introduce noticeable, unwanted artifacts. By restricting the solution space to the SMPL+D model combined with differentiable rendering, we obtain dramatic speedups in compute, training times (up to 24x) and inference times (up to 192x). Our method therefore can be used as is or as a fast initialization to NeRF-based methods.
Differential Scene Flow from Light Field Gradients
Jul 29, 2019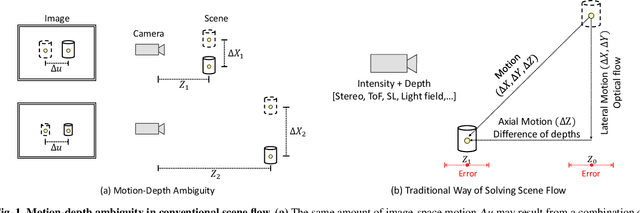
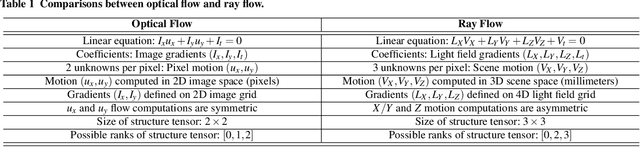

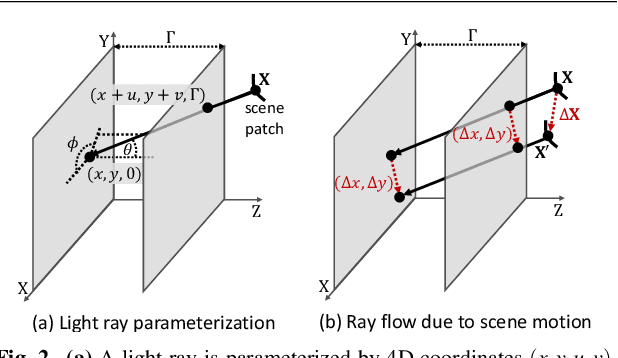
This paper presents novel techniques for recovering 3D dense scene flow, based on differential analysis of 4D light fields. The key enabling result is a per-ray linear equation, called the ray flow equation, that relates 3D scene flow to 4D light field gradients. The ray flow equation is invariant to 3D scene structure and applicable to a general class of scenes, but is under-constrained (3 unknowns per equation). Thus, additional constraints must be imposed to recover motion. We develop two families of scene flow algorithms by leveraging the structural similarity between ray flow and optical flow equations: local 'Lucas-Kanade' ray flow and global 'Horn-Schunck' ray flow, inspired by corresponding optical flow methods. We also develop a combined local-global method by utilizing the correspondence structure in the light fields. We demonstrate high precision 3D scene flow recovery for a wide range of scenarios, including rotation and non-rigid motion. We analyze the theoretical and practical performance limits of the proposed techniques via the light field structure tensor, a 3x3 matrix that encodes the local structure of light fields. We envision that the proposed analysis and algorithms will lead to design of future light-field cameras that are optimized for motion sensing, in addition to depth sensing.
Efficient Branching Cascaded Regression for Face Alignment under Significant Head Rotation
Nov 10, 2016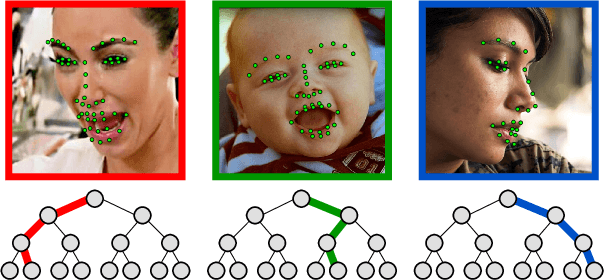
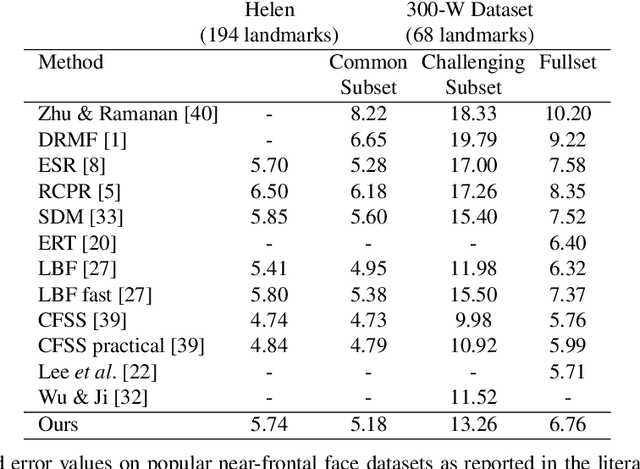


Despite much interest in face alignment in recent years, the large majority of work has focused on near-frontal faces. Algorithms typically break down on profile faces, or are too slow for real-time applications. In this work we propose an efficient approach to face alignment that can handle 180 degrees of head rotation in a unified way (e.g., without resorting to view-based models) using 2D training data. The foundation of our approach is cascaded shape regression (CSR), which has emerged recently as the leading strategy. We propose a generalization of conventional CSRs that we call branching cascaded regression (BCR). Conventional CSRs are single-track; that is, they progress from one cascade level to the next in a straight line, with each regressor attempting to fit the entire dataset. We instead split the regression problem into two or more simpler ones after each cascade level. Intuitively, each regressor can then operate on a simpler objective function (i.e., with fewer conflicting gradient directions). Within the BCR framework, we model and infer pose-related landmark visibility and face shape simultaneously using Structured Point Distribution Models (SPDMs). We propose to learn task-specific feature mapping functions that are adaptive to landmark visibility, and that use SPDM parameters as regression targets instead of 2D landmark coordinates. Additionally, we introduce a new in-the-wild dataset of profile faces to validate our approach.