 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Analysis of Large Language Model Outputs: Similarity, Diversity, and Bias
May 14, 2025Large Language Models (LLMs) represent a major step toward artificial general intelligence, significantly advancing our ability to interact with technology. While LLMs perform well on Natural Language Processing tasks -- such as translation, generation, code writing, and summarization -- questions remain about their output similarity, variability, and ethical implications. For instance, how similar are texts generated by the same model? How does this compare across different models? And which models best uphold ethical standards? To investigate, we used 5{,}000 prompts spanning diverse tasks like generation, explanation, and rewriting. This resulted in approximately 3 million texts from 12 LLMs, including proprietary and open-source systems from OpenAI, Google, Microsoft, Meta, and Mistral. Key findings include: (1) outputs from the same LLM are more similar to each other than to human-written texts; (2) models like WizardLM-2-8x22b generate highly similar outputs, while GPT-4 produces more varied responses; (3) LLM writing styles differ significantly, with Llama 3 and Mistral showing higher similarity, and GPT-4 standing out for distinctiveness; (4) differences in vocabulary and tone underscore the linguistic uniqueness of LLM-generated content; (5) some LLMs demonstrate greater gender balance and reduced bias. These results offer new insights into the behavior and diversity of LLM outputs, helping guide future development and ethical evaluation.
A Physically Driven Long Short Term Memory Model for Estimating Snow Water Equivalent over the Continental United States
Apr 28, 2025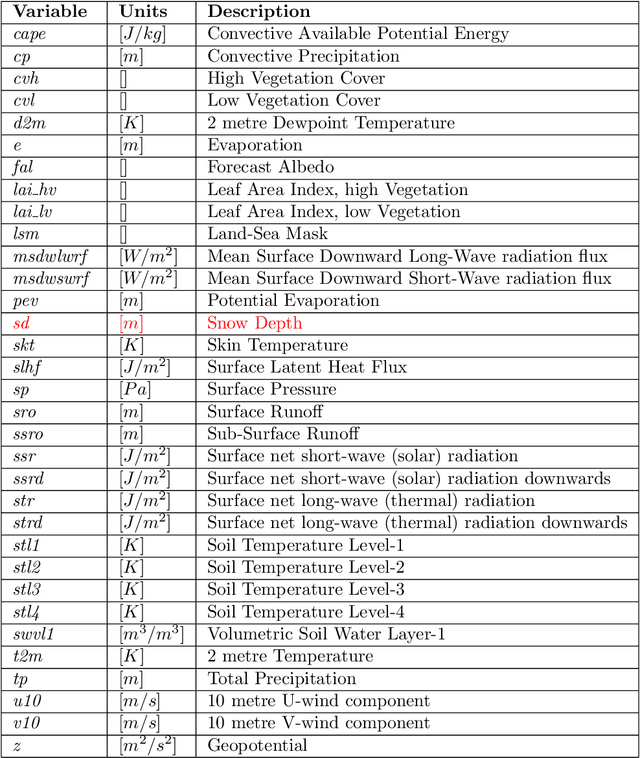
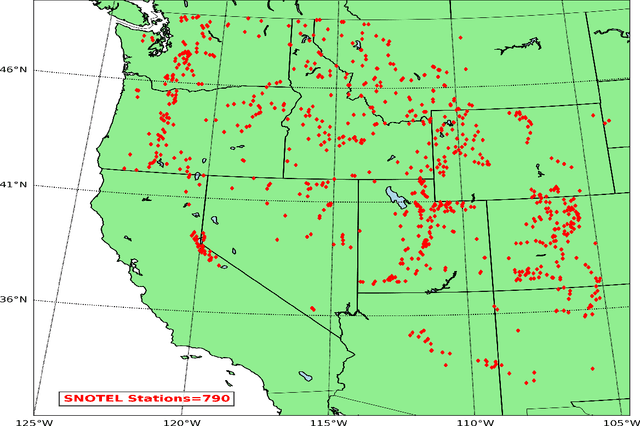
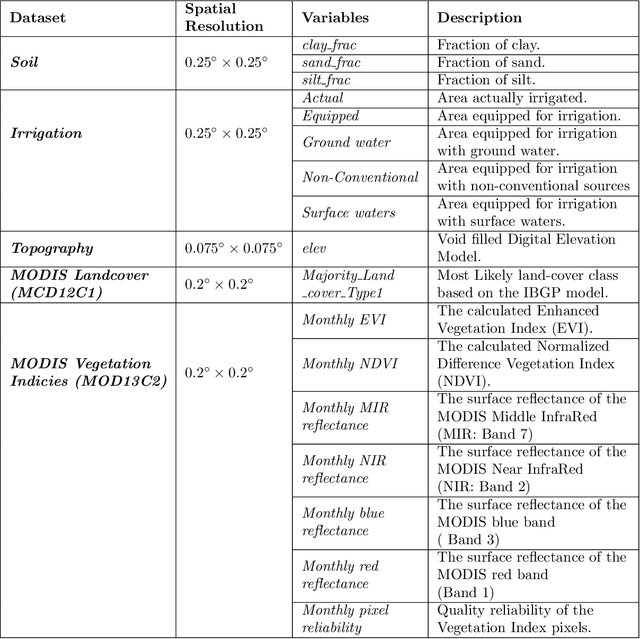
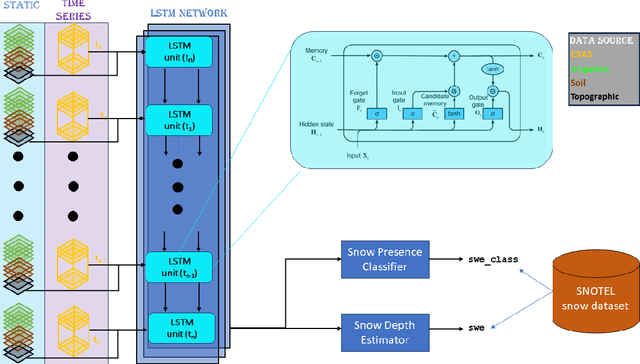
Snow is an essential input for various land surface models. Seasonal snow estimates are available as snow water equivalent (SWE) from process-based reanalysis products or locally from in situ measurements. While the reanalysis products are computationally expensive and available at only fixed spatial and temporal resolutions, the in situ measurements are highly localized and sparse. To address these issues and enable the analysis of the effect of a large suite of physical, morphological, and geological conditions on the presence and amount of snow, we build a Long Short-Term Memory (LSTM) network, which is able to estimate the SWE based on time series input of the various physical/meteorological factors as well static spatial/morphological factors. Specifically, this model breaks down the SWE estimation into two separate tasks: (i) a classification task that indicates the presence/absence of snow on a specific day and (ii) a regression task that indicates the height of the SWE on a specific day in the case of snow presence. The model is trained using physical/in situ SWE measurements from the SNOw TELemetry (SNOTEL) snow pillows in the western United States. We will show that trained LSTM models have a classification accuracy of $\geq 93\%$ for the presence of snow and a coefficient of correlation of $\sim 0.9$ concerning their SWE estimates. We will also demonstrate that the models can generalize both spatially and temporally to previously unseen data.
A Simple Strategy for Body Estimation from Partial-View Images
Apr 16, 2024
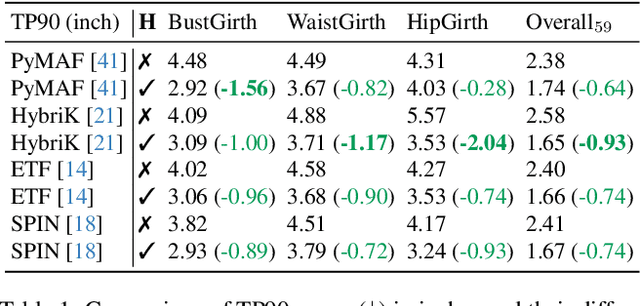
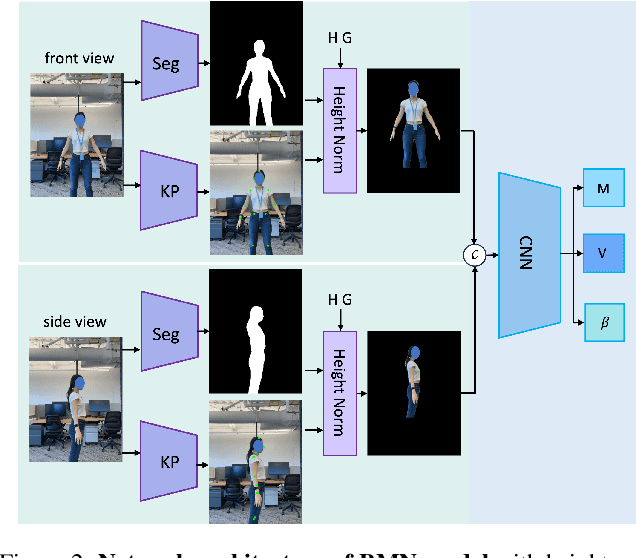
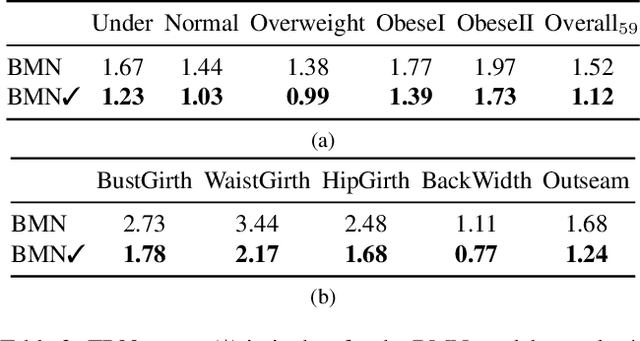
Virtual try-on and product personalization have become increasingly important in modern online shopping, highlighting the need for accurate body measurement estimation. Although previous research has advanced in estimating 3D body shapes from RGB images, the task is inherently ambiguous as the observed scale of human subjects in the images depends on two unknown factors: capture distance and body dimensions. This ambiguity is particularly pronounced in partial-view scenarios. To address this challenge, we propose a modular and simple height normalization solution. This solution relocates the subject skeleton to the desired position, thereby normalizing the scale and disentangling the relationship between the two variables. Our experimental results demonstrate that integrating this technique into state-of-the-art human mesh reconstruction models significantly enhances partial body measurement estimation. Additionally, we illustrate the applicability of this approach to multi-view settings, showcasing its versatility.
SplatArmor: Articulated Gaussian splatting for animatable humans from monocular RGB videos
Nov 17, 2023



We propose SplatArmor, a novel approach for recovering detailed and animatable human models by `armoring' a parameterized body model with 3D Gaussians. Our approach represents the human as a set of 3D Gaussians within a canonical space, whose articulation is defined by extending the skinning of the underlying SMPL geometry to arbitrary locations in the canonical space. To account for pose-dependent effects, we introduce a SE(3) field, which allows us to capture both the location and anisotropy of the Gaussians. Furthermore, we propose the use of a neural color field to provide color regularization and 3D supervision for the precise positioning of these Gaussians. We show that Gaussian splatting provides an interesting alternative to neural rendering based methods by leverging a rasterization primitive without facing any of the non-differentiability and optimization challenges typically faced in such approaches. The rasterization paradigms allows us to leverage forward skinning, and does not suffer from the ambiguities associated with inverse skinning and warping. We show compelling results on the ZJU MoCap and People Snapshot datasets, which underscore the effectiveness of our method for controllable human synthesis.
Balancing the Picture: Debiasing Vision-Language Datasets with Synthetic Contrast Sets
May 24, 2023Vision-language models are growing in popularity and public visibility to generate, edit, and caption images at scale; but their outputs can perpetuate and amplify societal biases learned during pre-training on uncurated image-text pairs from the internet. Although debiasing methods have been proposed, we argue that these measurements of model bias lack validity due to dataset bias. We demonstrate there are spurious correlations in COCO Captions, the most commonly used dataset for evaluating bias, between background context and the gender of people in-situ. This is problematic because commonly-used bias metrics (such as Bias@K) rely on per-gender base rates. To address this issue, we propose a novel dataset debiasing pipeline to augment the COCO dataset with synthetic, gender-balanced contrast sets, where only the gender of the subject is edited and the background is fixed. However, existing image editing methods have limitations and sometimes produce low-quality images; so, we introduce a method to automatically filter the generated images based on their similarity to real images. Using our balanced synthetic contrast sets, we benchmark bias in multiple CLIP-based models, demonstrating how metrics are skewed by imbalance in the original COCO images. Our results indicate that the proposed approach improves the validity of the evaluation, ultimately contributing to more realistic understanding of bias in vision-language models.
Sequential Ensembling for Semantic Segmentation
Oct 08, 2022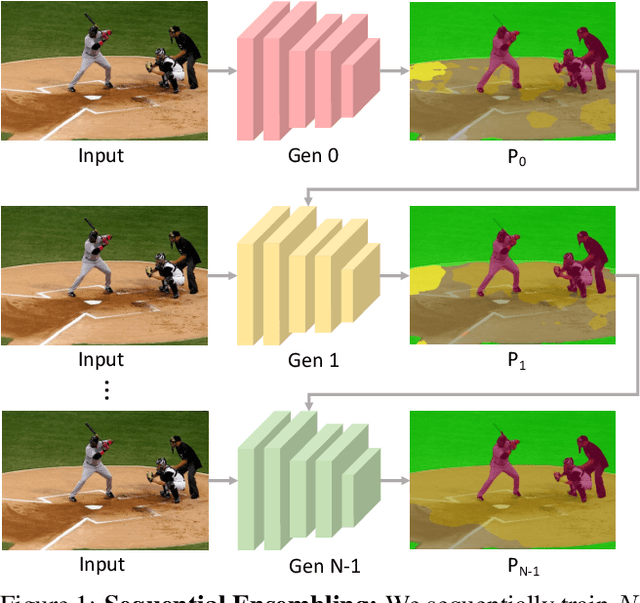
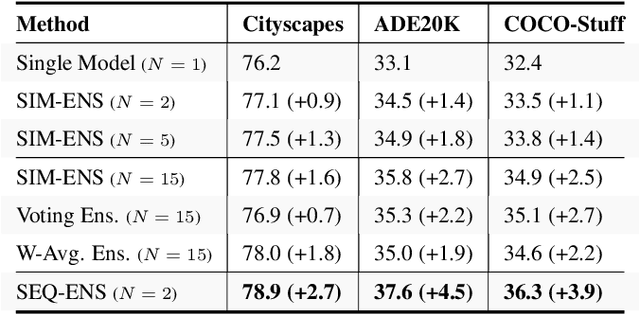
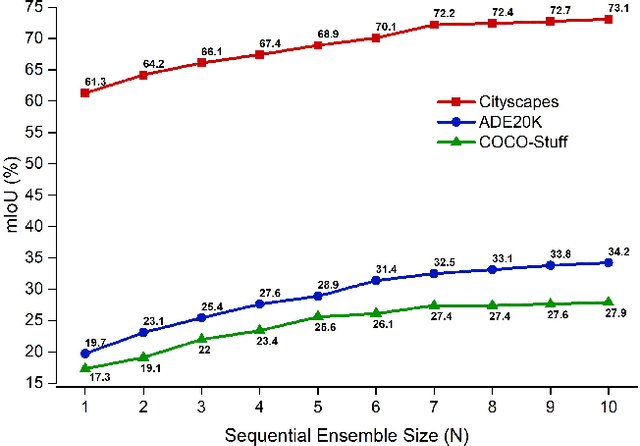
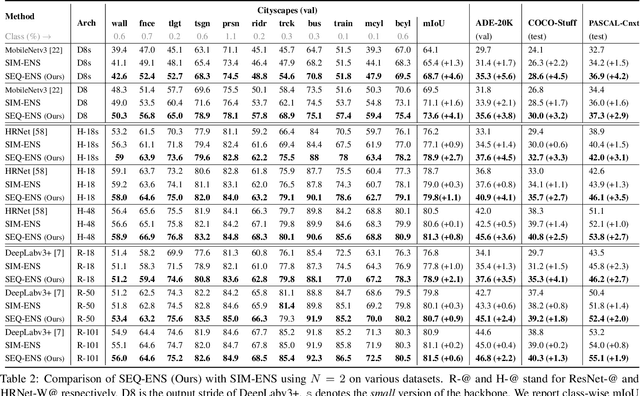
Ensemble approaches for deep-learning-based semantic segmentation remain insufficiently explored despite the proliferation of competitive benchmarks and downstream applications. In this work, we explore and benchmark the popular ensembling approach of combining predictions of multiple, independently-trained, state-of-the-art models at test time on popular datasets. Furthermore, we propose a novel method inspired by boosting to sequentially ensemble networks that significantly outperforms the naive ensemble baseline. Our approach trains a cascade of models conditioned on class probabilities predicted by the previous model as an additional input. A key benefit of this approach is that it allows for dynamic computation offloading, which helps deploy models on mobile devices. Our proposed novel ADaptive modulatiON (ADON) block allows spatial feature modulation at various layers using previous-stage probabilities. Our approach does not require sophisticated sample selection strategies during training and works with multiple neural architectures. We significantly improve over the naive ensemble baseline on challenging datasets such as Cityscapes, ADE-20K, COCO-Stuff, and PASCAL-Context and set a new state-of-the-art.
Auditing Black-box Models for Indirect Influence
Nov 30, 2016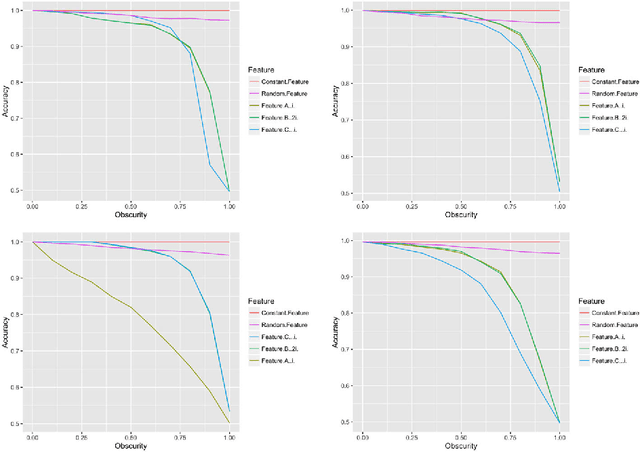
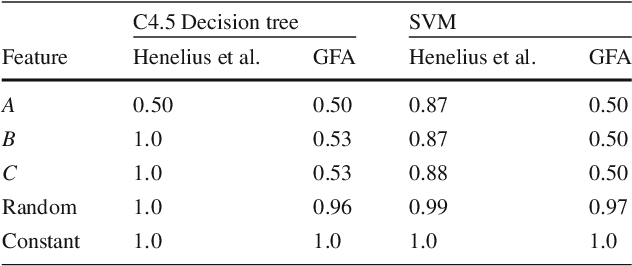
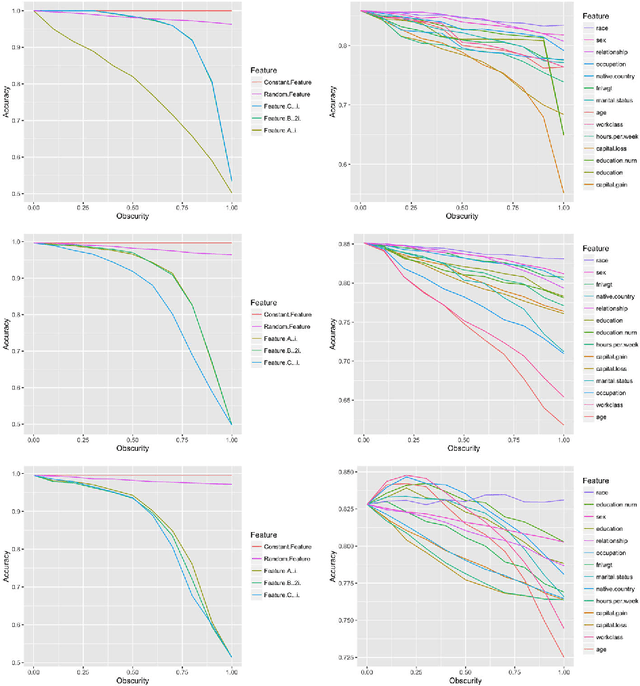
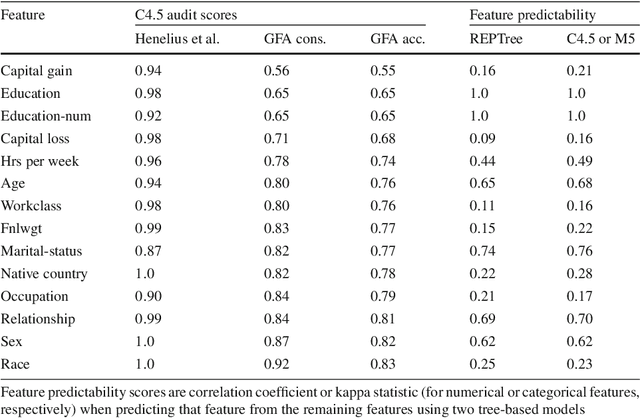
Data-trained predictive models see widespread use, but for the most part they are used as black boxes which output a prediction or score. It is therefore hard to acquire a deeper understanding of model behavior, and in particular how different features influence the model prediction. This is important when interpreting the behavior of complex models, or asserting that certain problematic attributes (like race or gender) are not unduly influencing decisions. In this paper, we present a technique for auditing black-box models, which lets us study the extent to which existing models take advantage of particular features in the dataset, without knowing how the models work. Our work focuses on the problem of indirect influence: how some features might indirectly influence outcomes via other, related features. As a result, we can find attribute influences even in cases where, upon further direct examination of the model, the attribute is not referred to by the model at all. Our approach does not require the black-box model to be retrained. This is important if (for example) the model is only accessible via an API, and contrasts our work with other methods that investigate feature influence like feature selection. We present experimental evidence for the effectiveness of our procedure using a variety of publicly available datasets and models. We also validate our procedure using techniques from interpretable learning and feature selection, as well as against other black-box auditing procedures.