 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Ensembling for Semantic Segmentation
Oct 08, 2022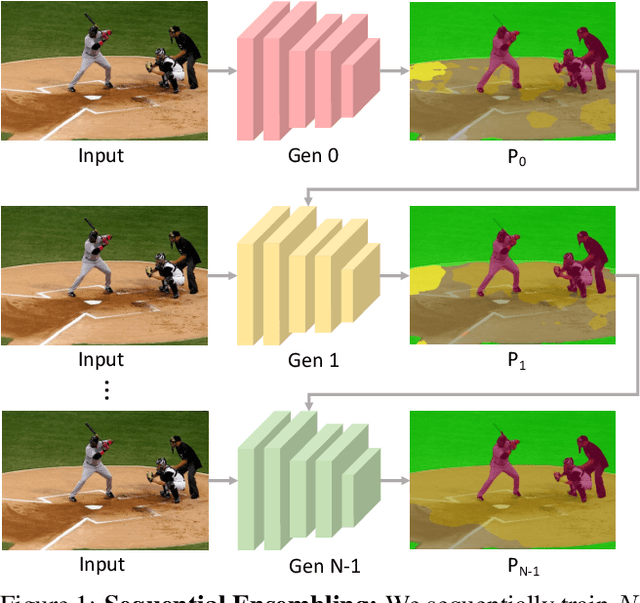
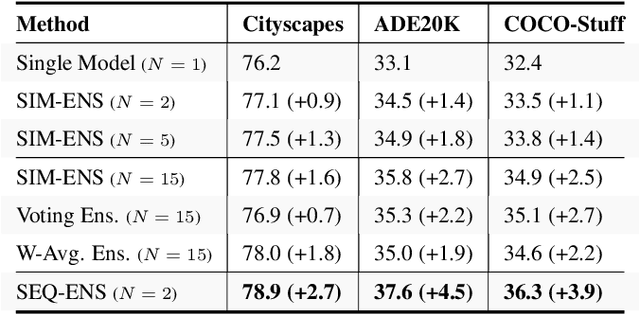
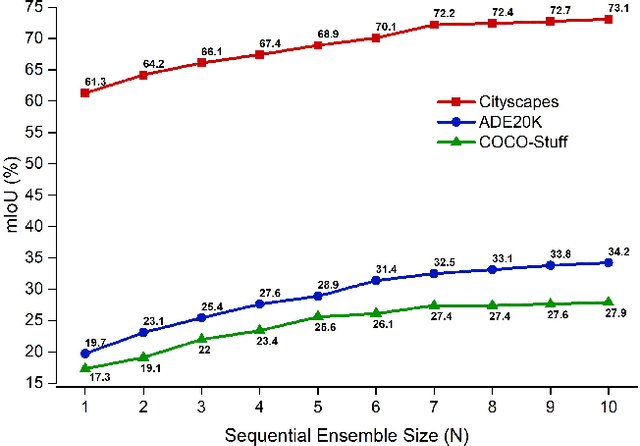
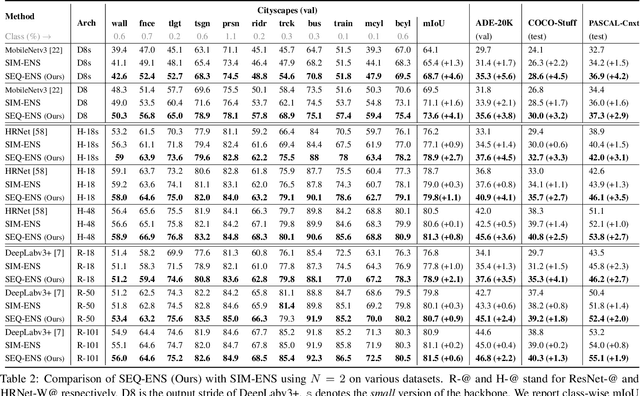
Ensemble approaches for deep-learning-based semantic segmentation remain insufficiently explored despite the proliferation of competitive benchmarks and downstream applications. In this work, we explore and benchmark the popular ensembling approach of combining predictions of multiple, independently-trained, state-of-the-art models at test time on popular datasets. Furthermore, we propose a novel method inspired by boosting to sequentially ensemble networks that significantly outperforms the naive ensemble baseline. Our approach trains a cascade of models conditioned on class probabilities predicted by the previous model as an additional input. A key benefit of this approach is that it allows for dynamic computation offloading, which helps deploy models on mobile devices. Our proposed novel ADaptive modulatiON (ADON) block allows spatial feature modulation at various layers using previous-stage probabilities. Our approach does not require sophisticated sample selection strategies during training and works with multiple neural architectures. We significantly improve over the naive ensemble baseline on challenging datasets such as Cityscapes, ADE-20K, COCO-Stuff, and PASCAL-Context and set a new state-of-the-art.
Learning to Generate Synthetic Data via Compositing
Apr 10, 2019

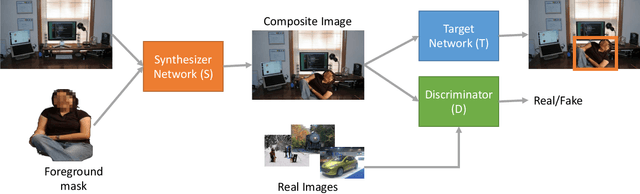
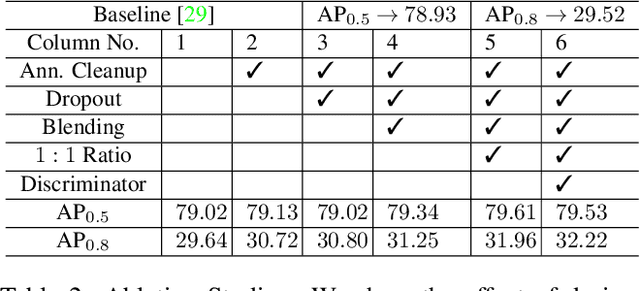
We present a task-aware approach to synthetic data generation. Our framework employs a trainable synthesizer network that is optimized to produce meaningful training samples by assessing the strengths and weaknesses of a `target' network. The synthesizer and target networks are trained in an adversarial manner wherein each network is updated with a goal to outdo the other. Additionally, we ensure the synthesizer generates realistic data by pairing it with a discriminator trained on real-world images. Further, to make the target classifier invariant to blending artefacts, we introduce these artefacts to background regions of the training images so the target does not over-fit to them. We demonstrate the efficacy of our approach by applying it to different target networks including a classification network on AffNIST, and two object detection networks (SSD, Faster-RCNN) on different datasets. On the AffNIST benchmark, our approach is able to surpass the baseline results with just half the training examples. On the VOC person detection benchmark, we show improvements of up to 2.7% as a result of our data augmentation. Similarly on the GMU detection benchmark, we report a performance boost of 3.5% in mAP over the baseline method, outperforming the previous state of the art approaches by up to 7.5% on specific categories.
Deep Spatio-Temporal Random Fields for Efficient Video Segmentation
Jul 03, 2018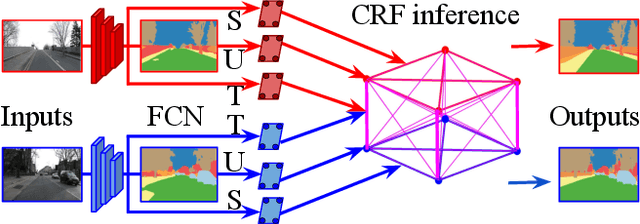
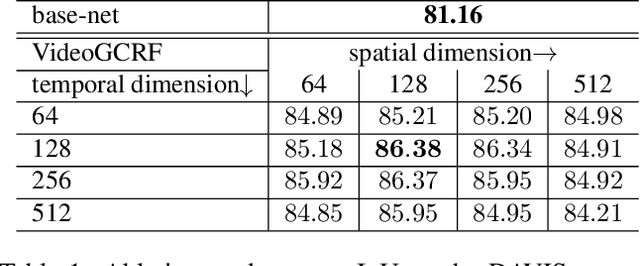
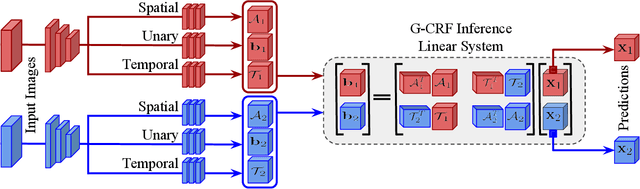
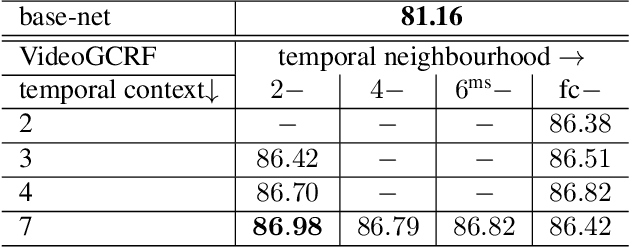
In this work we introduce a time- and memory-efficient method for structured prediction that couples neuron decisions across both space at time. We show that we are able to perform exact and efficient inference on a densely connected spatio-temporal graph by capitalizing on recent advances on deep Gaussian Conditional Random Fields (GCRFs). Our method, called VideoGCRF is (a) efficient, (b) has a unique global minimum, and (c) can be trained end-to-end alongside contemporary deep networks for video understanding. We experiment with multiple connectivity patterns in the temporal domain, and present empirical improvements over strong baselines on the tasks of both semantic and instance segmentation of videos.
Fast, Exact and Multi-Scale Inference for Semantic Image Segmentation with Deep Gaussian CRFs
Nov 29, 2016

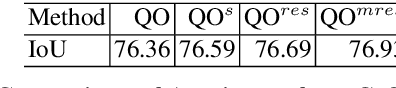

In this work we propose a structured prediction technique that combines the virtues of Gaussian Conditional Random Fields (G-CRF) with Deep Learning: (a) our structured prediction task has a unique global optimum that is obtained exactly from the solution of a linear system (b) the gradients of our model parameters are analytically computed using closed form expressions, in contrast to the memory-demanding contemporary deep structured prediction approaches that rely on back-propagation-through-time, (c) our pairwise terms do not have to be simple hand-crafted expressions, as in the line of works building on the DenseCRF, but can rather be `discovered' from data through deep architectures, and (d) out system can trained in an end-to-end manner. Building on standard tools from numerical analysis we develop very efficient algorithms for inference and learning, as well as a customized technique adapted to the semantic segmentation task. This efficiency allows us to explore more sophisticated architectures for structured prediction in deep learning: we introduce multi-resolution architectures to couple information across scales in a joint optimization framework, yielding systematic improvements. We demonstrate the utility of our approach on the challenging VOC PASCAL 2012 image segmentation benchmark, showing substantial improvements over strong baselines. We make all of our code and experiments available at {https://github.com/siddharthachandra/gcrf}
Deep, Dense, and Low-Rank Gaussian Conditional Random Fields
Nov 28, 2016


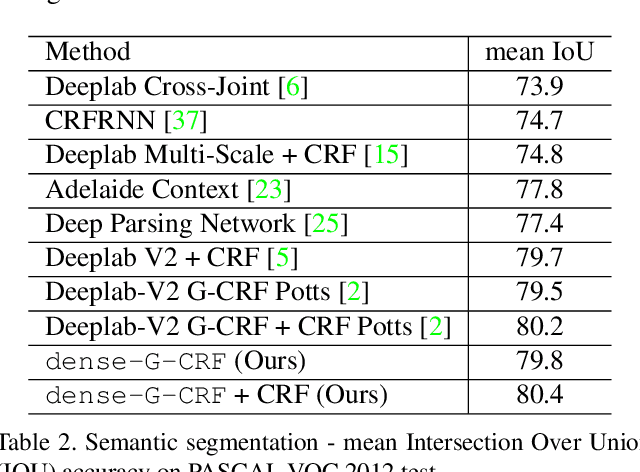
In this work we introduce a fully-connected graph structure in the Deep Gaussian Conditional Random Field (G-CRF) model. For this we express the pairwise interactions between pixels as the inner-products of low-dimensional embeddings, delivered by a new subnetwork of a deep architecture. We efficiently minimize the resulting energy by solving the resulting low-rank linear system with conjugate gradients, and derive an analytic expression for the gradient of our embeddings which allows us to train them end-to-end with backpropagation. We demonstrate the merit of our approach by achieving state of the art results on three challenging Computer Vision benchmarks, namely semantic segmentation, human parts segmentation, and saliency estimation. Our implementation is fully GPU based, built on top of the Caffe library, and will be made publicly available.