 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVolumetric Cloud Field Reconstruction
Nov 29, 2023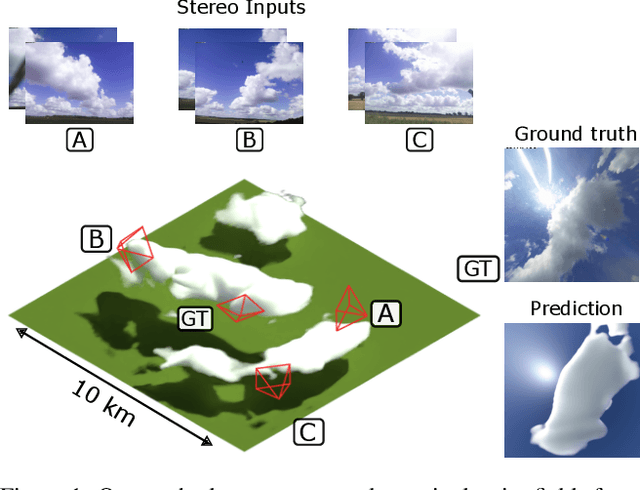
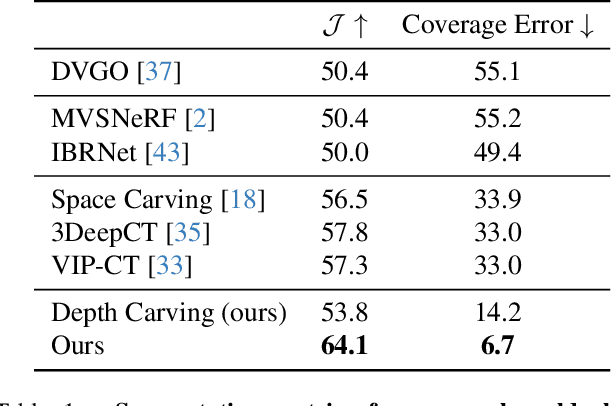
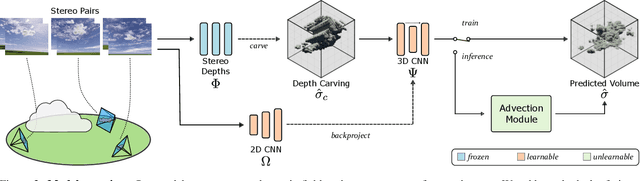
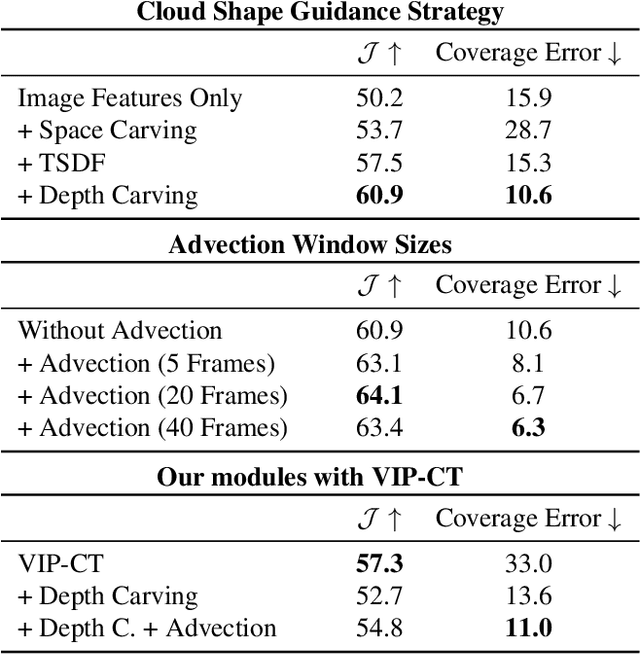
Volumetric phenomena, such as clouds and fog, present a significant challenge for 3D reconstruction systems due to their translucent nature and their complex interactions with light. Conventional techniques for reconstructing scattering volumes rely on controlled setups, limiting practical applications. This paper introduces an approach to reconstructing volumes from a few input stereo pairs. We propose a novel deep learning framework that integrates a deep stereo model with a 3D Convolutional Neural Network (3D CNN) and an advection module, capable of capturing the shape and dynamics of volumes. The stereo depths are used to carve empty space around volumes, providing the 3D CNN with a prior for coping with the lack of input views. Refining our output, the advection module leverages the temporal evolution of the medium, providing a mechanism to infer motion and improve temporal consistency. The efficacy of our system is demonstrated through its ability to estimate density and velocity fields of large-scale volumes, in this case, clouds, from a sparse set of stereo image pairs.
Balancing the Picture: Debiasing Vision-Language Datasets with Synthetic Contrast Sets
May 24, 2023Vision-language models are growing in popularity and public visibility to generate, edit, and caption images at scale; but their outputs can perpetuate and amplify societal biases learned during pre-training on uncurated image-text pairs from the internet. Although debiasing methods have been proposed, we argue that these measurements of model bias lack validity due to dataset bias. We demonstrate there are spurious correlations in COCO Captions, the most commonly used dataset for evaluating bias, between background context and the gender of people in-situ. This is problematic because commonly-used bias metrics (such as Bias@K) rely on per-gender base rates. To address this issue, we propose a novel dataset debiasing pipeline to augment the COCO dataset with synthetic, gender-balanced contrast sets, where only the gender of the subject is edited and the background is fixed. However, existing image editing methods have limitations and sometimes produce low-quality images; so, we introduce a method to automatically filter the generated images based on their similarity to real images. Using our balanced synthetic contrast sets, we benchmark bias in multiple CLIP-based models, demonstrating how metrics are skewed by imbalance in the original COCO images. Our results indicate that the proposed approach improves the validity of the evaluation, ultimately contributing to more realistic understanding of bias in vision-language models.