 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanCritic: Formal Planning with Human Feedback
Nov 30, 2024Real world planning problems are often too complex to be effectively tackled by a single unaided human. To alleviate this, some recent work has focused on developing a collaborative planning system to assist humans in complex domains, with bridging the gap between the system's problem representation and the real world being a key consideration. Transferring the speed and correctness formal planners provide to real-world planning problems is greatly complicated by the dynamic and online nature of such tasks. Formal specifications of task and environment dynamics frequently lack constraints on some behaviors or goal conditions relevant to the way a human operator prefers a plan to be carried out. While adding constraints to the representation with the objective of increasing its realism risks slowing down the planner, we posit that the same benefits can be realized without sacrificing speed by modeling this problem as an online preference learning task. As part of a broader cooperative planning system, we present a feedback-driven plan critic. This method makes use of reinforcement learning with human feedback in conjunction with a genetic algorithm to directly optimize a plan with respect to natural-language user preferences despite the non-differentiability of traditional planners. Directly optimizing the plan bridges the gap between research into more efficient planners and research into planning with language models by utilizing the convenience of natural language to guide the output of formal planners. We demonstrate the effectiveness of our plan critic at adhering to user preferences on a disaster recovery task, and observe improved performance compared to an llm-only neurosymbolic approach.
CBGT-Net: A Neuromimetic Architecture for Robust Classification of Streaming Data
Mar 24, 2024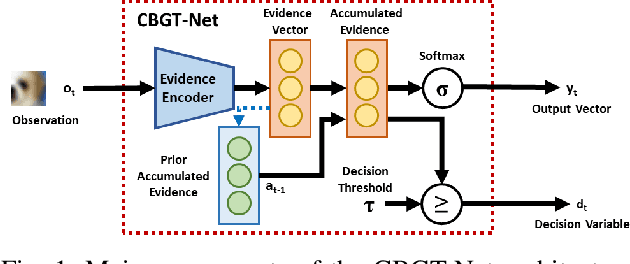
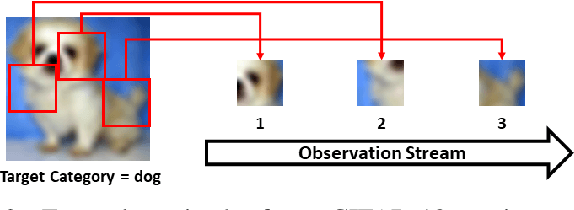
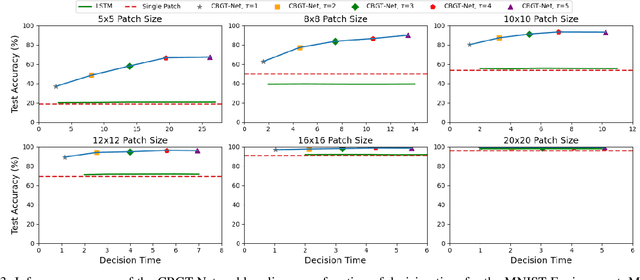
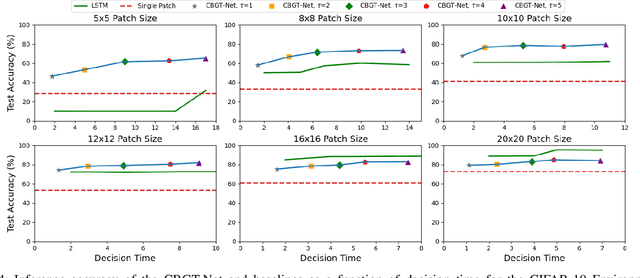
This paper describes CBGT-Net, a neural network model inspired by the cortico-basal ganglia-thalamic (CBGT) circuits found in mammalian brains. Unlike traditional neural network models, which either generate an output for each provided input, or an output after a fixed sequence of inputs, the CBGT-Net learns to produce an output after a sufficient criteria for evidence is achieved from a stream of observed data. For each observation, the CBGT-Net generates a vector that explicitly represents the amount of evidence the observation provides for each potential decision, accumulates the evidence over time, and generates a decision when the accumulated evidence exceeds a pre-defined threshold. We evaluate the proposed model on two image classification tasks, where models need to predict image categories based on a stream of small patches extracted from the image. We show that the CBGT-Net provides improved accuracy and robustness compared to models trained to classify from a single patch, and models leveraging an LSTM layer to classify from a fixed sequence length of patches.
Theory of Mind for Multi-Agent Collaboration via Large Language Models
Oct 22, 2023



While Large Language Models (LLMs) have demonstrated impressive accomplishments in both reasoning and planning, their abilities in multi-agent collaborations remains largely unexplored. This study evaluates LLM-based agents in a multi-agent cooperative text game with Theory of Mind (ToM) inference tasks, comparing their performance with Multi-Agent Reinforcement Learning (MARL) and planning-based baselines. We observed evidence of emergent collaborative behaviors and high-order Theory of Mind capabilities among LLM-based agents. Our results reveal limitations in LLM-based agents' planning optimization due to systematic failures in managing long-horizon contexts and hallucination about the task state. We explore the use of explicit belief state representations to mitigate these issues, finding that it enhances task performance and the accuracy of ToM inferences for LLM-based agents.
Concept Learning for Interpretable Multi-Agent Reinforcement Learning
Feb 23, 2023



Multi-agent robotic systems are increasingly operating in real-world environments in close proximity to humans, yet are largely controlled by policy models with inscrutable deep neural network representations. We introduce a method for incorporating interpretable concepts from a domain expert into models trained through multi-agent reinforcement learning, by requiring the model to first predict such concepts then utilize them for decision making. This allows an expert to both reason about the resulting concept policy models in terms of these high-level concepts at run-time, as well as intervene and correct mispredictions to improve performance. We show that this yields improved interpretability and training stability, with benefits to policy performance and sample efficiency in a simulated and real-world cooperative-competitive multi-agent game.
Explainable Action Advising for Multi-Agent Reinforcement Learning
Nov 15, 2022



Action advising is a knowledge transfer technique for reinforcement learning based on the teacher-student paradigm. An expert teacher provides advice to a student during training in order to improve the student's sample efficiency and policy performance. Such advice is commonly given in the form of state-action pairs. However, it makes it difficult for the student to reason with and apply to novel states. We introduce Explainable Action Advising, in which the teacher provides action advice as well as associated explanations indicating why the action was chosen. This allows the student to self-reflect on what it has learned, enabling advice generalization and leading to improved sample efficiency and learning performance - even in environments where the teacher is sub-optimal. We empirically show that our framework is effective in both single-agent and multi-agent scenarios, yielding improved policy returns and convergence rates when compared to state-of-the-art methods.
The Enforcers: Consistent Sparse-Discrete Methods for Constraining Informative Emergent Communication
Jan 19, 2022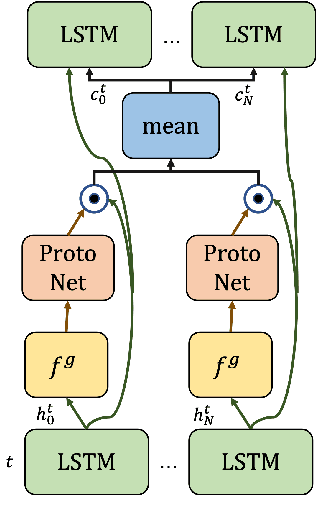
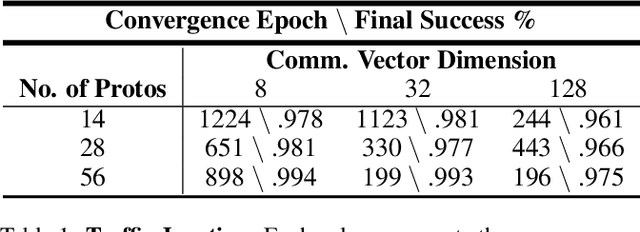
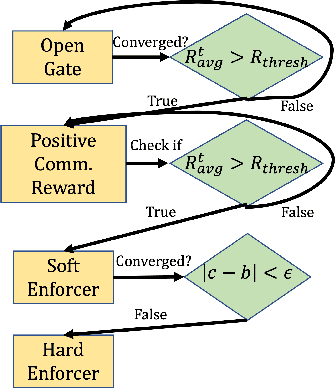
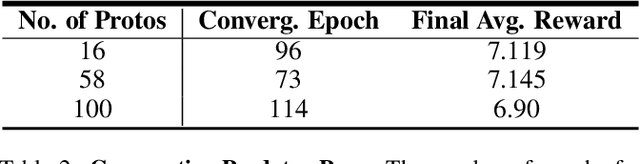
Communication enables agents to cooperate to achieve their goals. Learning when to communicate, i.e. sparse communication, is particularly important where bandwidth is limited, in situations where agents interact with humans, in partially observable scenarios where agents must convey information unavailable to others, and in non-cooperative scenarios where agents may hide information to gain a competitive advantage. Recent work in learning sparse communication, however, suffers from high variance training where, the price of decreasing communication is a decrease in reward, particularly in cooperative tasks. Sparse communications are necessary to match agent communication to limited human bandwidth. Humans additionally communicate via discrete linguistic tokens, previously shown to decrease task performance when compared to continuous communication vectors. This research addresses the above issues by limiting the loss in reward of decreasing communication and eliminating the penalty for discretization. In this work, we successfully constrain training using a learned gate to regulate when to communicate while using discrete prototypes that reflect what to communicate for cooperative tasks with partial observability. We provide two types of "Enforcers" for hard and soft budget constraints and present results of communication under different budgets. We show that our method satisfies constraints while yielding the same performance as comparable, unconstrained methods.
Emergent Discrete Communication in Semantic Spaces
Aug 05, 2021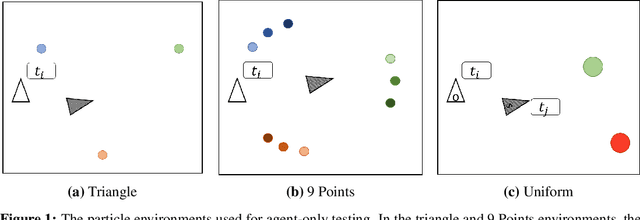
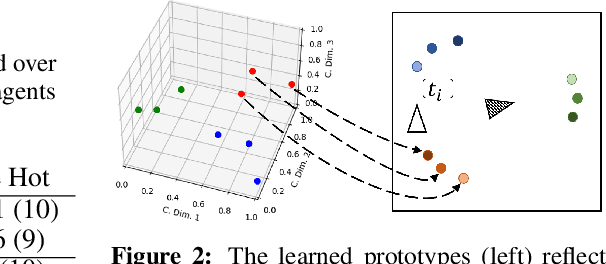

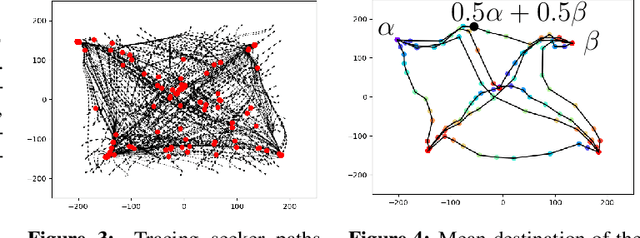
Neural agents trained in reinforcement learning settings can learn to communicate among themselves via discrete tokens, accomplishing as a team what agents would be unable to do alone. However, the current standard of using one-hot vectors as discrete communication tokens prevents agents from acquiring more desirable aspects of communication such as zero-shot understanding. Inspired by word embedding techniques from natural language processing, we propose neural agent architectures that enables them to communicate via discrete tokens derived from a learned, continuous space. We show in a decision theoretic framework that our technique optimizes communication over a wide range of scenarios, whereas one-hot tokens are only optimal under restrictive assumptions. In self-play experiments, we validate that our trained agents learn to cluster tokens in semantically-meaningful ways, allowing them communicate in noisy environments where other techniques fail. Lastly, we demonstrate both that agents using our method can effectively respond to novel human communication and that humans can understand unlabeled emergent agent communication, outperforming the use of one-hot communication.
Deep Interpretable Models of Theory of Mind For Human-Agent Teaming
Apr 07, 2021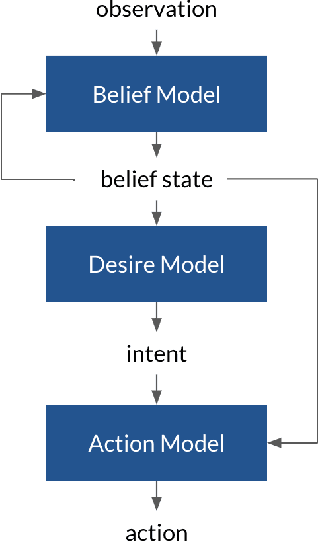
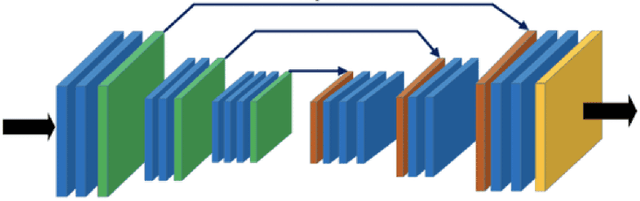
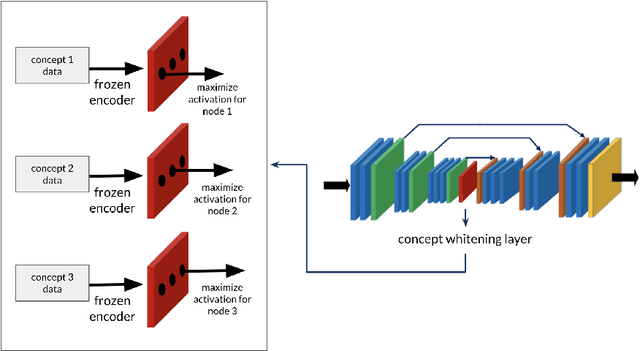
When developing AI systems that interact with humans, it is essential to design both a system that can understand humans, and a system that humans can understand. Most deep network based agent-modeling approaches are 1) not interpretable and 2) only model external behavior, ignoring internal mental states, which potentially limits their capability for assistance, interventions, discovering false beliefs, etc. To this end, we develop an interpretable modular neural framework for modeling the intentions of other observed entities. We demonstrate the efficacy of our approach with experiments on data from human participants on a search and rescue task in Minecraft, and show that incorporating interpretability can significantly increase predictive performance under the right conditions.
Adaptive Agent Architecture for Real-time Human-Agent Teaming
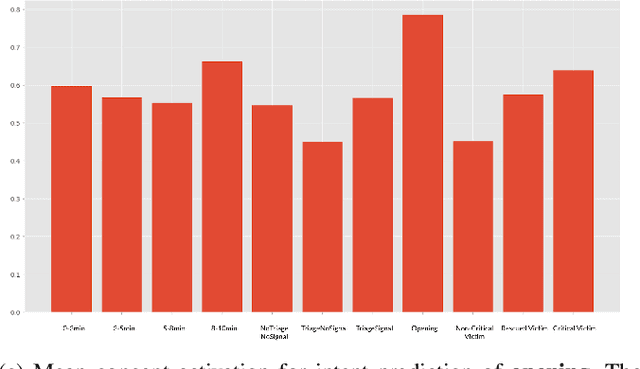
Mar 07, 2021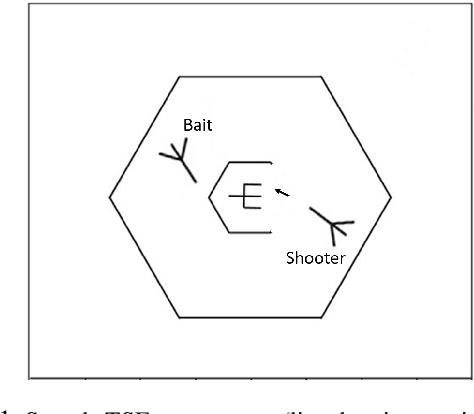
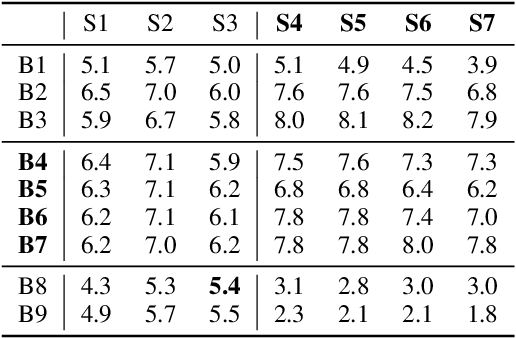
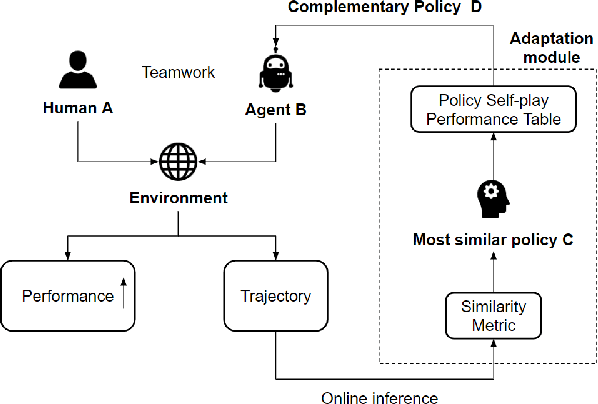
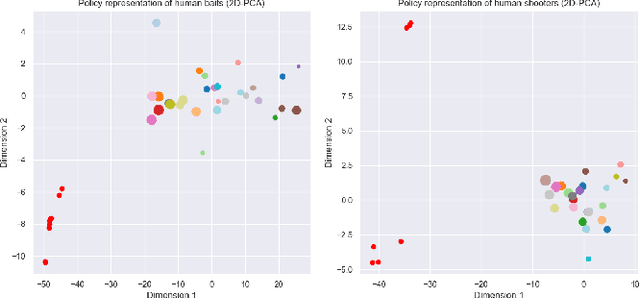
Teamwork is a set of interrelated reasoning, actions and behaviors of team members that facilitate common objectives. Teamwork theory and experiments have resulted in a set of states and processes for team effectiveness in both human-human and agent-agent teams. However, human-agent teaming is less well studied because it is so new and involves asymmetry in policy and intent not present in human teams. To optimize team performance in human-agent teaming, it is critical that agents infer human intent and adapt their polices for smooth coordination. Most literature in human-agent teaming builds agents referencing a learned human model. Though these agents are guaranteed to perform well with the learned model, they lay heavy assumptions on human policy such as optimality and consistency, which is unlikely in many real-world scenarios. In this paper, we propose a novel adaptive agent architecture in human-model-free setting on a two-player cooperative game, namely Team Space Fortress (TSF). Previous human-human team research have shown complementary policies in TSF game and diversity in human players' skill, which encourages us to relax the assumptions on human policy. Therefore, we discard learning human models from human data, and instead use an adaptation strategy on a pre-trained library of exemplar policies composed of RL algorithms or rule-based methods with minimal assumptions of human behavior. The adaptation strategy relies on a novel similarity metric to infer human policy and then selects the most complementary policy in our library to maximize the team performance. The adaptive agent architecture can be deployed in real-time and generalize to any off-the-shelf static agents. We conducted human-agent experiments to evaluate the proposed adaptive agent framework, and demonstrated the suboptimality, diversity, and adaptability of human policies in human-agent teams.
Predicting Human Strategies in Simulated Search and Rescue Task
Nov 19, 2020
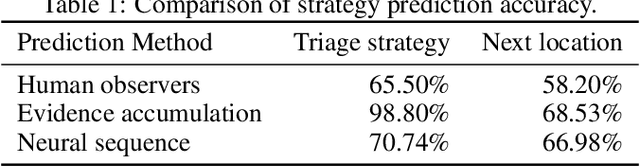

In a search and rescue scenario, rescuers may have different knowledge of the environment and strategies for exploration. Understanding what is inside a rescuer's mind will enable an observer agent to proactively assist them with critical information that can help them perform their task efficiently. To this end, we propose to build models of the rescuers based on their trajectory observations to predict their strategies. In our efforts to model the rescuer's mind, we begin with a simple simulated search and rescue task in Minecraft with human participants. We formulate neural sequence models to predict the triage strategy and the next location of the rescuer. As the neural networks are data-driven, we design a diverse set of artificial "faux human" agents for training, to test them with limited human rescuer trajectory data. To evaluate the agents, we compare it to an evidence accumulation method that explicitly incorporates all available background knowledge and provides an intended upper bound for the expected performance. Further, we perform experiments where the observer/predictor is human. We show results in terms of prediction accuracy of our computational approaches as compared with that of human observers.