 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCALAR: Learning and Composing Skills through LLM Guided Symbolic Planning and Deep RL Grounding
Mar 10, 2026LM-based agents excel when given high-level action APIs but struggle to ground language into low-level control. Prior work has LLMs generate skills or reward functions for RL, but these one-shot approaches lack feedback to correct specification errors. We introduce SCALAR, a bidirectional framework coupling LLM planning with RL through a learned skill library. The LLM proposes skills with preconditions and effects; RL trains policies for each skill and feeds back execution results to iteratively refine specifications, improving robustness to initial errors. Pivotal Trajectory Analysis corrects LLM priors by analyzing RL trajectories; Frontier Checkpointing optionally saves environment states at skill boundaries to improve sample efficiency. On Craftax, SCALAR achieves 88.2% diamond collection, a 1.9x improvement over the best baseline, and reaches the Gnomish Mines 9.1% of the time where prior methods fail entirely.
Overcoming Valid Action Suppression in Unmasked Policy Gradient Algorithms
Mar 10, 2026In reinforcement learning environments with state-dependent action validity, action masking consistently outperforms penalty-based handling of invalid actions, yet existing theory only shows that masking preserves the policy gradient theorem. We identify a distinct failure mode of unmasked training: it systematically suppresses valid actions at states the agent has not yet visited. This occurs because gradients pushing down invalid actions at visited states propagate through shared network parameters to unvisited states where those actions are valid. We prove that for softmax policies with shared features, when an action is invalid at visited states but valid at an unvisited state $s^*$, the probability $π(a \mid s^*)$ is bounded by exponential decay due to parameter sharing and the zero-sum identity of softmax logits. This bound reveals that entropy regularization trades off between protecting valid actions and sample efficiency, a tradeoff that masking eliminates. We validate empirically that deep networks exhibit the feature alignment condition required for suppression, and experiments on Craftax, Craftax-Classic, and MiniHack confirm the predicted exponential suppression and demonstrate that feasibility classification enables deployment without oracle masks.
Benchmarking and Enhancing Disentanglement in Concept-Residual Models
Nov 30, 2023Concept bottleneck models (CBMs) are interpretable models that first predict a set of semantically meaningful features, i.e., concepts, from observations that are subsequently used to condition a downstream task. However, the model's performance strongly depends on the engineered features and can severely suffer from incomplete sets of concepts. Prior works have proposed a side channel -- a residual -- that allows for unconstrained information flow to the downstream task, thus improving model performance but simultaneously introducing information leakage, which is undesirable for interpretability. This work proposes three novel approaches to mitigate information leakage by disentangling concepts and residuals, investigating the critical balance between model performance and interpretability. Through extensive empirical analysis on the CUB, OAI, and CIFAR 100 datasets, we assess the performance of each disentanglement method and provide insights into when they work best. Further, we show how each method impacts the ability to intervene over the concepts and their subsequent impact on task performance.
Concept Learning for Interpretable Multi-Agent Reinforcement Learning
Feb 23, 2023



Multi-agent robotic systems are increasingly operating in real-world environments in close proximity to humans, yet are largely controlled by policy models with inscrutable deep neural network representations. We introduce a method for incorporating interpretable concepts from a domain expert into models trained through multi-agent reinforcement learning, by requiring the model to first predict such concepts then utilize them for decision making. This allows an expert to both reason about the resulting concept policy models in terms of these high-level concepts at run-time, as well as intervene and correct mispredictions to improve performance. We show that this yields improved interpretability and training stability, with benefits to policy performance and sample efficiency in a simulated and real-world cooperative-competitive multi-agent game.
Normalizing Flows Across Dimensions
Jun 23, 2020
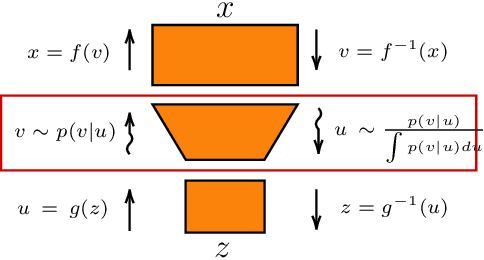

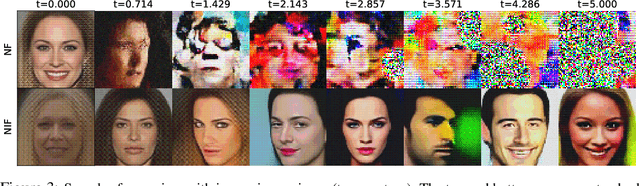
Real-world data with underlying structure, such as pictures of faces, are hypothesized to lie on a low-dimensional manifold. This manifold hypothesis has motivated state-of-the-art generative algorithms that learn low-dimensional data representations. Unfortunately, a popular generative model, normalizing flows, cannot take advantage of this. Normalizing flows are based on successive variable transformations that are, by design, incapable of learning lower-dimensional representations. In this paper we introduce noisy injective flows (NIF), a generalization of normalizing flows that can go across dimensions. NIF explicitly map the latent space to a learnable manifold in a high-dimensional data space using injective transformations. We further employ an additive noise model to account for deviations from the manifold and identify a stochastic inverse of the generative process. Empirically, we demonstrate that a simple application of our method to existing flow architectures can significantly improve sample quality and yield separable data embeddings.