 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConTraIRL: Factorized Contrastive Abstractions for Transferable IRL
Jun 02, 2026Reward transfer in Inverse Reinforcement Learning (IRL) is unreliable when policies must generalize to unseen combinations of environment dynamics and task goals. We propose Factorized Contrastive Abstractions for Transferable IRL (ConTraIRL), a framework that enables compositional reward transfer by learning decoupled latent representations of these two factors. ConTraIRL uses a dual-encoder architecture that maps observations into separate dynamics and goal latent spaces, trained with a dual contrastive objective. Temporal alignment encourages the dynamics encoder to learn goal-invariant structure, while the goal encoder captures dynamics-invariant features. This factorization supports reward inference under recombined dynamics-goal settings. Experiments on continuous control benchmarks demonstrate effective few-shot transfer to unseen dynamics-goal pairings, improving sample efficiency and reward recovery over transfer IRL baselines.
Inversely Learning Transferable Rewards via Abstracted States
Jan 03, 2025



Inverse reinforcement learning (IRL) has progressed significantly toward accurately learning the underlying rewards in both discrete and continuous domains from behavior data. The next advance is to learn {\em intrinsic} preferences in ways that produce useful behavior in settings or tasks which are different but aligned with the observed ones. In the context of robotic applications, this helps integrate robots into processing lines involving new tasks (with shared intrinsic preferences) without programming from scratch. We introduce a method to inversely learn an abstract reward function from behavior trajectories in two or more differing instances of a domain. The abstract reward function is then used to learn task behavior in another separate instance of the domain. This step offers evidence of its transferability and validates its correctness. We evaluate the method on trajectories in tasks from multiple domains in OpenAI's Gym testbed and AssistiveGym and show that the learned abstract reward functions can successfully learn task behaviors in instances of the respective domains, which have not been seen previously.
A Novel Variational Lower Bound for Inverse Reinforcement Learning
Nov 10, 2023



Inverse reinforcement learning (IRL) seeks to learn the reward function from expert trajectories, to understand the task for imitation or collaboration thereby removing the need for manual reward engineering. However, IRL in the context of large, high-dimensional problems with unknown dynamics has been particularly challenging. In this paper, we present a new Variational Lower Bound for IRL (VLB-IRL), which is derived under the framework of a probabilistic graphical model with an optimality node. Our method simultaneously learns the reward function and policy under the learned reward function by maximizing the lower bound, which is equivalent to minimizing the reverse Kullback-Leibler divergence between an approximated distribution of optimality given the reward function and the true distribution of optimality given trajectories. This leads to a new IRL method that learns a valid reward function such that the policy under the learned reward achieves expert-level performance on several known domains. Importantly, the method outperforms the existing state-of-the-art IRL algorithms on these domains by demonstrating better reward from the learned policy.
IRL with Partial Observations using the Principle of Uncertain Maximum Entropy
Aug 15, 2022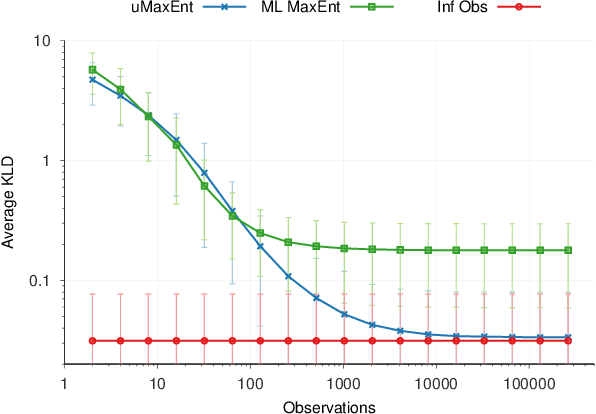
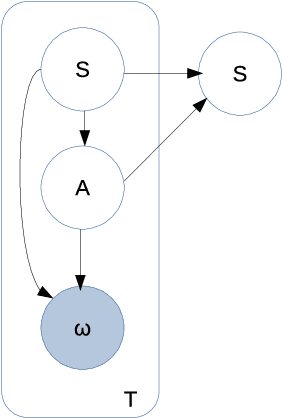
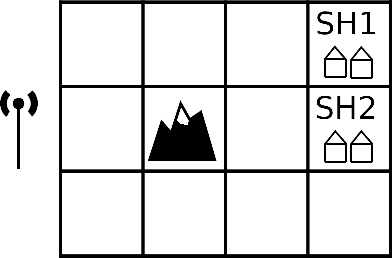
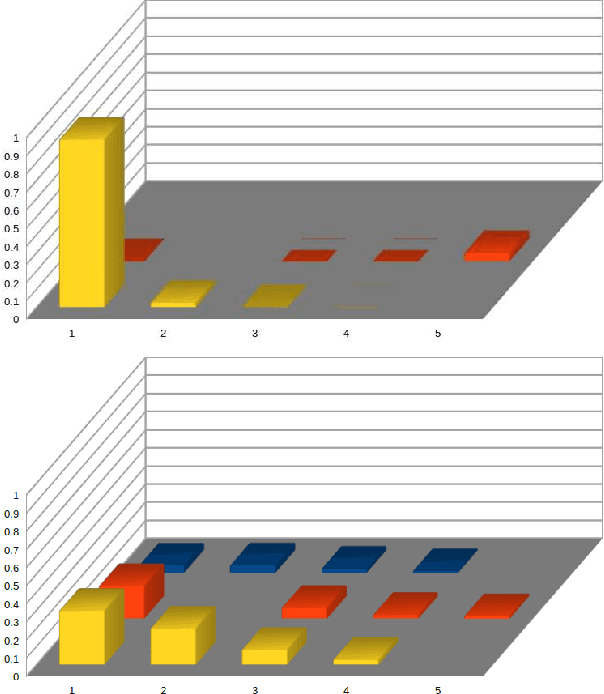
The principle of maximum entropy is a broadly applicable technique for computing a distribution with the least amount of information possible while constrained to match empirically estimated feature expectations. However, in many real-world applications that use noisy sensors computing the feature expectations may be challenging due to partial observation of the relevant model variables. For example, a robot performing apprenticeship learning may lose sight of the agent it is learning from due to environmental occlusion. We show that in generalizing the principle of maximum entropy to these types of scenarios we unavoidably introduce a dependency on the learned model to the empirical feature expectations. We introduce the principle of uncertain maximum entropy and present an expectation-maximization based solution generalized from the principle of latent maximum entropy. Finally, we experimentally demonstrate the improved robustness to noisy data offered by our technique in a maximum causal entropy inverse reinforcement learning domain.
Message Expiration-Based Distributed Multi-Robot Task Management
Jan 08, 2022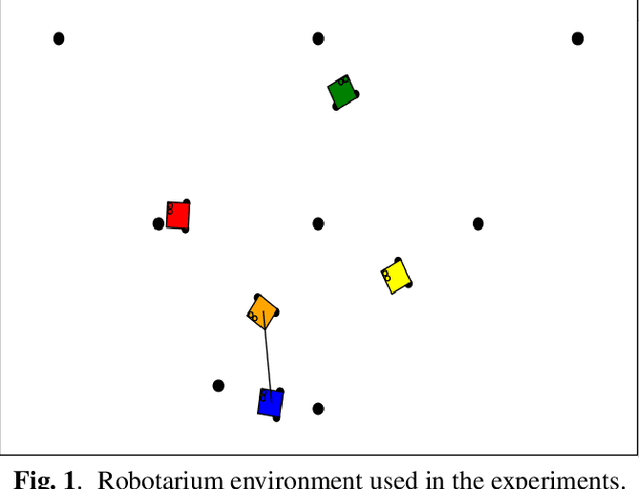
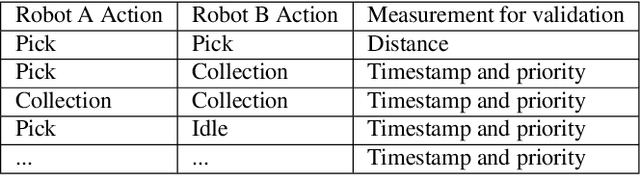

Distributed task assignment for multiple agents raises fundamental and novel control theory and robotics problems. A new challenge is the development of distributed algorithms that dynamically assign tasks to multiple agents, not relying on prior assignment information. This work presents a distributed method for multi-robot task management based on a message expiration-based validation approach. Our approach handles the conflicts caused by a disconnection in the distributed multi-robot system by using distance-based and timestamp-based measurements to validate the task allocation for each robot. Simulation experiments in the Robotarium simulator platform have verified the validity of the proposed approach.
Energy-Aware Multi-Robot Task Allocation in Persistent Tasks
Dec 31, 2021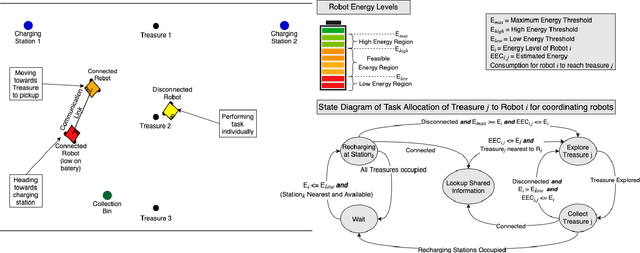
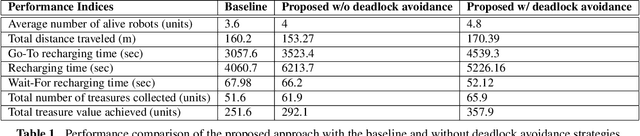

The applicability of the swarm robots to perform foraging tasks is inspired by their compact size and cost. A considerable amount of energy is required to perform such tasks, especially if the tasks are continuous and/or repetitive. Real-world situations in which robots perform tasks continuously while staying alive (survivability) and maximizing production (performance) require energy awareness. This paper proposes an energy-conscious distributed task allocation algorithm to solve continuous tasks (e.g., unlimited foraging) for cooperative robots to achieve highly effective missions. We consider efficiency as a function of the energy consumed by the robot during exploration and collection when food is returned to the collection bin. Finally, the proposed energy-efficient algorithm minimizes the total transit time to the charging station and time consumed while recharging and maximizes the robot's lifetime to perform maximum tasks to enhance the overall efficiency of collaborative robots. We evaluated the proposed solution against a typical greedy benchmarking strategy (assigning the closest collection bin to the available robot and recharging the robot at maximum) for efficiency and performance in various scenarios. The proposed approach significantly improved performance and efficiency over the baseline approach.
Adaptive Agent Architecture for Real-time Human-Agent Teaming
Mar 07, 2021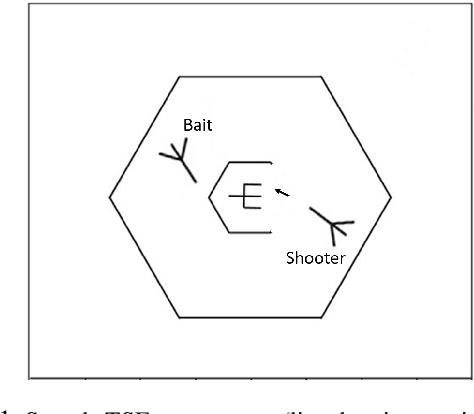
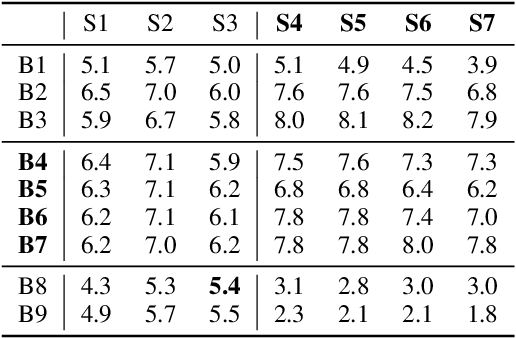
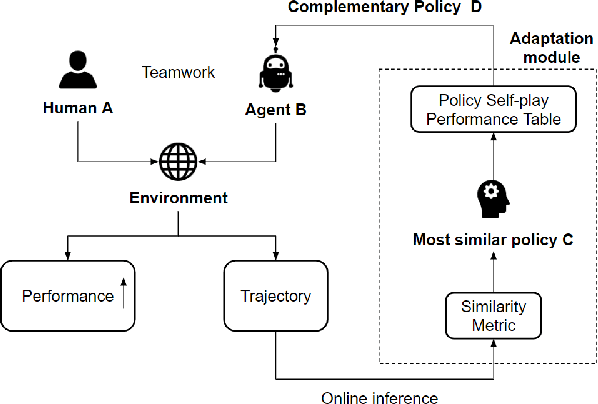
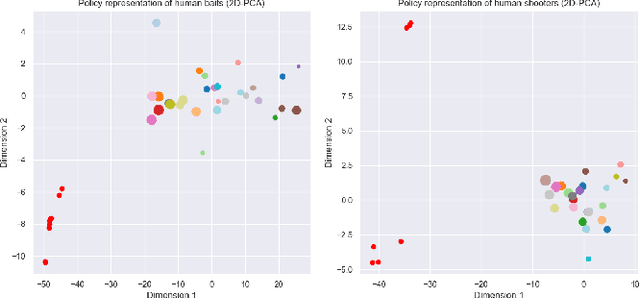
Teamwork is a set of interrelated reasoning, actions and behaviors of team members that facilitate common objectives. Teamwork theory and experiments have resulted in a set of states and processes for team effectiveness in both human-human and agent-agent teams. However, human-agent teaming is less well studied because it is so new and involves asymmetry in policy and intent not present in human teams. To optimize team performance in human-agent teaming, it is critical that agents infer human intent and adapt their polices for smooth coordination. Most literature in human-agent teaming builds agents referencing a learned human model. Though these agents are guaranteed to perform well with the learned model, they lay heavy assumptions on human policy such as optimality and consistency, which is unlikely in many real-world scenarios. In this paper, we propose a novel adaptive agent architecture in human-model-free setting on a two-player cooperative game, namely Team Space Fortress (TSF). Previous human-human team research have shown complementary policies in TSF game and diversity in human players' skill, which encourages us to relax the assumptions on human policy. Therefore, we discard learning human models from human data, and instead use an adaptation strategy on a pre-trained library of exemplar policies composed of RL algorithms or rule-based methods with minimal assumptions of human behavior. The adaptation strategy relies on a novel similarity metric to infer human policy and then selects the most complementary policy in our library to maximize the team performance. The adaptive agent architecture can be deployed in real-time and generalize to any off-the-shelf static agents. We conducted human-agent experiments to evaluate the proposed adaptive agent framework, and demonstrated the suboptimality, diversity, and adaptability of human policies in human-agent teams.