 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIRL with Partial Observations using the Principle of Uncertain Maximum Entropy
Paper and Code
Aug 15, 2022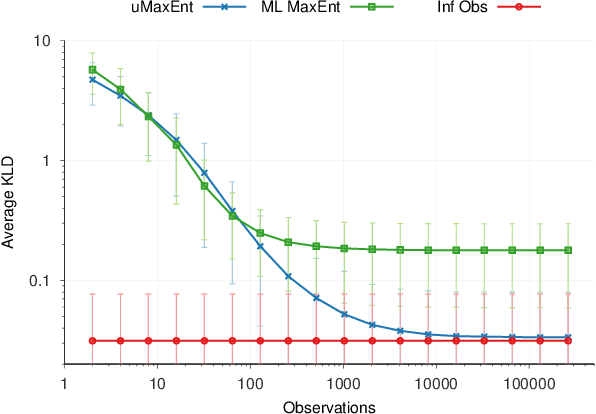
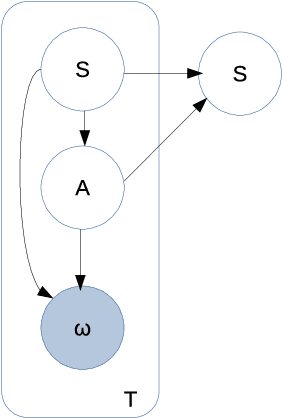
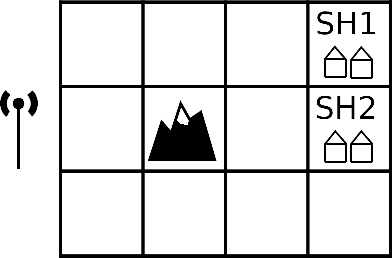
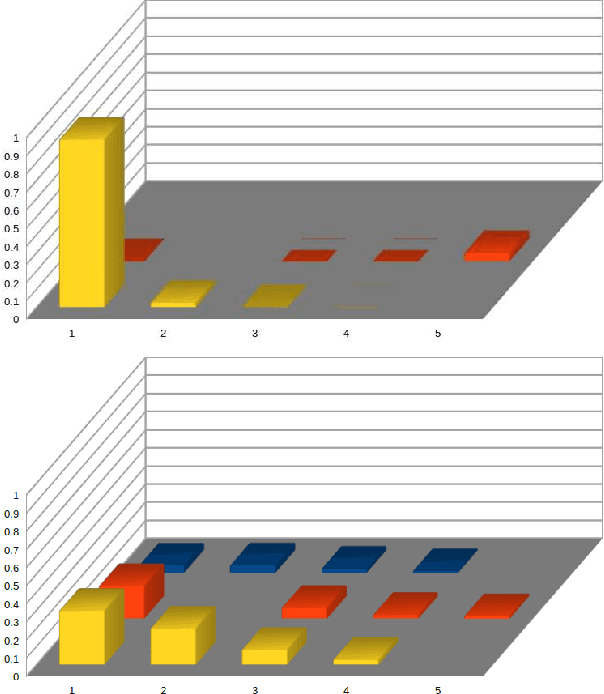
The principle of maximum entropy is a broadly applicable technique for computing a distribution with the least amount of information possible while constrained to match empirically estimated feature expectations. However, in many real-world applications that use noisy sensors computing the feature expectations may be challenging due to partial observation of the relevant model variables. For example, a robot performing apprenticeship learning may lose sight of the agent it is learning from due to environmental occlusion. We show that in generalizing the principle of maximum entropy to these types of scenarios we unavoidably introduce a dependency on the learned model to the empirical feature expectations. We introduce the principle of uncertain maximum entropy and present an expectation-maximization based solution generalized from the principle of latent maximum entropy. Finally, we experimentally demonstrate the improved robustness to noisy data offered by our technique in a maximum causal entropy inverse reinforcement learning domain.