 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Intelligence Bias on English Language Learners in Automatic Scoring
May 15, 2025This study investigated potential scoring biases and disparities toward English Language Learners (ELLs) when using automatic scoring systems for middle school students' written responses to science assessments. We specifically focus on examining how unbalanced training data with ELLs contributes to scoring bias and disparities. We fine-tuned BERT with four datasets: responses from (1) ELLs, (2) non-ELLs, (3) a mixed dataset reflecting the real-world proportion of ELLs and non-ELLs (unbalanced), and (4) a balanced mixed dataset with equal representation of both groups. The study analyzed 21 assessment items: 10 items with about 30,000 ELL responses, five items with about 1,000 ELL responses, and six items with about 200 ELL responses. Scoring accuracy (Acc) was calculated and compared to identify bias using Friedman tests. We measured the Mean Score Gaps (MSGs) between ELLs and non-ELLs and then calculated the differences in MSGs generated through both the human and AI models to identify the scoring disparities. We found that no AI bias and distorted disparities between ELLs and non-ELLs were found when the training dataset was large enough (ELL = 30,000 and ELL = 1,000), but concerns could exist if the sample size is limited (ELL = 200).
Knowledge Distillation and Dataset Distillation of Large Language Models: Emerging Trends, Challenges, and Future Directions
Apr 20, 2025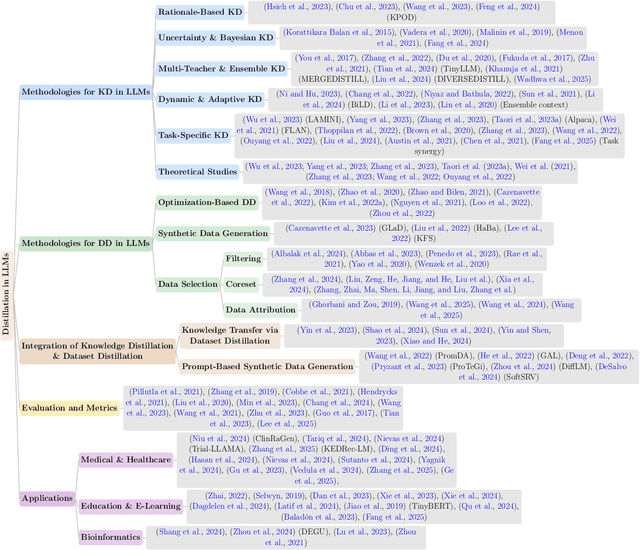
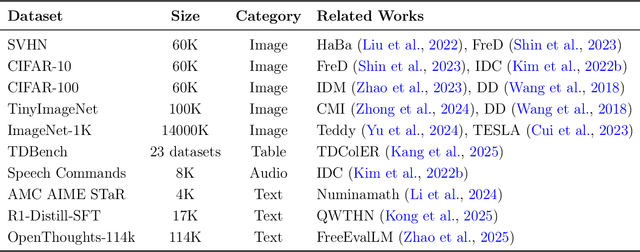
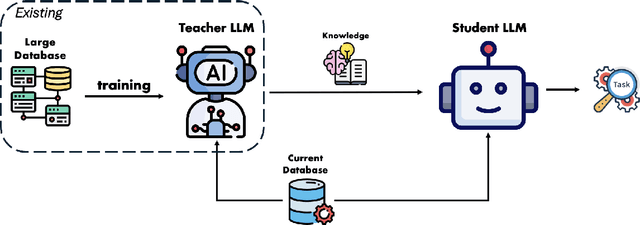

The exponential growth of Large Language Models (LLMs) continues to highlight the need for efficient strategies to meet ever-expanding computational and data demands. This survey provides a comprehensive analysis of two complementary paradigms: Knowledge Distillation (KD) and Dataset Distillation (DD), both aimed at compressing LLMs while preserving their advanced reasoning capabilities and linguistic diversity. We first examine key methodologies in KD, such as task-specific alignment, rationale-based training, and multi-teacher frameworks, alongside DD techniques that synthesize compact, high-impact datasets through optimization-based gradient matching, latent space regularization, and generative synthesis. Building on these foundations, we explore how integrating KD and DD can produce more effective and scalable compression strategies. Together, these approaches address persistent challenges in model scalability, architectural heterogeneity, and the preservation of emergent LLM abilities. We further highlight applications across domains such as healthcare and education, where distillation enables efficient deployment without sacrificing performance. Despite substantial progress, open challenges remain in preserving emergent reasoning and linguistic diversity, enabling efficient adaptation to continually evolving teacher models and datasets, and establishing comprehensive evaluation protocols. By synthesizing methodological innovations, theoretical foundations, and practical insights, our survey charts a path toward sustainable, resource-efficient LLMs through the tighter integration of KD and DD principles.
Efficient Multi-Task Inferencing: Model Merging with Gromov-Wasserstein Feature Alignment
Mar 12, 2025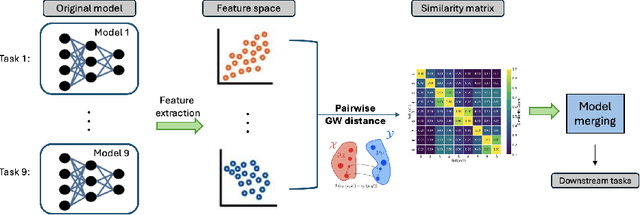


Automatic scoring of student responses enhances efficiency in education, but deploying a separate neural network for each task increases storage demands, maintenance efforts, and redundant computations. To address these challenges, this paper introduces the Gromov-Wasserstein Scoring Model Merging (GW-SMM) method, which merges models based on feature distribution similarities measured via the Gromov-Wasserstein distance. Our approach begins by extracting features from student responses using individual models, capturing both item-specific context and unique learned representations. The Gromov-Wasserstein distance then quantifies the similarity between these feature distributions, identifying the most compatible models for merging. Models exhibiting the smallest pairwise distances, typically in pairs or trios, are merged by combining only the shared layers preceding the classification head. This strategy results in a unified feature extractor while preserving separate classification heads for item-specific scoring. We validated our approach against human expert knowledge and a GPT-o1-based merging method. GW-SMM consistently outperformed both, achieving a higher micro F1 score, macro F1 score, exact match accuracy, and per-label accuracy. The improvements in micro F1 and per-label accuracy were statistically significant compared to GPT-o1-based merging (p=0.04, p=0.01). Additionally, GW-SMM reduced storage requirements by half without compromising much accuracy, demonstrating its computational efficiency alongside reliable scoring performance.
Fine-tuning ChatGPT for Automatic Scoring of Written Scientific Explanations in Chinese
Jan 12, 2025



The development of explanations for scientific phenomena is essential in science assessment, but scoring student-written explanations remains challenging and resource-intensive. Large language models (LLMs) have shown promise in addressing this issue, particularly in alphabetic languages like English. However, their applicability to logographic languages is less explored. This study investigates the potential of fine-tuning ChatGPT, a leading LLM, to automatically score scientific explanations written in Chinese. Student responses to seven scientific explanation tasks were collected and automatically scored, with scoring accuracy examined in relation to reasoning complexity using the Kendall correlation. A qualitative analysis explored how linguistic features influenced scoring accuracy. The results show that domain-specific adaptation enables ChatGPT to score Chinese scientific explanations with accuracy. However, scoring accuracy correlates with reasoning complexity: a negative correlation for lower-level responses and a positive one for higher-level responses. The model overrates complex reasoning in low-level responses with intricate sentence structures and underrates high-level responses using concise causal reasoning. These correlations stem from linguistic features--simplicity and clarity enhance accuracy for lower-level responses, while comprehensiveness improves accuracy for higher-level ones. Simpler, shorter responses tend to score more accurately at lower levels, whereas longer, information-rich responses yield better accuracy at higher levels. These findings demonstrate the effectiveness of LLMs in automatic scoring within a Chinese context and emphasize the importance of linguistic features and reasoning complexity in fine-tuning scoring models for educational assessments.
Efficient Multi-Task Inferencing with a Shared Backbone and Lightweight Task-Specific Adapters for Automatic Scoring
Dec 30, 2024The integration of Artificial Intelligence (AI) in education requires scalable and efficient frameworks that balance performance, adaptability, and cost. This paper addresses these needs by proposing a shared backbone model architecture enhanced with lightweight LoRA adapters for task-specific fine-tuning, targeting the automated scoring of student responses across 27 mutually exclusive tasks. By achieving competitive performance (average QWK of 0.848 compared to 0.888 for fully fine-tuned models) while reducing GPU memory consumption by 60% and inference latency by 40%, the framework demonstrates significant efficiency gains. This approach aligns with the workshops' focus on improving language models for educational tasks, creating responsible innovations for cost-sensitive deployment, and supporting educators by streamlining assessment workflows. The findings underscore the potential of scalable AI to enhance learning outcomes while maintaining fairness and transparency in automated scoring systems.
Can OpenAI o1 outperform humans in higher-order cognitive thinking?
Dec 07, 2024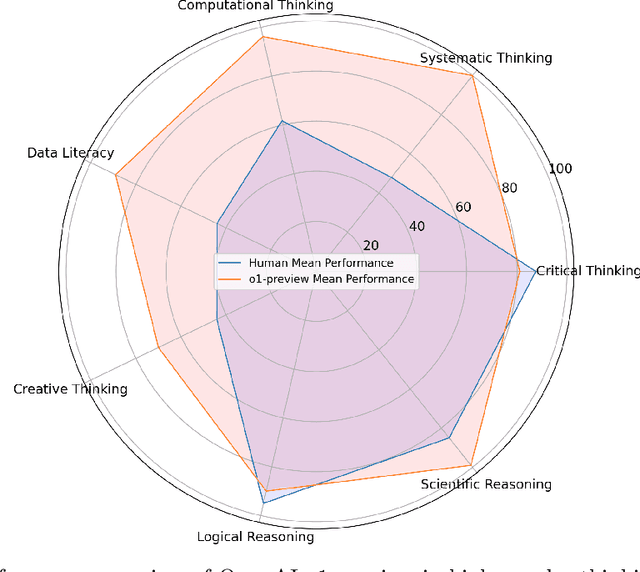
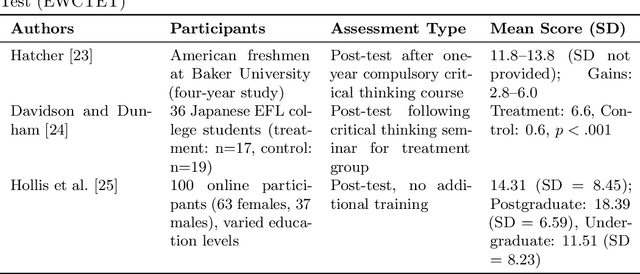

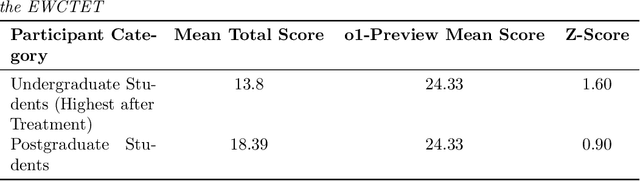
This study evaluates the performance of OpenAI's o1-preview model in higher-order cognitive domains, including critical thinking, systematic thinking, computational thinking, data literacy, creative thinking, logical reasoning, and scientific reasoning. Using established benchmarks, we compared the o1-preview models's performance to human participants from diverse educational levels. o1-preview achieved a mean score of 24.33 on the Ennis-Weir Critical Thinking Essay Test (EWCTET), surpassing undergraduate (13.8) and postgraduate (18.39) participants (z = 1.60 and 0.90, respectively). In systematic thinking, it scored 46.1, SD = 4.12 on the Lake Urmia Vignette, significantly outperforming the human mean (20.08, SD = 8.13, z = 3.20). For data literacy, o1-preview scored 8.60, SD = 0.70 on Merk et al.'s "Use Data" dimension, compared to the human post-test mean of 4.17, SD = 2.02 (z = 2.19). On creative thinking tasks, the model achieved originality scores of 2.98, SD = 0.73, higher than the human mean of 1.74 (z = 0.71). In logical reasoning (LogiQA), it outperformed humans with average 90%, SD = 10% accuracy versus 86%, SD = 6.5% (z = 0.62). For scientific reasoning, it achieved near-perfect performance (mean = 0.99, SD = 0.12) on the TOSLS,, exceeding the highest human scores of 0.85, SD = 0.13 (z = 1.78). While o1-preview excelled in structured tasks, it showed limitations in problem-solving and adaptive reasoning. These results demonstrate the potential of AI to complement education in structured assessments but highlight the need for ethical oversight and refinement for broader applications.
Using Generative AI and Multi-Agents to Provide Automatic Feedback
Nov 11, 2024

This study investigates the use of generative AI and multi-agent systems to provide automatic feedback in educational contexts, particularly for student constructed responses in science assessments. The research addresses a key gap in the field by exploring how multi-agent systems, called AutoFeedback, can improve the quality of GenAI-generated feedback, overcoming known issues such as over-praise and over-inference that are common in single-agent large language models (LLMs). The study developed a multi-agent system consisting of two AI agents: one for generating feedback and another for validating and refining it. The system was tested on a dataset of 240 student responses, and its performance was compared to that of a single-agent LLM. Results showed that AutoFeedback significantly reduced the occurrence of over-praise and over-inference errors, providing more accurate and pedagogically sound feedback. The findings suggest that multi-agent systems can offer a more reliable solution for generating automated feedback in educational settings, highlighting their potential for scalable and personalized learning support. These results have important implications for educators and researchers seeking to leverage AI in formative assessments, offering a pathway to more effective feedback mechanisms that enhance student learning outcomes.
Object-Oriented Material Classification and 3D Clustering for Improved Semantic Perception and Mapping in Mobile Robots
Jul 08, 2024Classification of different object surface material types can play a significant role in the decision-making algorithms for mobile robots and autonomous vehicles. RGB-based scene-level semantic segmentation has been well-addressed in the literature. However, improving material recognition using the depth modality and its integration with SLAM algorithms for 3D semantic mapping could unlock new potential benefits in the robotics perception pipeline. To this end, we propose a complementarity-aware deep learning approach for RGB-D-based material classification built on top of an object-oriented pipeline. The approach further integrates the ORB-SLAM2 method for 3D scene mapping with multiscale clustering of the detected material semantics in the point cloud map generated by the visual SLAM algorithm. Extensive experimental results with existing public datasets and newly contributed real-world robot datasets demonstrate a significant improvement in material classification and 3D clustering accuracy compared to state-of-the-art approaches for 3D semantic scene mapping.
Anchor-Oriented Localized Voronoi Partitioning for GPS-denied Multi-Robot Coverage
Jul 08, 2024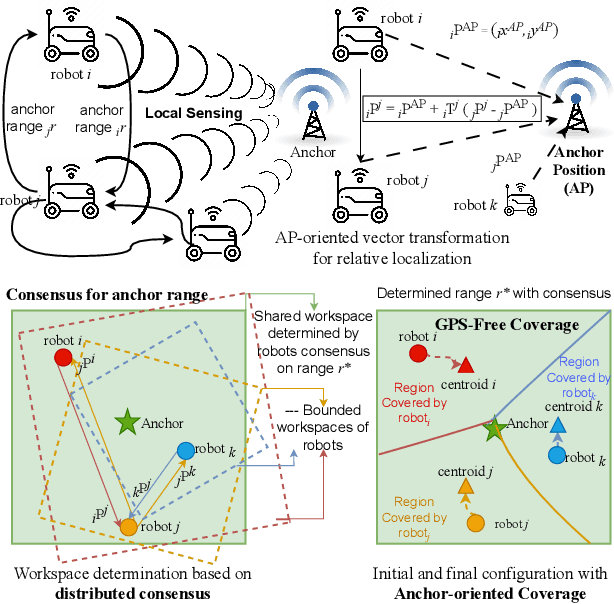
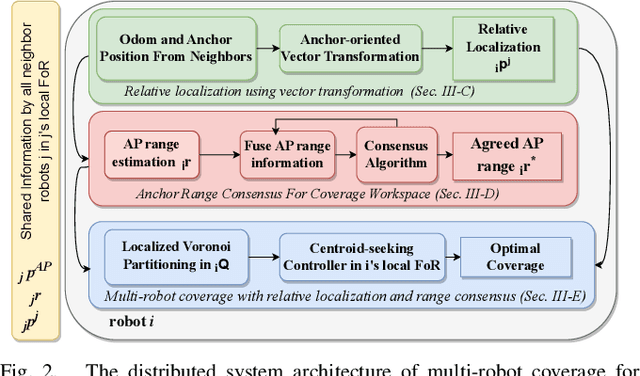


Multi-robot coverage is crucial in numerous applications, including environmental monitoring, search and rescue operations, and precision agriculture. In modern applications, a multi-robot team must collaboratively explore unknown spatial fields in GPS-denied and extreme environments where global localization is unavailable. Coverage algorithms typically assume that the robot positions and the coverage environment are defined in a global reference frame. However, coordinating robot motion and ensuring coverage of the shared convex workspace without global localization is challenging. This paper proposes a novel anchor-oriented coverage (AOC) approach to generate dynamic localized Voronoi partitions based around a common anchor position. We further propose a consensus-based coordination algorithm that achieves agreement on the coverage workspace around the anchor in the robots' relative frames of reference. Through extensive simulations and real-world experiments, we demonstrate that the proposed anchor-oriented approach using localized Voronoi partitioning performs as well as the state-of-the-art coverage controller using GPS.
PhysicsAssistant: An LLM-Powered Interactive Learning Robot for Physics Lab Investigations
Mar 27, 2024



Robot systems in education can leverage Large language models' (LLMs) natural language understanding capabilities to provide assistance and facilitate learning. This paper proposes a multimodal interactive robot (PhysicsAssistant) built on YOLOv8 object detection, cameras, speech recognition, and chatbot using LLM to provide assistance to students' physics labs. We conduct a user study on ten 8th-grade students to empirically evaluate the performance of PhysicsAssistant with a human expert. The Expert rates the assistants' responses to student queries on a 0-4 scale based on Bloom's taxonomy to provide educational support. We have compared the performance of PhysicsAssistant (YOLOv8+GPT-3.5-turbo) with GPT-4 and found that the human expert rating of both systems for factual understanding is the same. However, the rating of GPT-4 for conceptual and procedural knowledge (3 and 3.2 vs 2.2 and 2.6, respectively) is significantly higher than PhysicsAssistant (p < 0.05). However, the response time of GPT-4 is significantly higher than PhysicsAssistant (3.54 vs 1.64 sec, p < 0.05). Hence, despite the relatively lower response quality of PhysicsAssistant than GPT-4, it has shown potential for being used as a real-time lab assistant to provide timely responses and can offload teachers' labor to assist with repetitive tasks. To the best of our knowledge, this is the first attempt to build such an interactive multimodal robotic assistant for K-12 science (physics) education.