 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan OpenAI o1 outperform humans in higher-order cognitive thinking?
Dec 07, 2024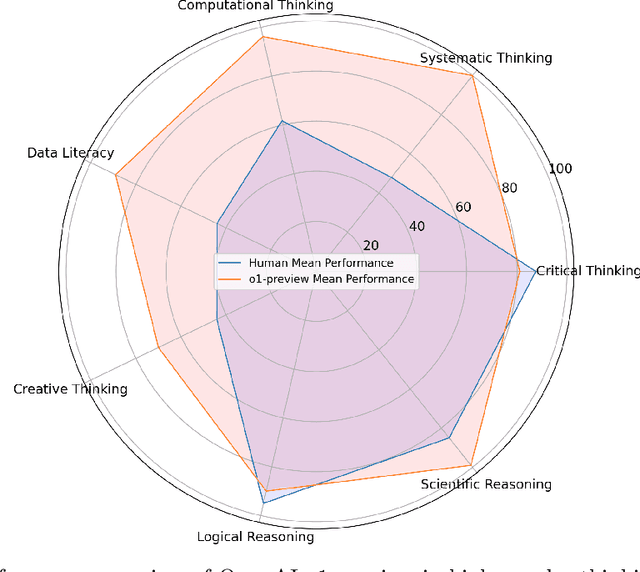

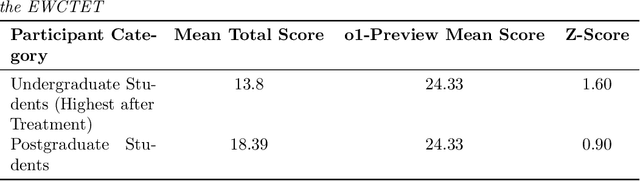
This study evaluates the performance of OpenAI's o1-preview model in higher-order cognitive domains, including critical thinking, systematic thinking, computational thinking, data literacy, creative thinking, logical reasoning, and scientific reasoning. Using established benchmarks, we compared the o1-preview models's performance to human participants from diverse educational levels. o1-preview achieved a mean score of 24.33 on the Ennis-Weir Critical Thinking Essay Test (EWCTET), surpassing undergraduate (13.8) and postgraduate (18.39) participants (z = 1.60 and 0.90, respectively). In systematic thinking, it scored 46.1, SD = 4.12 on the Lake Urmia Vignette, significantly outperforming the human mean (20.08, SD = 8.13, z = 3.20). For data literacy, o1-preview scored 8.60, SD = 0.70 on Merk et al.'s "Use Data" dimension, compared to the human post-test mean of 4.17, SD = 2.02 (z = 2.19). On creative thinking tasks, the model achieved originality scores of 2.98, SD = 0.73, higher than the human mean of 1.74 (z = 0.71). In logical reasoning (LogiQA), it outperformed humans with average 90%, SD = 10% accuracy versus 86%, SD = 6.5% (z = 0.62). For scientific reasoning, it achieved near-perfect performance (mean = 0.99, SD = 0.12) on the TOSLS,, exceeding the highest human scores of 0.85, SD = 0.13 (z = 1.78). While o1-preview excelled in structured tasks, it showed limitations in problem-solving and adaptive reasoning. These results demonstrate the potential of AI to complement education in structured assessments but highlight the need for ethical oversight and refinement for broader applications.
Reinforced Imitative Trajectory Planning for Urban Automated Driving
Oct 21, 2024



Reinforcement learning (RL) faces challenges in trajectory planning for urban automated driving due to the poor convergence of RL and the difficulty in designing reward functions. The convergence problem is alleviated by combining RL with supervised learning. However, most existing approaches only reason one step ahead and lack the capability to plan for multiple future steps. Besides, although inverse reinforcement learning holds promise for solving the reward function design issue, existing methods for automated driving impose a linear structure assumption on reward functions, making them difficult to apply to urban automated driving. In light of these challenges, this paper proposes a novel RL-based trajectory planning method that integrates RL with imitation learning to enable multi-step planning. Furthermore, a transformer-based Bayesian reward function is developed, providing effective reward signals for RL in urban scenarios. Moreover, a hybrid-driven trajectory planning framework is proposed to enhance safety and interpretability. The proposed methods were validated on the large-scale real-world urban automated driving nuPlan dataset. The results demonstrated the significant superiority of the proposed methods over the baselines in terms of the closed-loop metrics. The code is available at https://github.com/Zigned/nuplan_zigned.