 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforced Imitative Trajectory Planning for Urban Automated Driving
Oct 21, 2024



Reinforcement learning (RL) faces challenges in trajectory planning for urban automated driving due to the poor convergence of RL and the difficulty in designing reward functions. The convergence problem is alleviated by combining RL with supervised learning. However, most existing approaches only reason one step ahead and lack the capability to plan for multiple future steps. Besides, although inverse reinforcement learning holds promise for solving the reward function design issue, existing methods for automated driving impose a linear structure assumption on reward functions, making them difficult to apply to urban automated driving. In light of these challenges, this paper proposes a novel RL-based trajectory planning method that integrates RL with imitation learning to enable multi-step planning. Furthermore, a transformer-based Bayesian reward function is developed, providing effective reward signals for RL in urban scenarios. Moreover, a hybrid-driven trajectory planning framework is proposed to enhance safety and interpretability. The proposed methods were validated on the large-scale real-world urban automated driving nuPlan dataset. The results demonstrated the significant superiority of the proposed methods over the baselines in terms of the closed-loop metrics. The code is available at https://github.com/Zigned/nuplan_zigned.
Improving Multi-Interest Network with Stable Learning
Jul 14, 2022
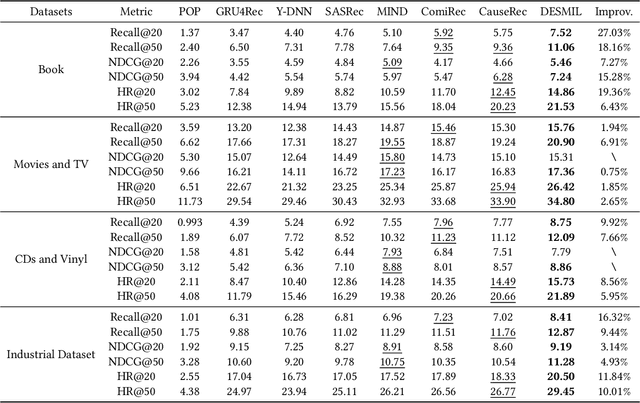
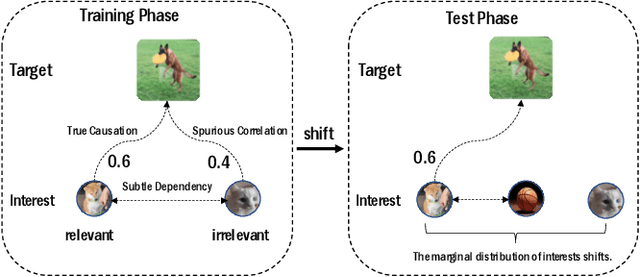

Modeling users' dynamic preferences from historical behaviors lies at the core of modern recommender systems. Due to the diverse nature of user interests, recent advances propose the multi-interest networks to encode historical behaviors into multiple interest vectors. In real scenarios, the corresponding items of captured interests are usually retrieved together to get exposure and collected into training data, which produces dependencies among interests. Unfortunately, multi-interest networks may incorrectly concentrate on subtle dependencies among captured interests. Misled by these dependencies, the spurious correlations between irrelevant interests and targets are captured, resulting in the instability of prediction results when training and test distributions do not match. In this paper, we introduce the widely used Hilbert-Schmidt Independence Criterion (HSIC) to measure the degree of independence among captured interests and empirically show that the continuous increase of HSIC may harm model performance. Based on this, we propose a novel multi-interest network, named DEep Stable Multi-Interest Learning (DESMIL), which tries to eliminate the influence of subtle dependencies among captured interests via learning weights for training samples and make model concentrate more on underlying true causation. We conduct extensive experiments on public recommendation datasets, a large-scale industrial dataset and the synthetic datasets which simulate the out-of-distribution data. Experimental results demonstrate that our proposed DESMIL outperforms state-of-the-art models by a significant margin. Besides, we also conduct comprehensive model analysis to reveal the reason why DESMIL works to a certain extent.