 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Multi-Interest Network with Stable Learning
Jul 14, 2022
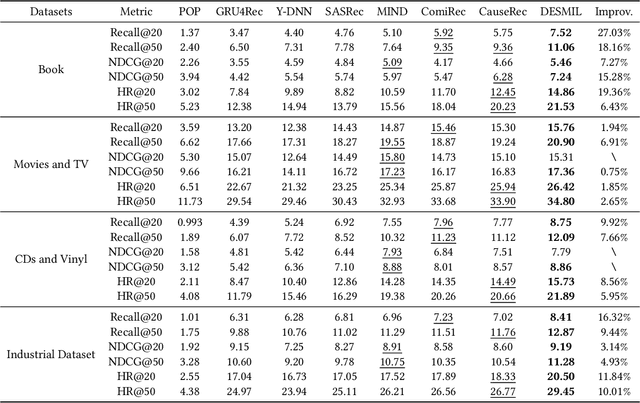
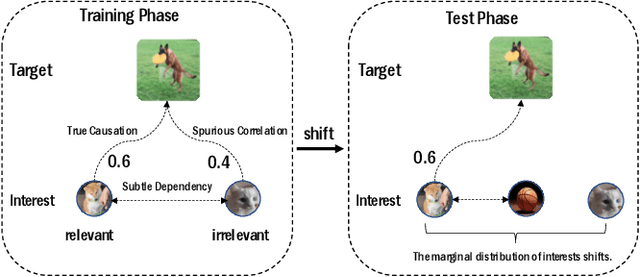

Modeling users' dynamic preferences from historical behaviors lies at the core of modern recommender systems. Due to the diverse nature of user interests, recent advances propose the multi-interest networks to encode historical behaviors into multiple interest vectors. In real scenarios, the corresponding items of captured interests are usually retrieved together to get exposure and collected into training data, which produces dependencies among interests. Unfortunately, multi-interest networks may incorrectly concentrate on subtle dependencies among captured interests. Misled by these dependencies, the spurious correlations between irrelevant interests and targets are captured, resulting in the instability of prediction results when training and test distributions do not match. In this paper, we introduce the widely used Hilbert-Schmidt Independence Criterion (HSIC) to measure the degree of independence among captured interests and empirically show that the continuous increase of HSIC may harm model performance. Based on this, we propose a novel multi-interest network, named DEep Stable Multi-Interest Learning (DESMIL), which tries to eliminate the influence of subtle dependencies among captured interests via learning weights for training samples and make model concentrate more on underlying true causation. We conduct extensive experiments on public recommendation datasets, a large-scale industrial dataset and the synthetic datasets which simulate the out-of-distribution data. Experimental results demonstrate that our proposed DESMIL outperforms state-of-the-art models by a significant margin. Besides, we also conduct comprehensive model analysis to reveal the reason why DESMIL works to a certain extent.
LPFS: Learnable Polarizing Feature Selection for Click-Through Rate Prediction
Jun 01, 2022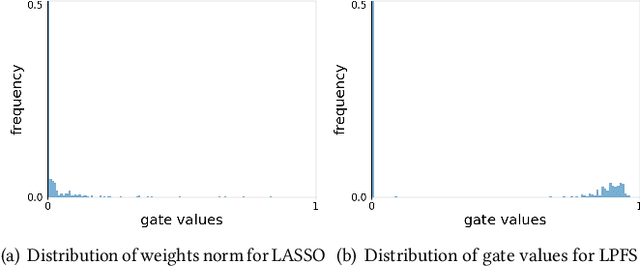
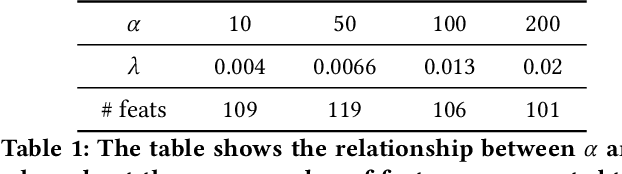
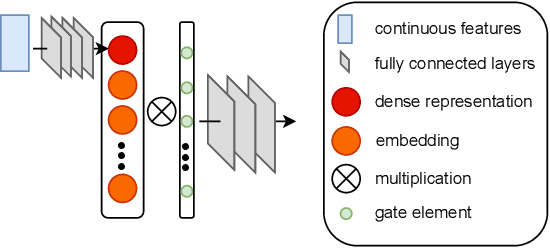

In industry, feature selection is a standard but necessary step to search for an optimal set of informative feature fields for efficient and effective training of deep Click-Through Rate (CTR) models. Most previous works measure the importance of feature fields by using their corresponding continuous weights from the model, then remove the feature fields with small weight values. However, removing many features that correspond to small but not exact zero weights will inevitably hurt model performance and not be friendly to hot-start model training. There is also no theoretical guarantee that the magnitude of weights can represent the importance, thus possibly leading to sub-optimal results if using these methods. To tackle this problem, we propose a novel Learnable Polarizing Feature Selection (LPFS) method using a smoothed-$\ell^0$ function in literature. Furthermore, we extend LPFS to LPFS++ by our newly designed smoothed-$\ell^0$-liked function to select a more informative subset of features. LPFS and LPFS++ can be used as gates inserted at the input of the deep network to control the active and inactive state of each feature. When training is finished, some gates are exact zero, while others are around one, which is particularly favored by the practical hot-start training in the industry, due to no damage to the model performance before and after removing the features corresponding to exact-zero gates. Experiments show that our methods outperform others by a clear margin, and have achieved great A/B test results in KuaiShou Technology.
Context-aware Tree-based Deep Model for Recommender Systems
Sep 22, 2021



How to predict precise user preference and how to make efficient retrieval from a big corpus are two major challenges of large-scale industrial recommender systems. In tree-based methods, a tree structure T is adopted as index and each item in corpus is attached to a leaf node on T . Then the recommendation problem is converted into a hierarchical retrieval problem solved by a beam search process efficiently. In this paper, we argue that the tree index used to support efficient retrieval in tree-based methods also has rich hierarchical information about the corpus. Furthermore, we propose a novel context-aware tree-based deep model (ConTDM) for recommender systems. In ConTDM, a context-aware user preference prediction model M is designed to utilize both horizontal and vertical contexts on T . Horizontally, a graph convolutional layer is used to enrich the representation of both users and nodes on T with their neighbors. Vertically, a parent fusion layer is designed in M to transmit the user preference representation in higher levels of T to the current level, grasping the essence that tree-based methods are generating the candidate set from coarse to detail during the beam search retrieval. Besides, we argue that the proposed user preference model in ConTDM can be conveniently extended to other tree-based methods for recommender systems. Both experiments on large scale real-world datasets and online A/B test in large scale industrial applications show the significant improvements brought by ConTDM.
Joint Optimization of Tree-based Index and Deep Model for Recommender Systems
Feb 19, 2019



Large-scale industrial recommender systems are usually confronted with computational problems due to the enormous corpus size. To retrieve and recommend the most relevant items to users under response time limits, resorting to an efficient index structure is an effective and practical solution. Tree-based Deep Model (TDM) for recommendation \cite{zhu2018learning} greatly improves recommendation accuracy using tree index. By indexing items in a tree hierarchy and training a user-node preference prediction model satisfying a max-heap like property in the tree, TDM provides logarithmic computational complexity w.r.t. the corpus size, enabling the use of arbitrary advanced models in candidate retrieval and recommendation. In tree-based recommendation methods, the quality of both the tree index and the trained user preference prediction model determines the recommendation accuracy for the most part. We argue that the learning of tree index and user preference model has interdependence. Our purpose, in this paper, is to develop a method to jointly learn the index structure and user preference prediction model. In our proposed joint optimization framework, the learning of index and user preference prediction model are carried out under a unified performance measure. Besides, we come up with a novel hierarchical user preference representation utilizing the tree index hierarchy. Experimental evaluations with two large-scale real-world datasets show that the proposed method improves recommendation accuracy significantly. Online A/B test results at Taobao display advertising also demonstrate the effectiveness of the proposed method in production environments.