 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicies over Poses: Reinforcement Learning based Distributed Pose-Graph Optimization for Multi-Robot SLAM
Oct 26, 2025



We consider the distributed pose-graph optimization (PGO) problem, which is fundamental in accurate trajectory estimation in multi-robot simultaneous localization and mapping (SLAM). Conventional iterative approaches linearize a highly non-convex optimization objective, requiring repeated solving of normal equations, which often converge to local minima and thus produce suboptimal estimates. We propose a scalable, outlier-robust distributed planar PGO framework using Multi-Agent Reinforcement Learning (MARL). We cast distributed PGO as a partially observable Markov game defined on local pose-graphs, where each action refines a single edge's pose estimate. A graph partitioner decomposes the global pose graph, and each robot runs a recurrent edge-conditioned Graph Neural Network (GNN) encoder with adaptive edge-gating to denoise noisy edges. Robots sequentially refine poses through a hybrid policy that utilizes prior action memory and graph embeddings. After local graph correction, a consensus scheme reconciles inter-robot disagreements to produce a globally consistent estimate. Our extensive evaluations on a comprehensive suite of synthetic and real-world datasets demonstrate that our learned MARL-based actors reduce the global objective by an average of 37.5% more than the state-of-the-art distributed PGO framework, while enhancing inference efficiency by at least 6X. We also demonstrate that actor replication allows a single learned policy to scale effortlessly to substantially larger robot teams without any retraining. Code is publicly available at https://github.com/herolab-uga/policies-over-poses.
Integrating Perceptions: A Human-Centered Physical Safety Model for Human-Robot Interaction
Jul 09, 2025Ensuring safety in human-robot interaction (HRI) is essential to foster user trust and enable the broader adoption of robotic systems. Traditional safety models primarily rely on sensor-based measures, such as relative distance and velocity, to assess physical safety. However, these models often fail to capture subjective safety perceptions, which are shaped by individual traits and contextual factors. In this paper, we introduce and analyze a parameterized general safety model that bridges the gap between physical and perceived safety by incorporating a personalization parameter, $\rho$, into the safety measurement framework to account for individual differences in safety perception. Through a series of hypothesis-driven human-subject studies in a simulated rescue scenario, we investigate how emotional state, trust, and robot behavior influence perceived safety. Our results show that $\rho$ effectively captures meaningful individual differences, driven by affective responses, trust in task consistency, and clustering into distinct user types. Specifically, our findings confirm that predictable and consistent robot behavior as well as the elicitation of positive emotional states, significantly enhance perceived safety. Moreover, responses cluster into a small number of user types, supporting adaptive personalization based on shared safety models. Notably, participant role significantly shapes safety perception, and repeated exposure reduces perceived safety for participants in the casualty role, emphasizing the impact of physical interaction and experiential change. These findings highlight the importance of adaptive, human-centered safety models that integrate both psychological and behavioral dimensions, offering a pathway toward more trustworthy and effective HRI in safety-critical domains.
Distributed Fault-Tolerant Multi-Robot Cooperative Localization in Adversarial Environments
Jul 09, 2025In multi-robot systems (MRS), cooperative localization is a crucial task for enhancing system robustness and scalability, especially in GPS-denied or communication-limited environments. However, adversarial attacks, such as sensor manipulation, and communication jamming, pose significant challenges to the performance of traditional localization methods. In this paper, we propose a novel distributed fault-tolerant cooperative localization framework to enhance resilience against sensor and communication disruptions in adversarial environments. We introduce an adaptive event-triggered communication strategy that dynamically adjusts communication thresholds based on real-time sensing and communication quality. This strategy ensures optimal performance even in the presence of sensor degradation or communication failure. Furthermore, we conduct a rigorous analysis of the convergence and stability properties of the proposed algorithm, demonstrating its resilience against bounded adversarial zones and maintaining accurate state estimation. Robotarium-based experiment results show that our proposed algorithm significantly outperforms traditional methods in terms of localization accuracy and communication efficiency, particularly in adversarial settings. Our approach offers improved scalability, reliability, and fault tolerance for MRS, making it suitable for large-scale deployments in real-world, challenging environments.
FRESHR-GSI: A Generalized Safety Model and Evaluation Framework for Mobile Robots in Multi-Human Environments
Jan 07, 2025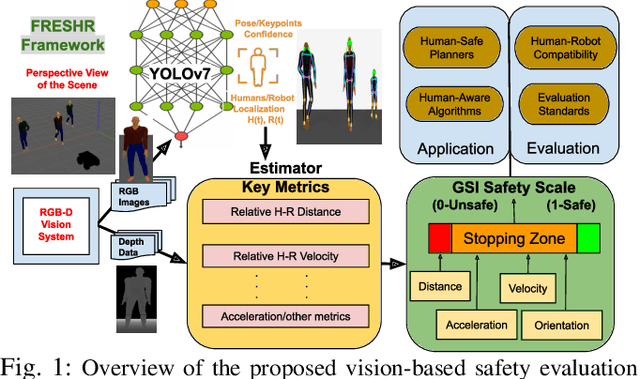
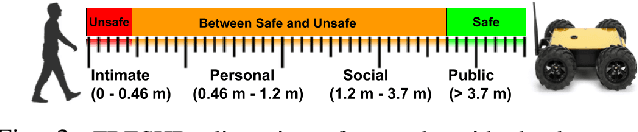
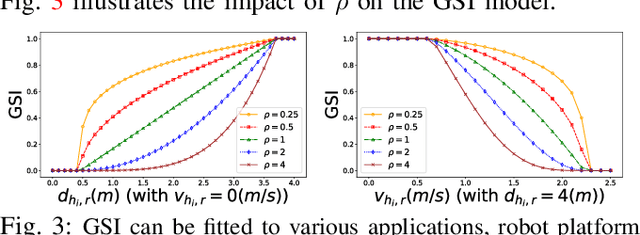
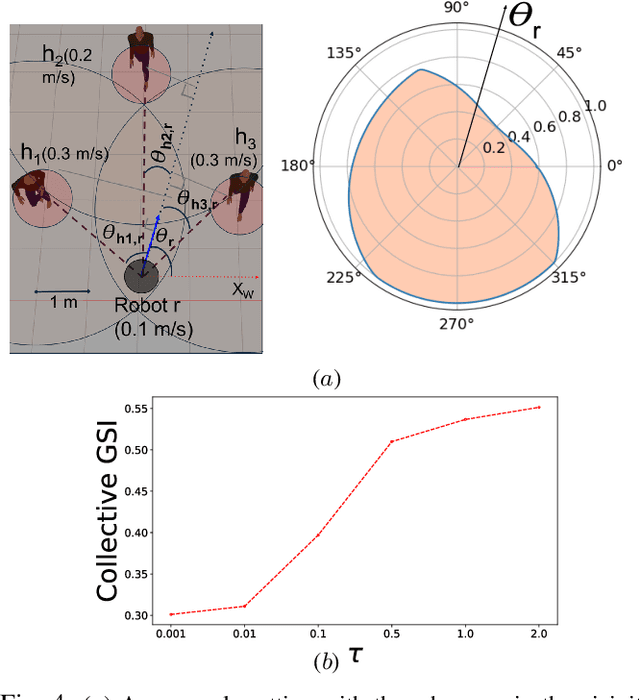
Human safety is critical in applications involving close human-robot interactions (HRI) and is a key aspect of physical compatibility between humans and robots. While measures of human safety in HRI exist, these mainly target industrial settings involving robotic manipulators. Less attention has been paid to settings where mobile robots and humans share the space. This paper introduces a new robot-centered directional framework of human safety. It is particularly useful for evaluating mobile robots as they operate in environments populated by multiple humans. The framework integrates several key metrics, such as each human's relative distance, speed, and orientation. The core novelty lies in the framework's flexibility to accommodate different application requirements while allowing for both the robot-centered and external observer points of view. We instantiate the framework by using RGB-D based vision integrated with a deep learning-based human detection pipeline to yield a generalized safety index (GSI) that instantaneously assesses human safety. We evaluate GSI's capability of producing appropriate, robust, and fine-grained safety measures in real-world experimental scenarios and compare its performance with extant safety models.
DCL-Sparse: Distributed Range-only Cooperative Localization of Multi-Robots in Noisy and Sparse Sensing Graphs
Dec 19, 2024



This paper presents a novel approach to range-based cooperative localization for robot swarms in GPS-denied environments, addressing the limitations of current methods in noisy and sparse settings. We propose a robust multi-layered localization framework that combines shadow edge localization techniques with the strategic deployment of UAVs. This approach not only addresses the challenges associated with nonrigid and poorly connected graphs but also enhances the convergence rate of the localization process. We introduce two key concepts: the S1-Edge approach in our distributed protocol to address the rigidity problem of sparse graphs and the concept of a powerful UAV node to increase the sensing and localization capability of the multi-robot system. Our approach leverages the advantages of the distributed localization methods, enhancing scalability and adaptability in large robot networks. We establish theoretical conditions for the new S1-Edge that ensure solutions exist even in the presence of noise, thereby validating the effectiveness of shadow edge localization. Extensive simulation experiments confirm the superior performance of our method compared to state-of-the-art techniques, resulting in up to 95\% reduction in localization error, demonstrating substantial improvements in localization accuracy and robustness to sparse graphs. This work provides a decisive advancement in the field of multi-robot localization, offering a powerful tool for high-performance and reliable operations in challenging environments.
SPACE: 3D Spatial Co-operation and Exploration Framework for Robust Mapping and Coverage with Multi-Robot Systems
Nov 04, 2024



In indoor environments, multi-robot visual (RGB-D) mapping and exploration hold immense potential for application in domains such as domestic service and logistics, where deploying multiple robots in the same environment can significantly enhance efficiency. However, there are two primary challenges: (1) the "ghosting trail" effect, which occurs due to overlapping views of robots impacting the accuracy and quality of point cloud reconstruction, and (2) the oversight of visual reconstructions in selecting the most effective frontiers for exploration. Given these challenges are interrelated, we address them together by proposing a new semi-distributed framework (SPACE) for spatial cooperation in indoor environments that enables enhanced coverage and 3D mapping. SPACE leverages geometric techniques, including "mutual awareness" and a "dynamic robot filter," to overcome spatial mapping constraints. Additionally, we introduce a novel spatial frontier detection system and map merger, integrated with an adaptive frontier assigner for optimal coverage balancing the exploration and reconstruction objectives. In extensive ROS-Gazebo simulations, SPACE demonstrated superior performance over state-of-the-art approaches in both exploration and mapping metrics.
Energy-Aware Coverage Planning for Heterogeneous Multi-Robot System
Nov 04, 2024



We propose a distributed control law for a heterogeneous multi-robot coverage problem, where the robots could have different energy characteristics, such as capacity and depletion rates, due to their varying sizes, speeds, capabilities, and payloads. Existing energy-aware coverage control laws consider capacity differences but assume the battery depletion rate to be the same for all robots. In realistic scenarios, however, some robots can consume energy much faster than other robots; for instance, UAVs hover at different altitudes, and these changes could be dynamically updated based on their assigned tasks. Robots' energy capacities and depletion rates need to be considered to maximize the performance of a multi-robot system. To this end, we propose a new energy-aware controller based on Lloyd's algorithm to adapt the weights of the robots based on their energy dynamics and divide the area of interest among the robots accordingly. The controller is theoretically analyzed and extensively evaluated through simulations and real-world demonstrations in multiple realistic scenarios and compared with three baseline control laws to validate its performance and efficacy.
Analyzing Human Perceptions of a MEDEVAC Robot in a Simulated Evacuation Scenario
Oct 24, 2024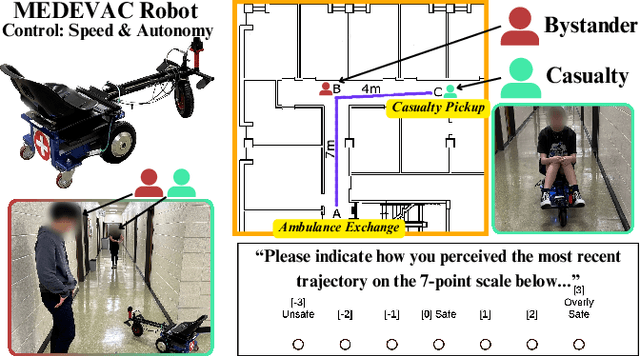
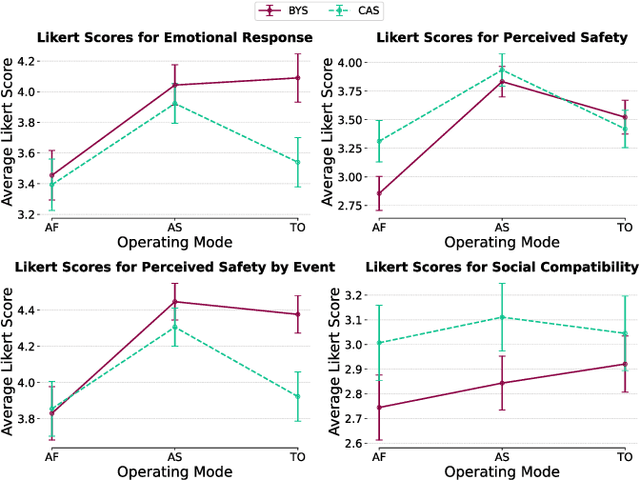
The use of autonomous systems in medical evacuation (MEDEVAC) scenarios is promising, but existing implementations overlook key insights from human-robot interaction (HRI) research. Studies on human-machine teams demonstrate that human perceptions of a machine teammate are critical in governing the machine's performance. Here, we present a mixed factorial design to assess human perceptions of a MEDEVAC robot in a simulated evacuation scenario. Participants were assigned to the role of casualty (CAS) or bystander (BYS) and subjected to three within-subjects conditions based on the MEDEVAC robot's operating mode: autonomous-slow (AS), autonomous-fast (AF), and teleoperation (TO). During each trial, a MEDEVAC robot navigated an 11-meter path, acquiring a casualty and transporting them to an ambulance exchange point while avoiding an idle bystander. Following each trial, subjects completed a questionnaire measuring their emotional states, perceived safety, and social compatibility with the robot. Results indicate a consistent main effect of operating mode on reported emotional states and perceived safety. Pairwise analyses suggest that the employment of the AF operating mode negatively impacted perceptions along these dimensions. There were no persistent differences between casualty and bystander responses.
Communication-Aware Consistent Edge Selection for Mobile Users and Autonomous Vehicles
Aug 06, 2024Offloading time-sensitive, computationally intensive tasks-such as advanced learning algorithms for autonomous driving-from vehicles to nearby edge servers, vehicle-to-infrastructure (V2I) systems, or other collaborating vehicles via vehicle-to-vehicle (V2V) communication enhances service efficiency. However, whence traversing the path to the destination, the vehicle's mobility necessitates frequent handovers among the access points (APs) to maintain continuous and uninterrupted wireless connections to maintain the network's Quality of Service (QoS). These frequent handovers subsequently lead to task migrations among the edge servers associated with the respective APs. This paper addresses the joint problem of task migration and access-point handover by proposing a deep reinforcement learning framework based on the Deep Deterministic Policy Gradient (DDPG) algorithm. A joint allocation method of communication and computation of APs is proposed to minimize computational load, service latency, and interruptions with the overarching goal of maximizing QoS. We implement and evaluate our proposed framework on simulated experiments to achieve smooth and seamless task switching among edge servers, ultimately reducing latency.
Anchor-Oriented Localized Voronoi Partitioning for GPS-denied Multi-Robot Coverage
Jul 08, 2024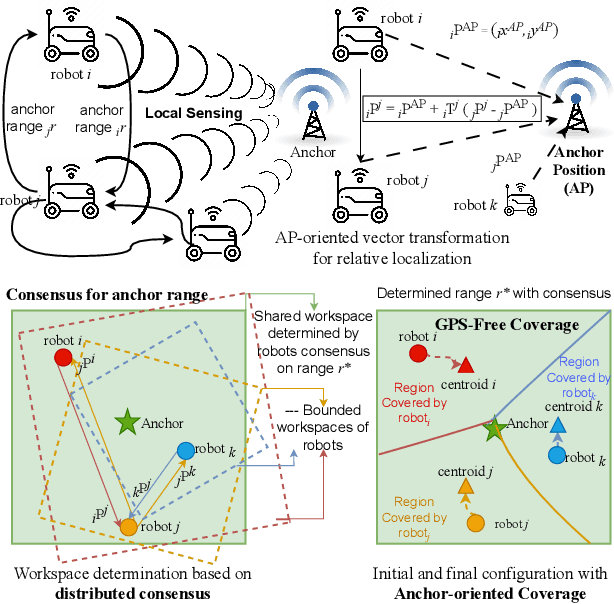
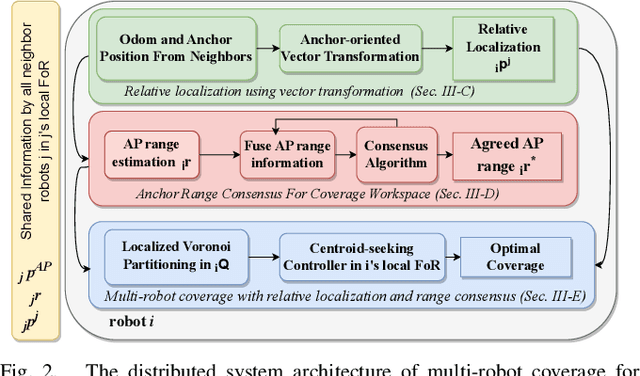


Multi-robot coverage is crucial in numerous applications, including environmental monitoring, search and rescue operations, and precision agriculture. In modern applications, a multi-robot team must collaboratively explore unknown spatial fields in GPS-denied and extreme environments where global localization is unavailable. Coverage algorithms typically assume that the robot positions and the coverage environment are defined in a global reference frame. However, coordinating robot motion and ensuring coverage of the shared convex workspace without global localization is challenging. This paper proposes a novel anchor-oriented coverage (AOC) approach to generate dynamic localized Voronoi partitions based around a common anchor position. We further propose a consensus-based coordination algorithm that achieves agreement on the coverage workspace around the anchor in the robots' relative frames of reference. Through extensive simulations and real-world experiments, we demonstrate that the proposed anchor-oriented approach using localized Voronoi partitioning performs as well as the state-of-the-art coverage controller using GPS.