 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCMM-Transformer: Degree-Corrected Mixed-Membership Attention for Medical Imaging
Nov 15, 2025Medical images exhibit latent anatomical groupings, such as organs, tissues, and pathological regions, that standard Vision Transformers (ViTs) fail to exploit. While recent work like SBM-Transformer attempts to incorporate such structures through stochastic binary masking, they suffer from non-differentiability, training instability, and the inability to model complex community structure. We present DCMM-Transformer, a novel ViT architecture for medical image analysis that incorporates a Degree-Corrected Mixed-Membership (DCMM) model as an additive bias in self-attention. Unlike prior approaches that rely on multiplicative masking and binary sampling, our method introduces community structure and degree heterogeneity in a fully differentiable and interpretable manner. Comprehensive experiments across diverse medical imaging datasets, including brain, chest, breast, and ocular modalities, demonstrate the superior performance and generalizability of the proposed approach. Furthermore, the learned group structure and structured attention modulation substantially enhance interpretability by yielding attention maps that are anatomically meaningful and semantically coherent.
S2MNet: Speckle-To-Mesh Net for Three-Dimensional Cardiac Morphology Reconstruction via Echocardiogram
May 09, 2025Echocardiogram is the most commonly used imaging modality in cardiac assessment duo to its non-invasive nature, real-time capability, and cost-effectiveness. Despite its advantages, most clinical echocardiograms provide only two-dimensional views, limiting the ability to fully assess cardiac anatomy and function in three dimensions. While three-dimensional echocardiography exists, it often suffers from reduced resolution, limited availability, and higher acquisition costs. To overcome these challenges, we propose a deep learning framework S2MNet that reconstructs continuous and high-fidelity 3D heart models by integrating six slices of routinely acquired 2D echocardiogram views. Our method has three advantages. First, our method avoid the difficulties on training data acquasition by simulate six of 2D echocardiogram images from corresponding slices of a given 3D heart mesh. Second, we introduce a deformation field-based method, which avoid spatial discontinuities or structural artifacts in 3D echocardiogram reconstructions. We validate our method using clinically collected echocardiogram and demonstrate that our estimated left ventricular volume, a key clinical indicator of cardiac function, is strongly correlated with the doctor measured GLPS, a clinical measurement that should demonstrate a negative correlation with LVE in medical theory. This association confirms the reliability of our proposed 3D construction method.
Knowledge Distillation and Dataset Distillation of Large Language Models: Emerging Trends, Challenges, and Future Directions
Apr 20, 2025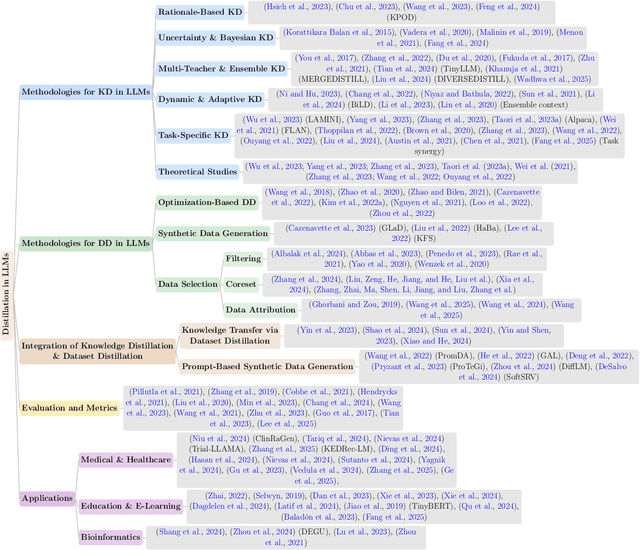
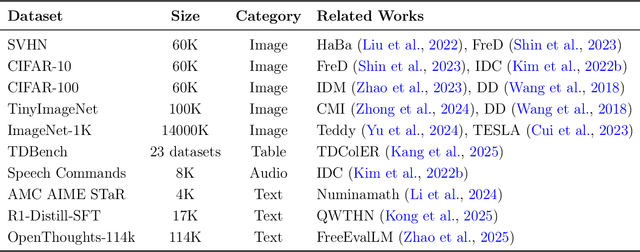
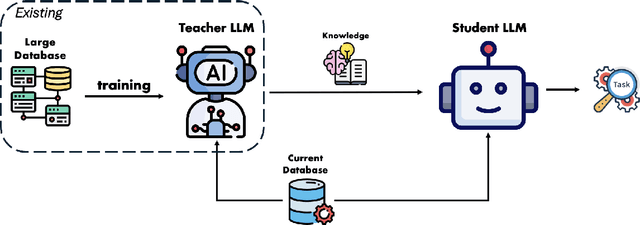

The exponential growth of Large Language Models (LLMs) continues to highlight the need for efficient strategies to meet ever-expanding computational and data demands. This survey provides a comprehensive analysis of two complementary paradigms: Knowledge Distillation (KD) and Dataset Distillation (DD), both aimed at compressing LLMs while preserving their advanced reasoning capabilities and linguistic diversity. We first examine key methodologies in KD, such as task-specific alignment, rationale-based training, and multi-teacher frameworks, alongside DD techniques that synthesize compact, high-impact datasets through optimization-based gradient matching, latent space regularization, and generative synthesis. Building on these foundations, we explore how integrating KD and DD can produce more effective and scalable compression strategies. Together, these approaches address persistent challenges in model scalability, architectural heterogeneity, and the preservation of emergent LLM abilities. We further highlight applications across domains such as healthcare and education, where distillation enables efficient deployment without sacrificing performance. Despite substantial progress, open challenges remain in preserving emergent reasoning and linguistic diversity, enabling efficient adaptation to continually evolving teacher models and datasets, and establishing comprehensive evaluation protocols. By synthesizing methodological innovations, theoretical foundations, and practical insights, our survey charts a path toward sustainable, resource-efficient LLMs through the tighter integration of KD and DD principles.
Interpretation of Time-Series Deep Models: A Survey
May 23, 2023
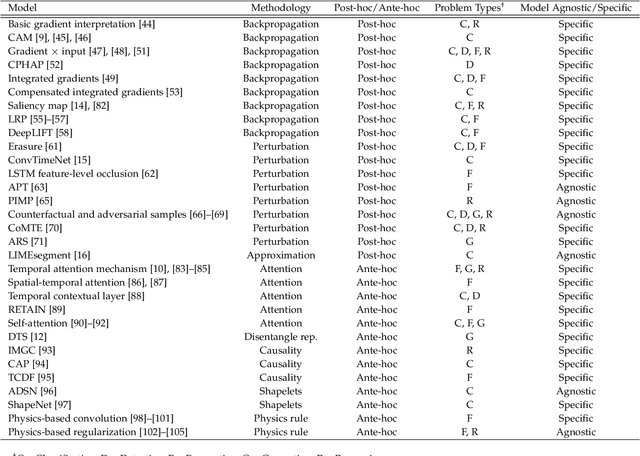
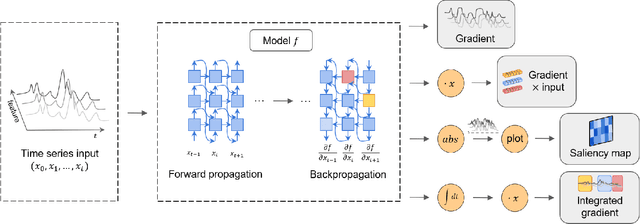
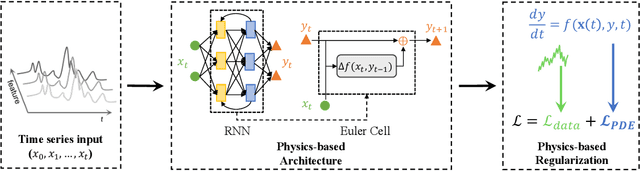
Deep learning models developed for time-series associated tasks have become more widely researched nowadays. However, due to the unintuitive nature of time-series data, the interpretability problem -- where we understand what is under the hood of these models -- becomes crucial. The advancement of similar studies in computer vision has given rise to many post-hoc methods, which can also shed light on how to explain time-series models. In this paper, we present a wide range of post-hoc interpretation methods for time-series models based on backpropagation, perturbation, and approximation. We also want to bring focus onto inherently interpretable models, a novel category of interpretation where human-understandable information is designed within the models. Furthermore, we introduce some common evaluation metrics used for the explanations, and propose several directions of future researches on the time-series interpretability problem. As a highlight, our work summarizes not only the well-established interpretation methods, but also a handful of fairly recent and under-developed techniques, which we hope to capture their essence and spark future endeavours to innovate and improvise.