 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCMM-Transformer: Degree-Corrected Mixed-Membership Attention for Medical Imaging
Nov 15, 2025Medical images exhibit latent anatomical groupings, such as organs, tissues, and pathological regions, that standard Vision Transformers (ViTs) fail to exploit. While recent work like SBM-Transformer attempts to incorporate such structures through stochastic binary masking, they suffer from non-differentiability, training instability, and the inability to model complex community structure. We present DCMM-Transformer, a novel ViT architecture for medical image analysis that incorporates a Degree-Corrected Mixed-Membership (DCMM) model as an additive bias in self-attention. Unlike prior approaches that rely on multiplicative masking and binary sampling, our method introduces community structure and degree heterogeneity in a fully differentiable and interpretable manner. Comprehensive experiments across diverse medical imaging datasets, including brain, chest, breast, and ocular modalities, demonstrate the superior performance and generalizability of the proposed approach. Furthermore, the learned group structure and structured attention modulation substantially enhance interpretability by yielding attention maps that are anatomically meaningful and semantically coherent.
Knowledge Distillation and Dataset Distillation of Large Language Models: Emerging Trends, Challenges, and Future Directions
Apr 20, 2025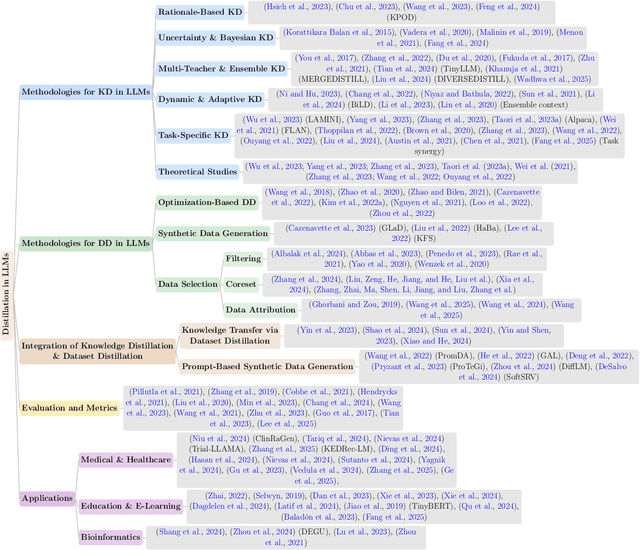
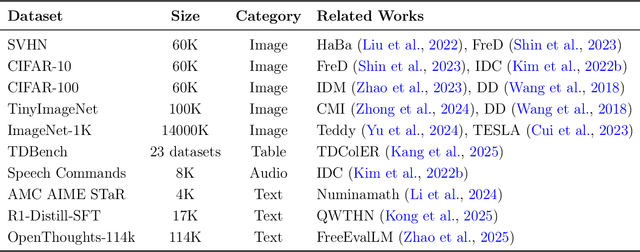
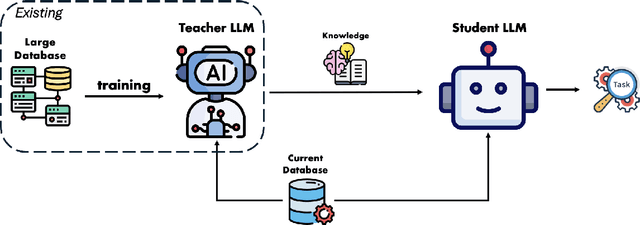

The exponential growth of Large Language Models (LLMs) continues to highlight the need for efficient strategies to meet ever-expanding computational and data demands. This survey provides a comprehensive analysis of two complementary paradigms: Knowledge Distillation (KD) and Dataset Distillation (DD), both aimed at compressing LLMs while preserving their advanced reasoning capabilities and linguistic diversity. We first examine key methodologies in KD, such as task-specific alignment, rationale-based training, and multi-teacher frameworks, alongside DD techniques that synthesize compact, high-impact datasets through optimization-based gradient matching, latent space regularization, and generative synthesis. Building on these foundations, we explore how integrating KD and DD can produce more effective and scalable compression strategies. Together, these approaches address persistent challenges in model scalability, architectural heterogeneity, and the preservation of emergent LLM abilities. We further highlight applications across domains such as healthcare and education, where distillation enables efficient deployment without sacrificing performance. Despite substantial progress, open challenges remain in preserving emergent reasoning and linguistic diversity, enabling efficient adaptation to continually evolving teacher models and datasets, and establishing comprehensive evaluation protocols. By synthesizing methodological innovations, theoretical foundations, and practical insights, our survey charts a path toward sustainable, resource-efficient LLMs through the tighter integration of KD and DD principles.
Efficient Multi-Task Inferencing: Model Merging with Gromov-Wasserstein Feature Alignment
Mar 12, 2025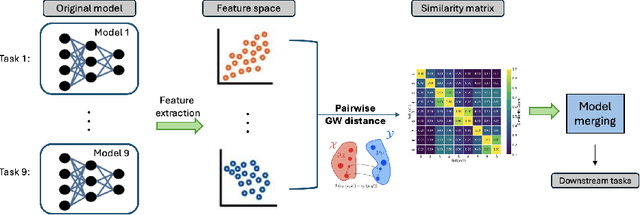

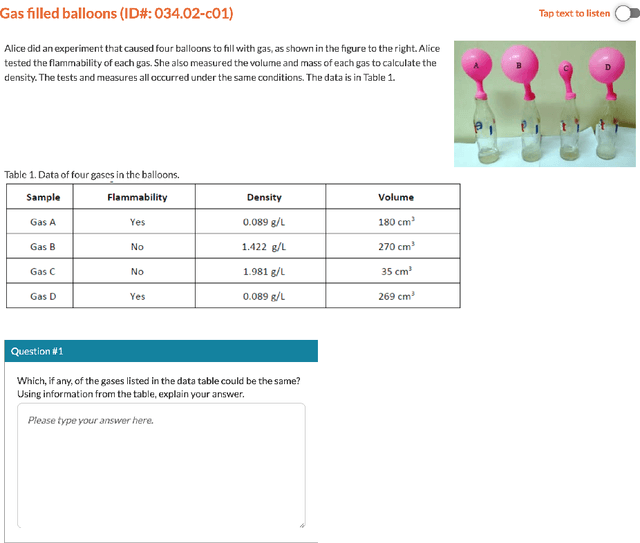

Automatic scoring of student responses enhances efficiency in education, but deploying a separate neural network for each task increases storage demands, maintenance efforts, and redundant computations. To address these challenges, this paper introduces the Gromov-Wasserstein Scoring Model Merging (GW-SMM) method, which merges models based on feature distribution similarities measured via the Gromov-Wasserstein distance. Our approach begins by extracting features from student responses using individual models, capturing both item-specific context and unique learned representations. The Gromov-Wasserstein distance then quantifies the similarity between these feature distributions, identifying the most compatible models for merging. Models exhibiting the smallest pairwise distances, typically in pairs or trios, are merged by combining only the shared layers preceding the classification head. This strategy results in a unified feature extractor while preserving separate classification heads for item-specific scoring. We validated our approach against human expert knowledge and a GPT-o1-based merging method. GW-SMM consistently outperformed both, achieving a higher micro F1 score, macro F1 score, exact match accuracy, and per-label accuracy. The improvements in micro F1 and per-label accuracy were statistically significant compared to GPT-o1-based merging (p=0.04, p=0.01). Additionally, GW-SMM reduced storage requirements by half without compromising much accuracy, demonstrating its computational efficiency alongside reliable scoring performance.
Large Language Models for Bioinformatics
Jan 10, 2025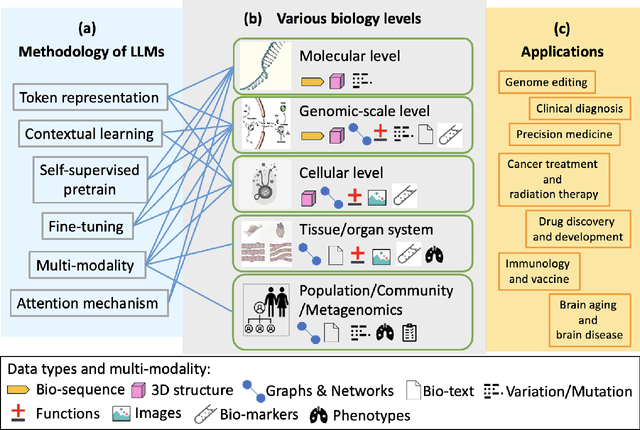
With the rapid advancements in large language model (LLM) technology and the emergence of bioinformatics-specific language models (BioLMs), there is a growing need for a comprehensive analysis of the current landscape, computational characteristics, and diverse applications. This survey aims to address this need by providing a thorough review of BioLMs, focusing on their evolution, classification, and distinguishing features, alongside a detailed examination of training methodologies, datasets, and evaluation frameworks. We explore the wide-ranging applications of BioLMs in critical areas such as disease diagnosis, drug discovery, and vaccine development, highlighting their impact and transformative potential in bioinformatics. We identify key challenges and limitations inherent in BioLMs, including data privacy and security concerns, interpretability issues, biases in training data and model outputs, and domain adaptation complexities. Finally, we highlight emerging trends and future directions, offering valuable insights to guide researchers and clinicians toward advancing BioLMs for increasingly sophisticated biological and clinical applications.
Knowledge Distillation of LLM for Education
Dec 26, 2023


This study proposes a method for distilling the knowledge of fine-tuned Large Language Models (LLMs) into a smaller, more efficient, and accurate neural network, specifically targeting the challenge of deploying these models on resource-constrained devices. Our methodology involves training the smaller student model using the prediction probabilities of the LLM, which serves as a teacher model. This is achieved through a specialized loss function tailored to learn from the LLM's output probabilities, ensuring that the student model closely mimics the teacher's performance. To test this approach, we utilized a large dataset, 7T, containing 6,684 student-written responses to science questions and three other datasets with student-written responses. We also compared performance with original neural network (NN) models to validate the accuracy. Results have shown that the NN and distilled student models have comparable accuracy to the teacher model for the 7T dataset; however, other datasets have shown significantly lower accuracy (28% on average) for NN, though our proposed distilled model is still able to achieve 12\% higher accuracy than NN. Furthermore, the student model size ranges from 0.1M to 0.02M, 100 times smaller in terms of parameters and ten times smaller compared with the original output model size. The significance of this research lies in its potential to make advanced AI technologies accessible in typical educational settings, particularly for automatic scoring.
Using GPT-4 to Augment Unbalanced Data for Automatic Scoring
Oct 25, 2023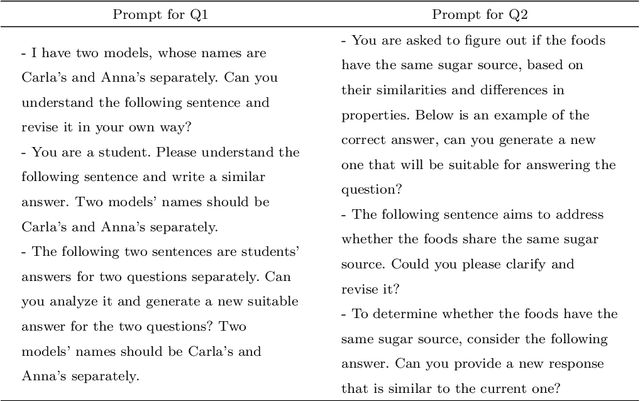



Machine learning-based automatic scoring can be challenging if students' responses are unbalanced across scoring categories, as it introduces uncertainty in the machine training process. To meet this challenge, we introduce a novel text data augmentation framework leveraging GPT-4, a generative large language model, specifically tailored for unbalanced datasets in automatic scoring. Our experimental dataset comprised student written responses to two science items. We crafted prompts for GPT-4 to generate responses resembling student written answers, particularly for the minority scoring classes, to augment the data. We then finetuned DistillBERT for automatic scoring based on the augmented and original datasets. Model performance was assessed using accuracy, precision, recall, and F1 metrics. Our findings revealed that incorporating GPT-4-augmented data remarkedly improved model performance, particularly for precision, recall, and F1 scores. Interestingly, the extent of improvement varied depending on the specific dataset and the proportion of augmented data used. Notably, we found that a varying amount of augmented data (5\%-40\%) was needed to obtain stable improvement for automatic scoring. We also compared the accuracies of models trained with GPT-4 augmented data to those trained with additional student-written responses. Results suggest that the GPT-4 augmented scoring models outperform or match the models trained with student-written augmented data. This research underscores the potential and effectiveness of data augmentation techniques utilizing generative large language models--GPT-4 in addressing unbalanced datasets within automated assessment.