 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealizing Visual Question Answering for Education: GPT-4V as a Multimodal AI
May 12, 2024
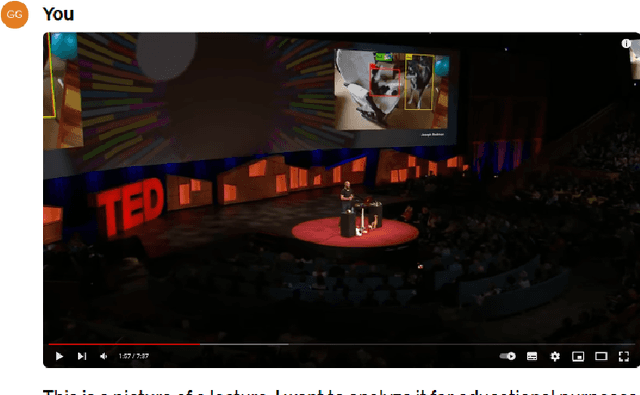

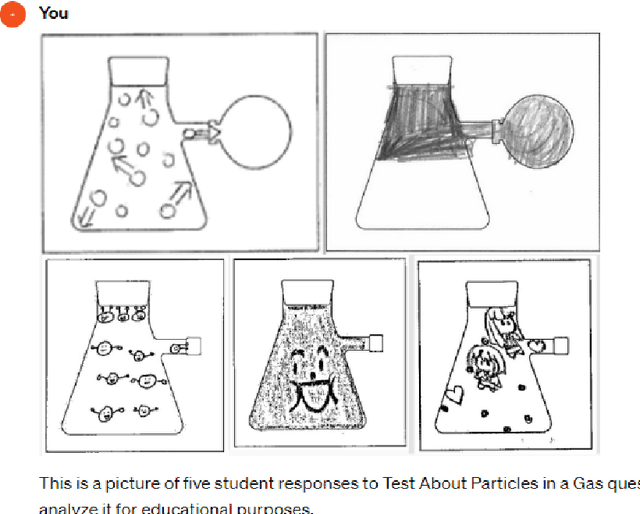
Educational scholars have analyzed various image data acquired from teaching and learning situations, such as photos that shows classroom dynamics, students' drawings with regard to the learning content, textbook illustrations, etc. Unquestioningly, most qualitative analysis of and explanation on image data have been conducted by human researchers, without machine-based automation. It was partially because most image processing artificial intelligence models were not accessible to general educational scholars or explainable due to their complex deep neural network architecture. However, the recent development of Visual Question Answering (VQA) techniques is accomplishing usable visual language models, which receive from the user a question about the given image and returns an answer, both in natural language. Particularly, GPT-4V released by OpenAI, has wide opened the state-of-the-art visual langauge model service so that VQA could be used for a variety of purposes. However, VQA and GPT-4V have not yet been applied to educational studies much. In this position paper, we suggest that GPT-4V contributes to realizing VQA for education. By 'realizing' VQA, we denote two meanings: (1) GPT-4V realizes the utilization of VQA techniques by any educational scholars without technical/accessibility barrier, and (2) GPT-4V makes educational scholars realize the usefulness of VQA to educational research. Given these, this paper aims to introduce VQA for educational studies so that it provides a milestone for educational research methodology. In this paper, chapter II reviews the development of VQA techniques, which primes with the release of GPT-4V. Chapter III reviews the use of image analysis in educational studies. Chapter IV demonstrates how GPT-4V can be used for each research usage reviewed in Chapter III, with operating prompts provided. Finally, chapter V discusses the future implications.
G-SciEdBERT: A Contextualized LLM for Science Assessment Tasks in German
Feb 09, 2024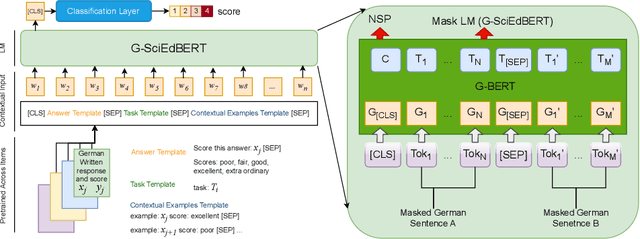
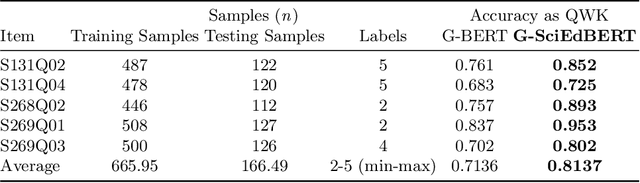
The advancement of natural language processing has paved the way for automated scoring systems in various languages, such as German (e.g., German BERT [G-BERT]). Automatically scoring written responses to science questions in German is a complex task and challenging for standard G-BERT as they lack contextual knowledge in the science domain and may be unaligned with student writing styles. This paper developed a contextualized German Science Education BERT (G-SciEdBERT), an innovative large language model tailored for scoring German-written responses to science tasks. Using G-BERT, we pre-trained G-SciEdBERT on a corpus of 50K German written science responses with 5M tokens to the Programme for International Student Assessment (PISA) 2015. We fine-tuned G-SciEdBERT on 59 assessment items and examined the scoring accuracy. We then compared its performance with G-BERT. Our findings reveal a substantial improvement in scoring accuracy with G-SciEdBERT, demonstrating a 10% increase of quadratic weighted kappa compared to G-BERT (mean accuracy difference = 0.096, SD = 0.024). These insights underline the significance of specialized language models like G-SciEdBERT, which is trained to enhance the accuracy of automated scoring, offering a substantial contribution to the field of AI in education.
Collaborative Learning with Artificial Intelligence Speakers (CLAIS): Pre-Service Elementary Science Teachers' Responses to the Prototype
Dec 20, 2023This research aims to demonstrate that AI can function not only as a tool for learning, but also as an intelligent agent with which humans can engage in collaborative learning (CL) to change epistemic practices in science classrooms. We adopted a design and development research approach, following the Analysis, Design, Development, Implementation and Evaluation (ADDIE) model, to prototype a tangible instructional system called Collaborative Learning with AI Speakers (CLAIS). The CLAIS system is designed to have 3-4 human learners join an AI speaker to form a small group, where humans and AI are considered as peers participating in the Jigsaw learning process. The development was carried out using the NUGU AI speaker platform. The CLAIS system was successfully implemented in a Science Education course session with 15 pre-service elementary science teachers. The participants evaluated the CLAIS system through mixed methods surveys as teachers, learners, peers, and users. Quantitative data showed that the participants' Intelligent-Technological, Pedagogical, And Content Knowledge was significantly increased after the CLAIS session, the perception of the CLAIS learning experience was positive, the peer assessment on AI speakers and human peers was different, and the user experience was ambivalent. Qualitative data showed that the participants anticipated future changes in the epistemic process in science classrooms, while acknowledging technical issues such as speech recognition performance and response latency. This study highlights the potential of Human-AI Collaboration for knowledge co-construction in authentic classroom settings and exemplify how AI could shape the future landscape of epistemic practices in the classroom.
Multimodality of AI for Education: Towards Artificial General Intelligence
Dec 12, 2023

This paper presents a comprehensive examination of how multimodal artificial intelligence (AI) approaches are paving the way towards the realization of Artificial General Intelligence (AGI) in educational contexts. It scrutinizes the evolution and integration of AI in educational systems, emphasizing the crucial role of multimodality, which encompasses auditory, visual, kinesthetic, and linguistic modes of learning. This research delves deeply into the key facets of AGI, including cognitive frameworks, advanced knowledge representation, adaptive learning mechanisms, strategic planning, sophisticated language processing, and the integration of diverse multimodal data sources. It critically assesses AGI's transformative potential in reshaping educational paradigms, focusing on enhancing teaching and learning effectiveness, filling gaps in existing methodologies, and addressing ethical considerations and responsible usage of AGI in educational settings. The paper also discusses the implications of multimodal AI's role in education, offering insights into future directions and challenges in AGI development. This exploration aims to provide a nuanced understanding of the intersection between AI, multimodality, and education, setting a foundation for future research and development in AGI.
Applying Large Language Models and Chain-of-Thought for Automatic Scoring
Nov 30, 2023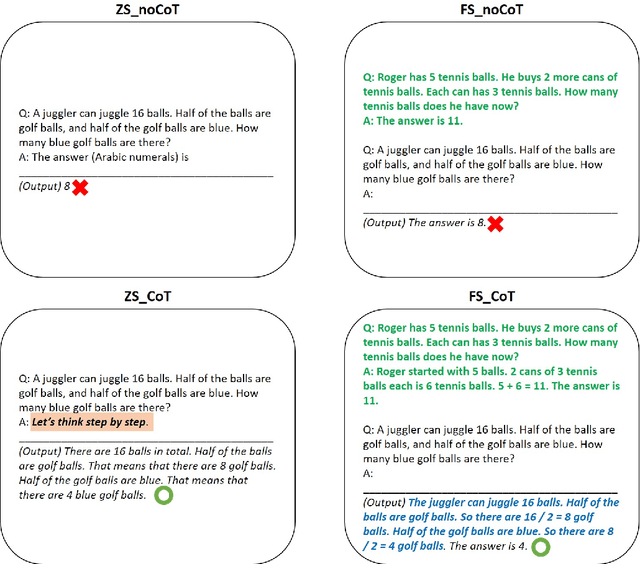
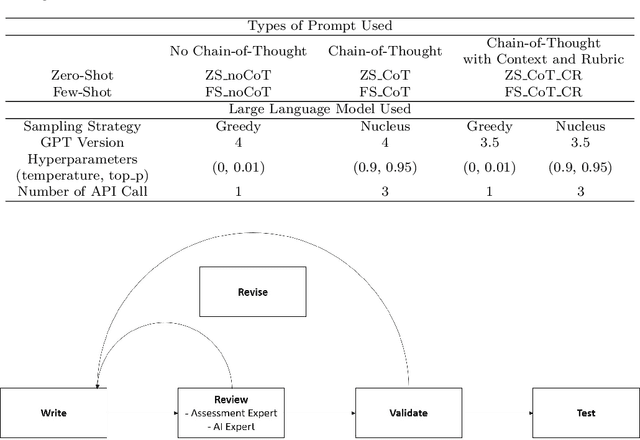

This study investigates the application of large language models (LLMs), specifically GPT-3.5 and GPT-4, with Chain-of-Though (CoT)in the automatic scoring of student-written responses to science assessments. We focused on overcoming the challenges of accessibility, technical complexity, and lack of explainability that have previously limited the use of automatic assessment tools among researchers and educators. We used a testing dataset comprising six assessment tasks (three binomial and three trinomial) with 1,650 student responses. We employed six prompt engineering strategies, combining zero-shot or few-shot learning with CoT, either alone or alongside item stem and scoring rubrics. Results indicated that few-shot (acc = .67) outperformed zero-shot learning (acc = .60), with 12.6\% increase. CoT, when used without item stem and scoring rubrics, did not significantly affect scoring accuracy (acc = .60). However, CoT prompting paired with contextual item stems and rubrics proved to be a significant contributor to scoring accuracy (13.44\% increase for zero-shot; 3.7\% increase for few-shot). Using a novel approach PPEAS, we found a more balanced accuracy across different proficiency categories, highlighting the importance of domain-specific reasoning in enhancing the effectiveness of LLMs in scoring tasks. Additionally, we also found that GPT-4 demonstrated superior performance over GPT-3.5 in various scoring tasks, showing 8.64\% difference. The study revealed that the single-call strategy with GPT-4, particularly using greedy sampling, outperformed other approaches, including ensemble voting strategies. This study demonstrates the potential of LLMs in facilitating automatic scoring, emphasizing that CoT enhances accuracy, particularly when used with item stem and scoring rubrics.
NERIF: GPT-4V for Automatic Scoring of Drawn Models
Nov 21, 2023


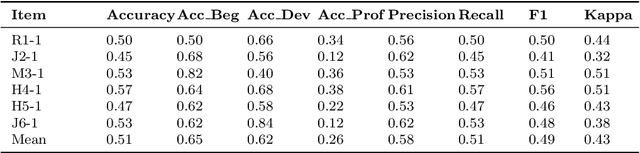
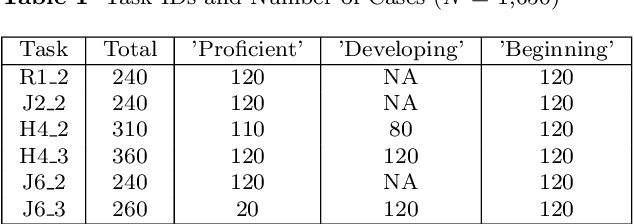
Scoring student-drawn models is time-consuming. Recently released GPT-4V provides a unique opportunity to advance scientific modeling practices by leveraging the powerful image processing capability. To test this ability specifically for automatic scoring, we developed a method NERIF (Notation-Enhanced Rubric Instruction for Few-shot Learning) employing instructional note and rubrics to prompt GPT-4V to score students' drawn models for science phenomena. We randomly selected a set of balanced data (N = 900) that includes student-drawn models for six modeling assessment tasks. Each model received a score from GPT-4V ranging at three levels: 'Beginning,' 'Developing,' or 'Proficient' according to scoring rubrics. GPT-4V scores were compared with human experts' scores to calculate scoring accuracy. Results show that GPT-4V's average scoring accuracy was mean =.51, SD = .037. Specifically, average scoring accuracy was .64 for the 'Beginning' class, .62 for the 'Developing' class, and .26 for the 'Proficient' class, indicating that more proficient models are more challenging to score. Further qualitative study reveals how GPT-4V retrieves information from image input, including problem context, example evaluations provided by human coders, and students' drawing models. We also uncovered how GPT-4V catches the characteristics of student-drawn models and narrates them in natural language. At last, we demonstrated how GPT-4V assigns scores to student-drawn models according to the given scoring rubric and instructional notes. Our findings suggest that the NERIF is an effective approach for employing GPT-4V to score drawn models. Even though there is space for GPT-4V to improve scoring accuracy, some mis-assigned scores seemed interpretable to experts. The results of this study show that utilizing GPT-4V for automatic scoring of student-drawn models is promising.
Using GPT-4 to Augment Unbalanced Data for Automatic Scoring
Oct 25, 2023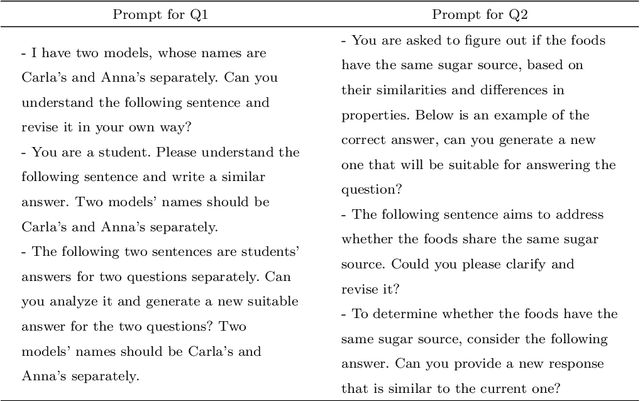



Machine learning-based automatic scoring can be challenging if students' responses are unbalanced across scoring categories, as it introduces uncertainty in the machine training process. To meet this challenge, we introduce a novel text data augmentation framework leveraging GPT-4, a generative large language model, specifically tailored for unbalanced datasets in automatic scoring. Our experimental dataset comprised student written responses to two science items. We crafted prompts for GPT-4 to generate responses resembling student written answers, particularly for the minority scoring classes, to augment the data. We then finetuned DistillBERT for automatic scoring based on the augmented and original datasets. Model performance was assessed using accuracy, precision, recall, and F1 metrics. Our findings revealed that incorporating GPT-4-augmented data remarkedly improved model performance, particularly for precision, recall, and F1 scores. Interestingly, the extent of improvement varied depending on the specific dataset and the proportion of augmented data used. Notably, we found that a varying amount of augmented data (5\%-40\%) was needed to obtain stable improvement for automatic scoring. We also compared the accuracies of models trained with GPT-4 augmented data to those trained with additional student-written responses. Results suggest that the GPT-4 augmented scoring models outperform or match the models trained with student-written augmented data. This research underscores the potential and effectiveness of data augmentation techniques utilizing generative large language models--GPT-4 in addressing unbalanced datasets within automated assessment.
Elucidating STEM Concepts through Generative AI: A Multi-modal Exploration of Analogical Reasoning
Aug 21, 2023

This study explores the integration of generative artificial intelligence (AI), specifically large language models, with multi-modal analogical reasoning as an innovative approach to enhance science, technology, engineering, and mathematics (STEM) education. We have developed a novel system that utilizes the capacities of generative AI to transform intricate principles in mathematics, physics, and programming into comprehensible metaphors. To further augment the educational experience, these metaphors are subsequently converted into visual form. Our study aims to enhance the learners' understanding of STEM concepts and their learning engagement by using the visual metaphors. We examine the efficacy of our system via a randomized A/B/C test, assessing learning gains and motivation shifts among the learners. Our study demonstrates the potential of applying large language models to educational practice on STEM subjects. The results will shed light on the design of educational system in terms of harnessing AI's potential to empower educational stakeholders.