 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplying Large Language Models and Chain-of-Thought for Automatic Scoring
Paper and Code
Nov 30, 2023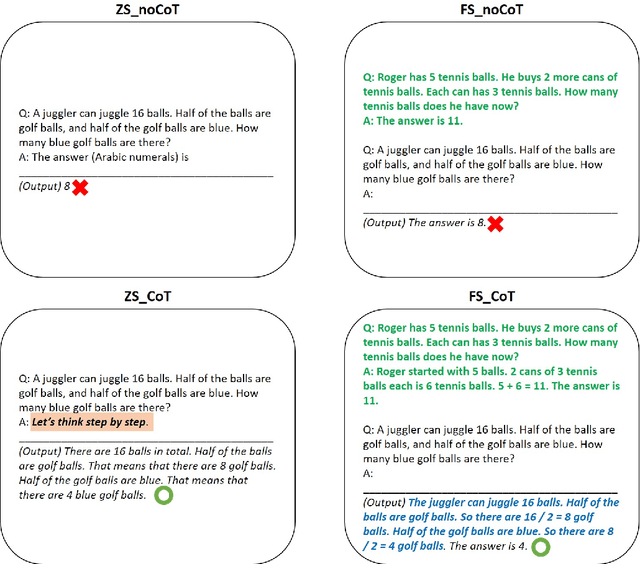
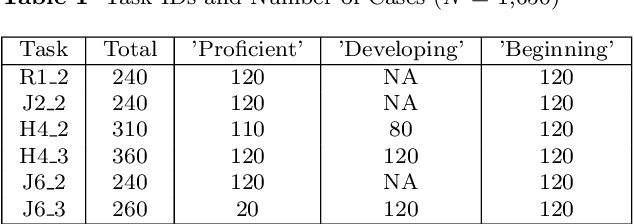
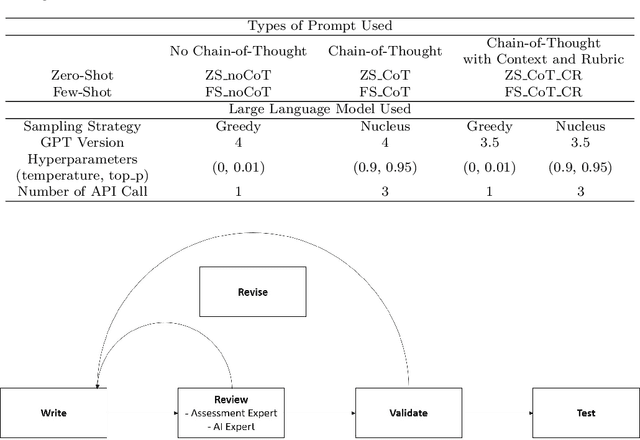

This study investigates the application of large language models (LLMs), specifically GPT-3.5 and GPT-4, with Chain-of-Though (CoT)in the automatic scoring of student-written responses to science assessments. We focused on overcoming the challenges of accessibility, technical complexity, and lack of explainability that have previously limited the use of automatic assessment tools among researchers and educators. We used a testing dataset comprising six assessment tasks (three binomial and three trinomial) with 1,650 student responses. We employed six prompt engineering strategies, combining zero-shot or few-shot learning with CoT, either alone or alongside item stem and scoring rubrics. Results indicated that few-shot (acc = .67) outperformed zero-shot learning (acc = .60), with 12.6\% increase. CoT, when used without item stem and scoring rubrics, did not significantly affect scoring accuracy (acc = .60). However, CoT prompting paired with contextual item stems and rubrics proved to be a significant contributor to scoring accuracy (13.44\% increase for zero-shot; 3.7\% increase for few-shot). Using a novel approach PPEAS, we found a more balanced accuracy across different proficiency categories, highlighting the importance of domain-specific reasoning in enhancing the effectiveness of LLMs in scoring tasks. Additionally, we also found that GPT-4 demonstrated superior performance over GPT-3.5 in various scoring tasks, showing 8.64\% difference. The study revealed that the single-call strategy with GPT-4, particularly using greedy sampling, outperformed other approaches, including ensemble voting strategies. This study demonstrates the potential of LLMs in facilitating automatic scoring, emphasizing that CoT enhances accuracy, particularly when used with item stem and scoring rubrics.