 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG-SciEdBERT: A Contextualized LLM for Science Assessment Tasks in German
Paper and Code
Feb 09, 2024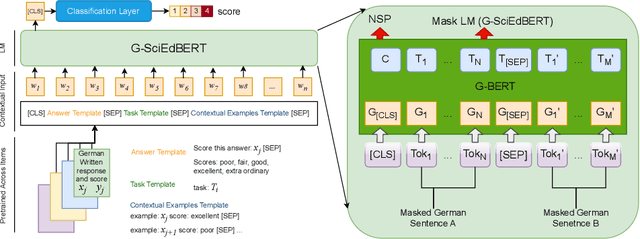
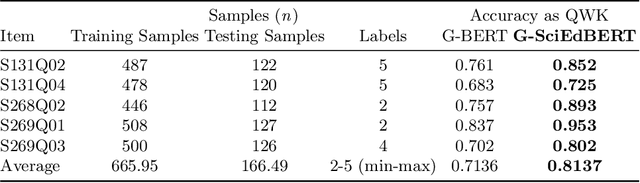
The advancement of natural language processing has paved the way for automated scoring systems in various languages, such as German (e.g., German BERT [G-BERT]). Automatically scoring written responses to science questions in German is a complex task and challenging for standard G-BERT as they lack contextual knowledge in the science domain and may be unaligned with student writing styles. This paper developed a contextualized German Science Education BERT (G-SciEdBERT), an innovative large language model tailored for scoring German-written responses to science tasks. Using G-BERT, we pre-trained G-SciEdBERT on a corpus of 50K German written science responses with 5M tokens to the Programme for International Student Assessment (PISA) 2015. We fine-tuned G-SciEdBERT on 59 assessment items and examined the scoring accuracy. We then compared its performance with G-BERT. Our findings reveal a substantial improvement in scoring accuracy with G-SciEdBERT, demonstrating a 10% increase of quadratic weighted kappa compared to G-BERT (mean accuracy difference = 0.096, SD = 0.024). These insights underline the significance of specialized language models like G-SciEdBERT, which is trained to enhance the accuracy of automated scoring, offering a substantial contribution to the field of AI in education.