 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom MAS to MARS: Coordination Failures and Reasoning Trade-offs in Hierarchical Multi-Agent Robotic Systems within a Healthcare Scenario
Aug 06, 2025Multi-agent robotic systems (MARS) build upon multi-agent systems by integrating physical and task-related constraints, increasing the complexity of action execution and agent coordination. However, despite the availability of advanced multi-agent frameworks, their real-world deployment on robots remains limited, hindering the advancement of MARS research in practice. To bridge this gap, we conducted two studies to investigate performance trade-offs of hierarchical multi-agent frameworks in a simulated real-world multi-robot healthcare scenario. In Study 1, using CrewAI, we iteratively refine the system's knowledge base, to systematically identify and categorize coordination failures (e.g., tool access violations, lack of timely handling of failure reports) not resolvable by providing contextual knowledge alone. In Study 2, using AutoGen, we evaluate a redesigned bidirectional communication structure and further measure the trade-offs between reasoning and non-reasoning models operating within the same robotic team setting. Drawing from our empirical findings, we emphasize the tension between autonomy and stability and the importance of edge-case testing to improve system reliability and safety for future real-world deployment. Supplementary materials, including codes, task agent setup, trace outputs, and annotated examples of coordination failures and reasoning behaviors, are available at: https://byc-sophie.github.io/mas-to-mars/.
LLM-DSE: Searching Accelerator Parameters with LLM Agents
May 18, 2025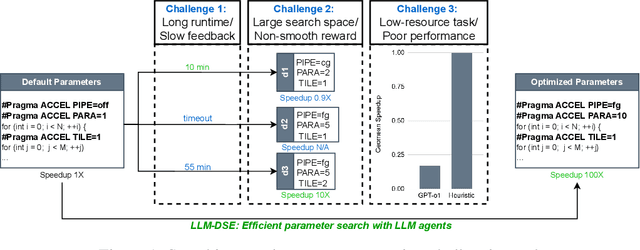
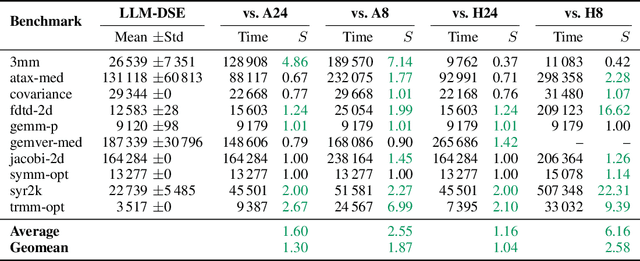
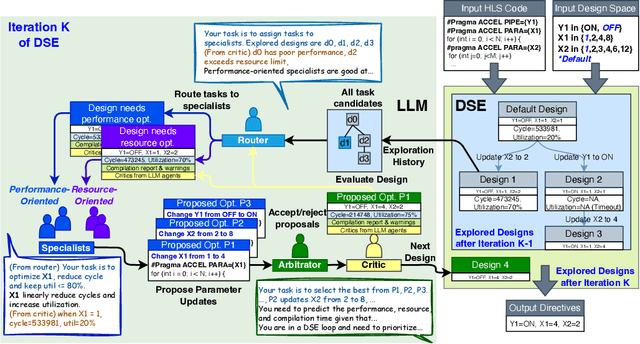

Even though high-level synthesis (HLS) tools mitigate the challenges of programming domain-specific accelerators (DSAs) by raising the abstraction level, optimizing hardware directive parameters remains a significant hurdle. Existing heuristic and learning-based methods struggle with adaptability and sample efficiency.We present LLM-DSE, a multi-agent framework designed specifically for optimizing HLS directives. Combining LLM with design space exploration (DSE), our explorer coordinates four agents: Router, Specialists, Arbitrator, and Critic. These multi-agent components interact with various tools to accelerate the optimization process. LLM-DSE leverages essential domain knowledge to identify efficient parameter combinations while maintaining adaptability through verbal learning from online interactions. Evaluations on the HLSyn dataset demonstrate that LLM-DSE achieves substantial $2.55\times$ performance gains over state-of-the-art methods, uncovering novel designs while reducing runtime. Ablation studies validate the effectiveness and necessity of the proposed agent interactions. Our code is open-sourced here: https://github.com/Nozidoali/LLM-DSE.
LIFT: LLM-Based Pragma Insertion for HLS via GNN Supervised Fine-Tuning
Apr 29, 2025
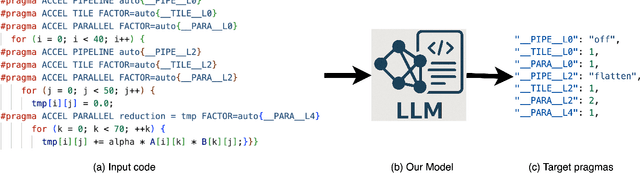
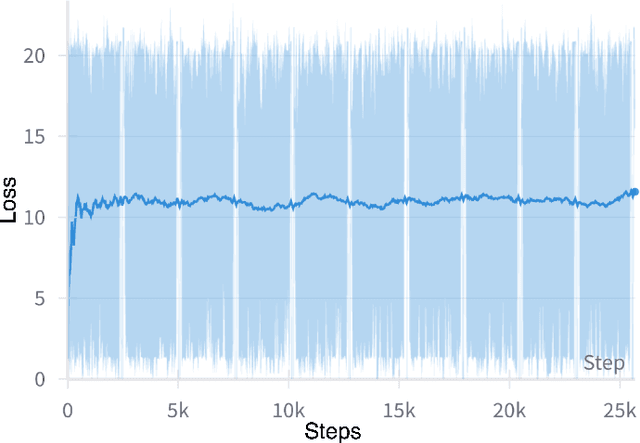
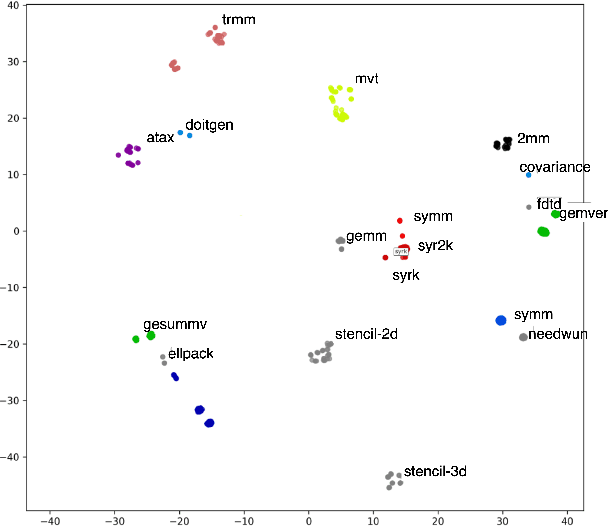
FPGAs are increasingly adopted in datacenter environments for their reconfigurability and energy efficiency. High-Level Synthesis (HLS) tools have eased FPGA programming by raising the abstraction level from RTL to untimed C/C++, yet attaining high performance still demands expert knowledge and iterative manual insertion of optimization pragmas to modify the microarchitecture. To address this challenge, we propose LIFT, a large language model (LLM)-based coding assistant for HLS that automatically generates performance-critical pragmas given a C/C++ design. We fine-tune the LLM by tightly integrating and supervising the training process with a graph neural network (GNN), combining the sequential modeling capabilities of LLMs with the structural and semantic understanding of GNNs necessary for reasoning over code and its control/data dependencies. On average, LIFT produces designs that improve performance by 3.52x and 2.16x than prior state-of the art AutoDSE and HARP respectively, and 66x than GPT-4o.
"The Diagram is like Guardrails": Structuring GenAI-assisted Hypotheses Exploration with an Interactive Shared Representation
Mar 21, 2025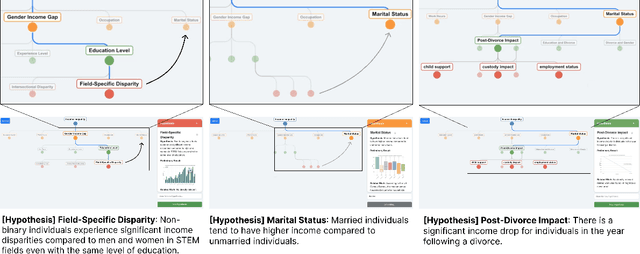
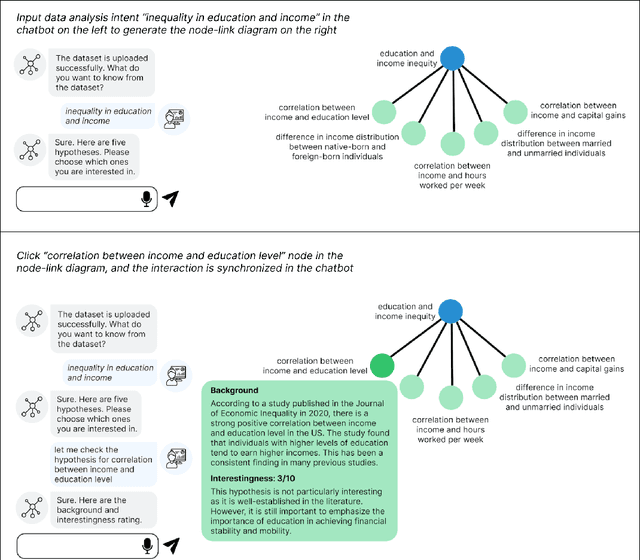
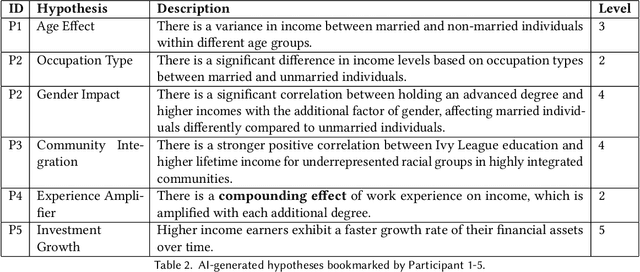
Data analysis encompasses a spectrum of tasks, from high-level conceptual reasoning to lower-level execution. While AI-powered tools increasingly support execution tasks, there remains a need for intelligent assistance in conceptual tasks. This paper investigates the design of an ordered node-link tree interface augmented with AI-generated information hints and visualizations, as a potential shared representation for hypothesis exploration. Through a design probe (n=22), participants generated diagrams averaging 21.82 hypotheses. Our findings showed that the node-link diagram acts as "guardrails" for hypothesis exploration, facilitating structured workflows, providing comprehensive overviews, and enabling efficient backtracking. The AI-generated information hints, particularly visualizations, aided users in transforming abstract ideas into data-backed concepts while reducing cognitive load. We further discuss how node-link diagrams can support both parallel exploration and iterative refinement in hypothesis formulation, potentially enhancing the breadth and depth of human-AI collaborative data analysis.
Hierarchical Mixture of Experts: Generalizable Learning for High-Level Synthesis
Oct 25, 2024



High-level synthesis (HLS) is a widely used tool in designing Field Programmable Gate Array (FPGA). HLS enables FPGA design with software programming languages by compiling the source code into an FPGA circuit. The source code includes a program (called ``kernel'') and several pragmas that instruct hardware synthesis, such as parallelization, pipeline, etc. While it is relatively easy for software developers to design the program, it heavily relies on hardware knowledge to design the pragmas, posing a big challenge for software developers. Recently, different machine learning algorithms, such as GNNs, have been proposed to automate the pragma design via performance prediction. However, when applying the trained model on new kernels, the significant domain shift often leads to unsatisfactory performance. We propose a more domain-generalizable model structure: a two-level hierarchical Mixture of Experts (MoE), that can be flexibly adapted to any GNN model. Different expert networks can learn to deal with different regions in the representation space, and they can utilize similar patterns between the old kernels and new kernels. In the low-level MoE, we apply MoE on three natural granularities of a program: node, basic block, and graph. The high-level MoE learns to aggregate the three granularities for the final decision. To stably train the hierarchical MoE, we further propose a two-stage training method. Extensive experiments verify the effectiveness of the hierarchical MoE.
Cross-Modality Program Representation Learning for Electronic Design Automation with High-Level Synthesis
Jun 13, 2024In recent years, domain-specific accelerators (DSAs) have gained popularity for applications such as deep learning and autonomous driving. To facilitate DSA designs, programmers use high-level synthesis (HLS) to compile a high-level description written in C/C++ into a design with low-level hardware description languages that eventually synthesize DSAs on circuits. However, creating a high-quality HLS design still demands significant domain knowledge, particularly in microarchitecture decisions expressed as \textit{pragmas}. Thus, it is desirable to automate such decisions with the help of machine learning for predicting the quality of HLS designs, requiring a deeper understanding of the program that consists of original code and pragmas. Naturally, these programs can be considered as sequence data. In addition, these programs can be compiled and converted into a control data flow graph (CDFG). But existing works either fail to leverage both modalities or combine the two in shallow or coarse ways. We propose ProgSG, a model that allows interaction between the source code sequence modality and the graph modality in a deep and fine-grained way. To alleviate the scarcity of labeled designs, a pre-training method is proposed based on a suite of compiler's data flow analysis tasks. Experimental results show that ProgSG reduces the RMSE of design performance predictions by up to $22\%$, and identifies designs with an average of $1.10\times$ and $1.26\times$ (up to $8.17\times$ and $13.31\times$) performance improvement in design space exploration (DSE) task compared to HARP and AutoDSE, respectively.
UniSparse: An Intermediate Language for General Sparse Format Customization
Mar 09, 2024



The ongoing trend of hardware specialization has led to a growing use of custom data formats when processing sparse workloads, which are typically memory-bound. These formats facilitate optimized software/hardware implementations by utilizing sparsity pattern- or target-aware data structures and layouts to enhance memory access latency and bandwidth utilization. However, existing sparse tensor programming models and compilers offer little or no support for productively customizing the sparse formats. Additionally, because these frameworks represent formats using a limited set of per-dimension attributes, they lack the flexibility to accommodate numerous new variations of custom sparse data structures and layouts. To overcome this deficiency, we propose UniSparse, an intermediate language that provides a unified abstraction for representing and customizing sparse formats. Unlike the existing attribute-based frameworks, UniSparse decouples the logical representation of the sparse tensor (i.e., the data structure) from its low-level memory layout, enabling the customization of both. As a result, a rich set of format customizations can be succinctly expressed in a small set of well-defined query, mutation, and layout primitives. We also develop a compiler leveraging the MLIR infrastructure, which supports adaptive customization of formats, and automatic code generation of format conversion and compute operations for heterogeneous architectures. We demonstrate the efficacy of our approach through experiments running commonly-used sparse linear algebra operations with specialized formats on multiple different hardware targets, including an Intel CPU, an NVIDIA GPU, an AMD Xilinx FPGA, and a simulated processing-in-memory (PIM) device.
* to be published in OOPSLA'24
Intelligent Canvas: Enabling Design-Like Exploratory Visual Data Analysis with Generative AI through Rapid Prototyping, Iteration and Curation
Feb 16, 2024



Complex data analysis inherently seeks unexpected insights through exploratory \re{visual analysis} methods, transcending logical, step-by-step processing. However, \re{existing interfaces such as notebooks and dashboards have limitations in exploration and comparison for visual data analysis}. Addressing these limitations, we introduce a "design-like" intelligent canvas environment integrating generative AI into data analysis, offering rapid prototyping, iteration, and comparative visualization management. Our dual contributions include the integration of generative AI components into a canvas interface, and empirical findings from a user study (N=10) evaluating the effectiveness of the canvas interface.
Harnessing the Power of LLMs: Evaluating Human-AI Text Co-Creation through the Lens of News Headline Generation
Oct 18, 2023



To explore how humans can best leverage LLMs for writing and how interacting with these models affects feelings of ownership and trust in the writing process, we compared common human-AI interaction types (e.g., guiding system, selecting from system outputs, post-editing outputs) in the context of LLM-assisted news headline generation. While LLMs alone can generate satisfactory news headlines, on average, human control is needed to fix undesirable model outputs. Of the interaction methods, guiding and selecting model output added the most benefit with the lowest cost (in time and effort). Further, AI assistance did not harm participants' perception of control compared to freeform editing.
Elucidating STEM Concepts through Generative AI: A Multi-modal Exploration of Analogical Reasoning
Aug 21, 2023

This study explores the integration of generative artificial intelligence (AI), specifically large language models, with multi-modal analogical reasoning as an innovative approach to enhance science, technology, engineering, and mathematics (STEM) education. We have developed a novel system that utilizes the capacities of generative AI to transform intricate principles in mathematics, physics, and programming into comprehensible metaphors. To further augment the educational experience, these metaphors are subsequently converted into visual form. Our study aims to enhance the learners' understanding of STEM concepts and their learning engagement by using the visual metaphors. We examine the efficacy of our system via a randomized A/B/C test, assessing learning gains and motivation shifts among the learners. Our study demonstrates the potential of applying large language models to educational practice on STEM subjects. The results will shed light on the design of educational system in terms of harnessing AI's potential to empower educational stakeholders.