 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReport for NSF Workshop on AI for Electronic Design Automation
Jan 20, 2026This report distills the discussions and recommendations from the NSF Workshop on AI for Electronic Design Automation (EDA), held on December 10, 2024 in Vancouver alongside NeurIPS 2024. Bringing together experts across machine learning and EDA, the workshop examined how AI-spanning large language models (LLMs), graph neural networks (GNNs), reinforcement learning (RL), neurosymbolic methods, etc.-can facilitate EDA and shorten design turnaround. The workshop includes four themes: (1) AI for physical synthesis and design for manufacturing (DFM), discussing challenges in physical manufacturing process and potential AI applications; (2) AI for high-level and logic-level synthesis (HLS/LLS), covering pragma insertion, program transformation, RTL code generation, etc.; (3) AI toolbox for optimization and design, discussing frontier AI developments that could potentially be applied to EDA tasks; and (4) AI for test and verification, including LLM-assisted verification tools, ML-augmented SAT solving, security/reliability challenges, etc. The report recommends NSF to foster AI/EDA collaboration, invest in foundational AI for EDA, develop robust data infrastructures, promote scalable compute infrastructure, and invest in workforce development to democratize hardware design and enable next-generation hardware systems. The workshop information can be found on the website https://ai4eda-workshop.github.io/.
Hierarchical Mixture of Experts: Generalizable Learning for High-Level Synthesis
Oct 25, 2024



High-level synthesis (HLS) is a widely used tool in designing Field Programmable Gate Array (FPGA). HLS enables FPGA design with software programming languages by compiling the source code into an FPGA circuit. The source code includes a program (called ``kernel'') and several pragmas that instruct hardware synthesis, such as parallelization, pipeline, etc. While it is relatively easy for software developers to design the program, it heavily relies on hardware knowledge to design the pragmas, posing a big challenge for software developers. Recently, different machine learning algorithms, such as GNNs, have been proposed to automate the pragma design via performance prediction. However, when applying the trained model on new kernels, the significant domain shift often leads to unsatisfactory performance. We propose a more domain-generalizable model structure: a two-level hierarchical Mixture of Experts (MoE), that can be flexibly adapted to any GNN model. Different expert networks can learn to deal with different regions in the representation space, and they can utilize similar patterns between the old kernels and new kernels. In the low-level MoE, we apply MoE on three natural granularities of a program: node, basic block, and graph. The high-level MoE learns to aggregate the three granularities for the final decision. To stably train the hierarchical MoE, we further propose a two-stage training method. Extensive experiments verify the effectiveness of the hierarchical MoE.
ECAFormer: Low-light Image Enhancement using Cross Attention
Jun 19, 2024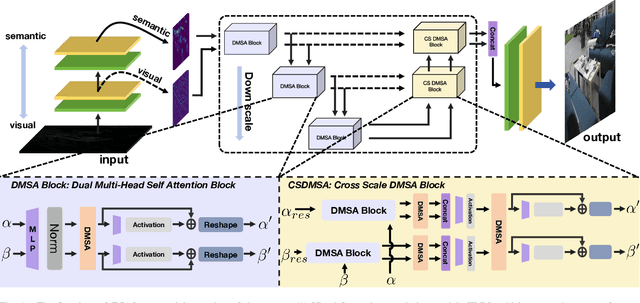

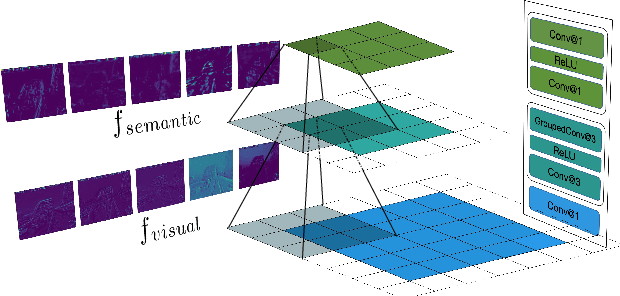

Low-light image enhancement (LLIE) is vital for autonomous driving. Despite the importance, existing LLIE methods often prioritize robustness in overall brightness adjustment, which can come at the expense of detail preservation. To overcome this limitation,we propose the Hierarchical Mutual Enhancement via Cross-Attention transformer (ECAFormer), a novel network that utilizes Dual Multi-head Self Attention (DMSA) to enhance both visual and semantic features across scales, significantly preserving details during the process. The cross-attention mechanism in ECAFormer not only improves upon traditional enhancement techniques but also excels in maintaining a balance between global brightness adjustment and local detail retention. Our extensive experimental validation on renowned low-illumination datasets, including SID and LOL, and additional tests on dark road scenarios. or performance over existing methods in terms of illumination enhancement and noise reduction, while also optimizing computational complexity and parameter count, further boosting SSIM and PSNR metrics. Our project is available at https://github.com/ruanyudi/ECAFormer.
Fast Inference of Removal-Based Node Influence
Mar 16, 2024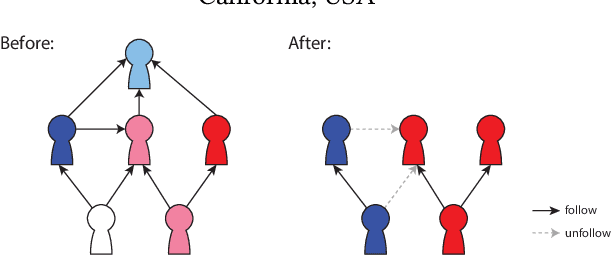



Graph neural networks (GNNs) are widely utilized to capture the information spreading patterns in graphs. While remarkable performance has been achieved, there is a new trending topic of evaluating node influence. We propose a new method of evaluating node influence, which measures the prediction change of a trained GNN model caused by removing a node. A real-world application is, "In the task of predicting Twitter accounts' polarity, had a particular account been removed, how would others' polarity change?". We use the GNN as a surrogate model whose prediction could simulate the change of nodes or edges caused by node removal. Our target is to obtain the influence score for every node, and a straightforward way is to alternately remove every node and apply the trained GNN on the modified graph to generate new predictions. It is reliable but time-consuming, so we need an efficient method. The related lines of work, such as graph adversarial attack and counterfactual explanation, cannot directly satisfy our needs, since their problem settings are different. We propose an efficient, intuitive, and effective method, NOde-Removal-based fAst GNN inference (NORA), which uses the gradient information to approximate the node-removal influence. It only costs one forward propagation and one backpropagation to approximate the influence score for all nodes. Extensive experiments on six datasets and six GNN models verify the effectiveness of NORA. Our code is available at https://github.com/weikai-li/NORA.git.
Are All Unseen Data Out-of-Distribution?
Jan 02, 2024



Distributions of unseen data have been all treated as out-of-distribution (OOD), making their generalization a significant challenge. Much evidence suggests that the size increase of training data can monotonically decrease generalization errors in test data. However, this is not true from other observations and analysis. In particular, when the training data have multiple source domains and the test data contain distribution drifts, then not all generalization errors on the test data decrease monotonically with the increasing size of training data. Such a non-decreasing phenomenon is formally investigated under a linear setting with empirical verification across varying visual benchmarks. Motivated by these results, we redefine the OOD data as a type of data outside the convex hull of the training domains and prove a new generalization bound based on this new definition. It implies that the effectiveness of a well-trained model can be guaranteed for the unseen data that is within the convex hull of the training domains. But, for some data beyond the convex hull, a non-decreasing error trend can happen. Therefore, we investigate the performance of popular strategies such as data augmentation and pre-training to overcome this issue. Moreover, we propose a novel reinforcement learning selection algorithm in the source domains only that can deliver superior performance over the baseline methods.
TIDE: Test Time Few Shot Object Detection
Nov 30, 2023Few-shot object detection (FSOD) aims to extract semantic knowledge from limited object instances of novel categories within a target domain. Recent advances in FSOD focus on fine-tuning the base model based on a few objects via meta-learning or data augmentation. Despite their success, the majority of them are grounded with parametric readjustment to generalize on novel objects, which face considerable challenges in Industry 5.0, such as (i) a certain amount of fine-tuning time is required, and (ii) the parameters of the constructed model being unavailable due to the privilege protection, making the fine-tuning fail. Such constraints naturally limit its application in scenarios with real-time configuration requirements or within black-box settings. To tackle the challenges mentioned above, we formalize a novel FSOD task, referred to as Test TIme Few Shot DEtection (TIDE), where the model is un-tuned in the configuration procedure. To that end, we introduce an asymmetric architecture for learning a support-instance-guided dynamic category classifier. Further, a cross-attention module and a multi-scale resizer are provided to enhance the model performance. Experimental results on multiple few-shot object detection platforms reveal that the proposed TIDE significantly outperforms existing contemporary methods. The implementation codes are available at https://github.com/deku-0621/TIDE
When does In-context Learning Fall Short and Why? A Study on Specification-Heavy Tasks
Nov 15, 2023In-context learning (ICL) has become the default method for using large language models (LLMs), making the exploration of its limitations and understanding the underlying causes crucial. In this paper, we find that ICL falls short of handling specification-heavy tasks, which are tasks with complicated and extensive task specifications, requiring several hours for ordinary humans to master, such as traditional information extraction tasks. The performance of ICL on these tasks mostly cannot reach half of the state-of-the-art results. To explore the reasons behind this failure, we conduct comprehensive experiments on 18 specification-heavy tasks with various LLMs and identify three primary reasons: inability to specifically understand context, misalignment in task schema comprehension with humans, and inadequate long-text understanding ability. Furthermore, we demonstrate that through fine-tuning, LLMs can achieve decent performance on these tasks, indicating that the failure of ICL is not an inherent flaw of LLMs, but rather a drawback of existing alignment methods that renders LLMs incapable of handling complicated specification-heavy tasks via ICL. To substantiate this, we perform dedicated instruction tuning on LLMs for these tasks and observe a notable improvement. We hope the analyses in this paper could facilitate advancements in alignment methods enabling LLMs to meet more sophisticated human demands.
KoLA: Carefully Benchmarking World Knowledge of Large Language Models
Jun 15, 2023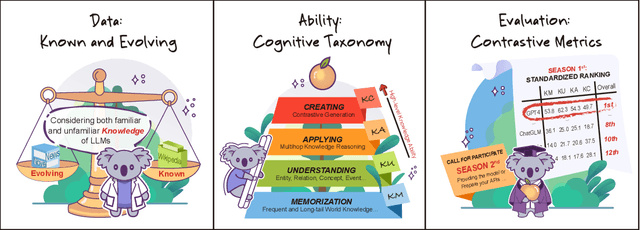
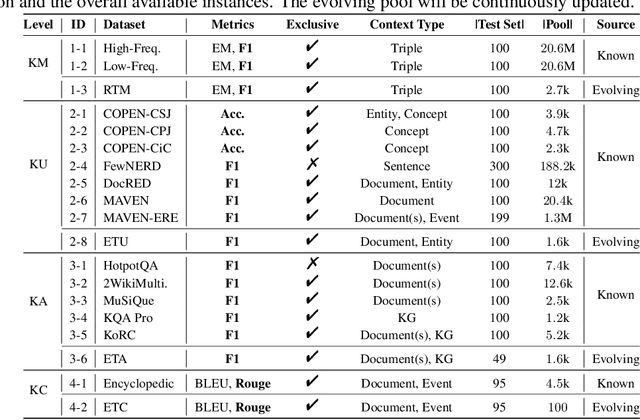
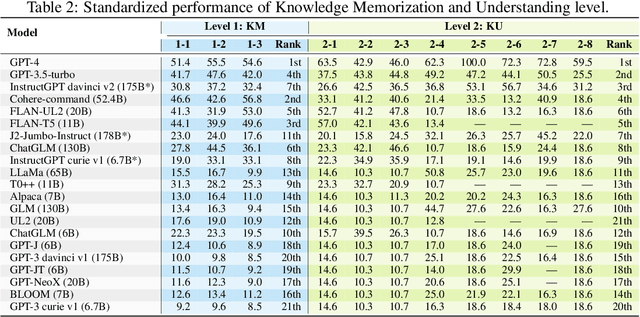

The unprecedented performance of large language models (LLMs) necessitates improvements in evaluations. Rather than merely exploring the breadth of LLM abilities, we believe meticulous and thoughtful designs are essential to thorough, unbiased, and applicable evaluations. Given the importance of world knowledge to LLMs, we construct a Knowledge-oriented LLM Assessment benchmark (KoLA), in which we carefully design three crucial factors: (1) For ability modeling, we mimic human cognition to form a four-level taxonomy of knowledge-related abilities, covering $19$ tasks. (2) For data, to ensure fair comparisons, we use both Wikipedia, a corpus prevalently pre-trained by LLMs, along with continuously collected emerging corpora, aiming to evaluate the capacity to handle unseen data and evolving knowledge. (3) For evaluation criteria, we adopt a contrastive system, including overall standard scores for better numerical comparability across tasks and models and a unique self-contrast metric for automatically evaluating knowledge hallucination. We evaluate $21$ open-source and commercial LLMs and obtain some intriguing findings. The KoLA dataset and open-participation leaderboard are publicly released at https://kola.xlore.cn and will be continuously updated to provide references for developing LLMs and knowledge-related systems.
Rethinking the Setting of Semi-supervised Learning on Graphs
May 28, 2022
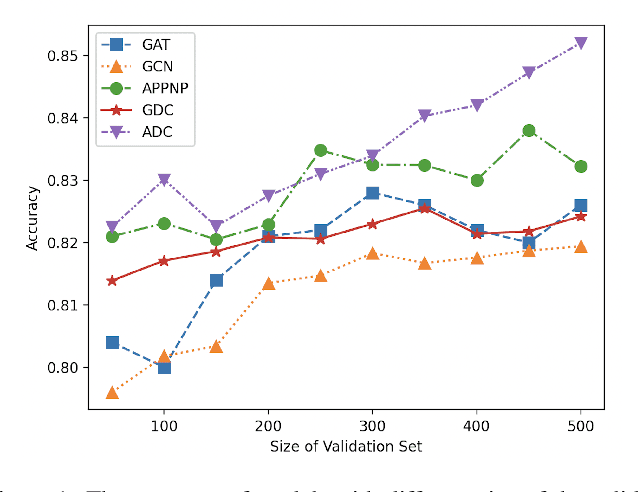
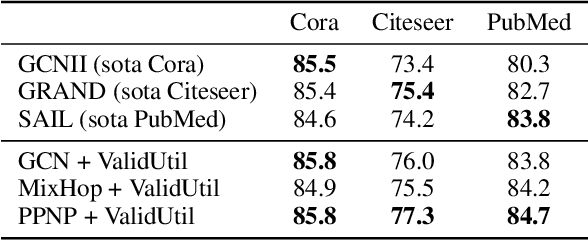
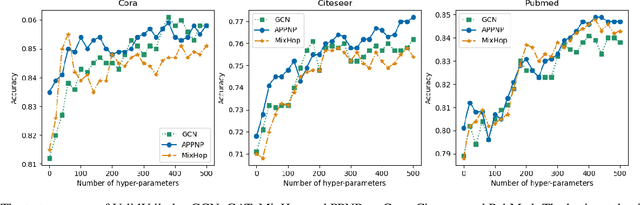
We argue that the present setting of semisupervised learning on graphs may result in unfair comparisons, due to its potential risk of over-tuning hyper-parameters for models. In this paper, we highlight the significant influence of tuning hyper-parameters, which leverages the label information in the validation set to improve the performance. To explore the limit of over-tuning hyperparameters, we propose ValidUtil, an approach to fully utilize the label information in the validation set through an extra group of hyper-parameters. With ValidUtil, even GCN can easily get high accuracy of 85.8% on Cora. To avoid over-tuning, we merge the training set and the validation set and construct an i.i.d. graph benchmark (IGB) consisting of 4 datasets. Each dataset contains 100 i.i.d. graphs sampled from a large graph to reduce the evaluation variance. Our experiments suggest that IGB is a more stable benchmark than previous datasets for semisupervised learning on graphs.
Jacobian Norm for Unsupervised Source-Free Domain Adaptation
Apr 07, 2022
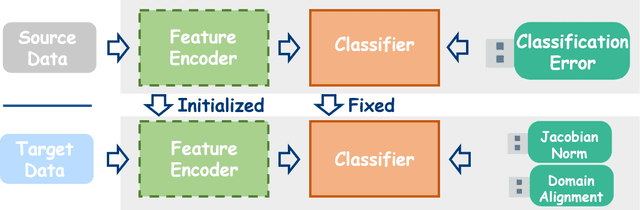
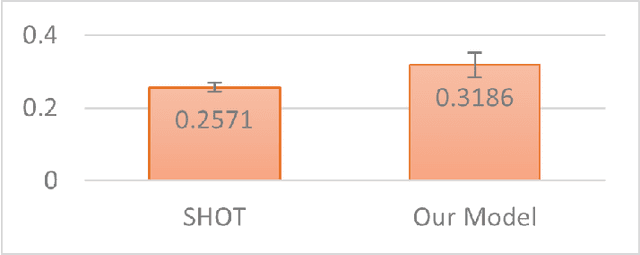

Unsupervised Source (data) Free domain adaptation (USFDA) aims to transfer knowledge from a well-trained source model to a related but unlabeled target domain. In such a scenario, all conventional adaptation methods that require source data fail. To combat this challenge, existing USFDAs turn to transfer knowledge by aligning the target feature to the latent distribution hidden in the source model. However, such information is naturally limited. Thus, the alignment in such a scenario is not only difficult but also insufficient, which degrades the target generalization performance. To relieve this dilemma in current USFDAs, we are motivated to explore a new perspective to boost their performance. For this purpose and gaining necessary insight, we look back upon the origin of the domain adaptation and first theoretically derive a new-brand target generalization error bound based on the model smoothness. Then, following the theoretical insight, a general and model-smoothness-guided Jacobian norm (JN) regularizer is designed and imposed on the target domain to mitigate this dilemma. Extensive experiments are conducted to validate its effectiveness. In its implementation, just with a few lines of codes added to the existing USFDAs, we achieve superior results on various benchmark datasets.