 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Paradoxical Interference between Instruction-Following and Task Solving
Jan 29, 2026Instruction following aims to align Large Language Models (LLMs) with human intent by specifying explicit constraints on how tasks should be performed. However, we reveal a counterintuitive phenomenon: instruction following can paradoxically interfere with LLMs' task-solving capability. We propose a metric, SUSTAINSCORE, to quantify the interference of instruction following with task solving. It measures task performance drop after inserting into the instruction a self-evident constraint, which is naturally met by the original successful model output and extracted from it. Experiments on current LLMs in mathematics, multi-hop QA, and code generation show that adding the self-evident constraints leads to substantial performance drops, even for advanced models such as Claude-Sonnet-4.5. We validate the generality of the interference across constraint types and scales. Furthermore, we identify common failure patterns, and by investigating the mechanisms of interference, we observe that failed cases allocate significantly more attention to constraints compared to successful ones. Finally, we use SUSTAINSCORE to conduct an initial investigation into how distinct post-training paradigms affect the interference, presenting empirical observations on current alignment strategies. We will release our code and data to facilitate further research
VerIF: Verification Engineering for Reinforcement Learning in Instruction Following
Jun 11, 2025Reinforcement learning with verifiable rewards (RLVR) has become a key technique for enhancing large language models (LLMs), with verification engineering playing a central role. However, best practices for RL in instruction following remain underexplored. In this work, we explore the verification challenge in RL for instruction following and propose VerIF, a verification method that combines rule-based code verification with LLM-based verification from a large reasoning model (e.g., QwQ-32B). To support this approach, we construct a high-quality instruction-following dataset, VerInstruct, containing approximately 22,000 instances with associated verification signals. We apply RL training with VerIF to two models, achieving significant improvements across several representative instruction-following benchmarks. The trained models reach state-of-the-art performance among models of comparable size and generalize well to unseen constraints. We further observe that their general capabilities remain unaffected, suggesting that RL with VerIF can be integrated into existing RL recipes to enhance overall model performance. We have released our datasets, codes, and models to facilitate future research at https://github.com/THU-KEG/VerIF.
AGENTIF: Benchmarking Instruction Following of Large Language Models in Agentic Scenarios
May 22, 2025Large Language Models (LLMs) have demonstrated advanced capabilities in real-world agentic applications. Growing research efforts aim to develop LLM-based agents to address practical demands, introducing a new challenge: agentic scenarios often involve lengthy instructions with complex constraints, such as extended system prompts and detailed tool specifications. While adherence to such instructions is crucial for agentic applications, whether LLMs can reliably follow them remains underexplored. In this paper, we introduce AgentIF, the first benchmark for systematically evaluating LLM instruction following ability in agentic scenarios. AgentIF features three key characteristics: (1) Realistic, constructed from 50 real-world agentic applications. (2) Long, averaging 1,723 words with a maximum of 15,630 words. (3) Complex, averaging 11.9 constraints per instruction, covering diverse constraint types, such as tool specifications and condition constraints. To construct AgentIF, we collect 707 human-annotated instructions across 50 agentic tasks from industrial application agents and open-source agentic systems. For each instruction, we annotate the associated constraints and corresponding evaluation metrics, including code-based evaluation, LLM-based evaluation, and hybrid code-LLM evaluation. We use AgentIF to systematically evaluate existing advanced LLMs. We observe that current models generally perform poorly, especially in handling complex constraint structures and tool specifications. We further conduct error analysis and analytical experiments on instruction length and meta constraints, providing some findings about the failure modes of existing LLMs. We have released the code and data to facilitate future research.
Agentic Reward Modeling: Integrating Human Preferences with Verifiable Correctness Signals for Reliable Reward Systems
Feb 26, 2025Reward models (RMs) are crucial for the training and inference-time scaling up of large language models (LLMs). However, existing reward models primarily focus on human preferences, neglecting verifiable correctness signals which have shown strong potential in training LLMs. In this paper, we propose agentic reward modeling, a reward system that combines reward models with verifiable correctness signals from different aspects to provide reliable rewards. We empirically implement a reward agent, named RewardAgent, that combines human preference rewards with two verifiable signals: factuality and instruction following, to provide more reliable rewards. We conduct comprehensive experiments on existing reward model benchmarks and inference time best-of-n searches on real-world downstream tasks. RewardAgent significantly outperforms vanilla reward models, demonstrating its effectiveness. We further construct training preference pairs using RewardAgent and train an LLM with the DPO objective, achieving superior performance on various NLP benchmarks compared to conventional reward models. Our codes are publicly released to facilitate further research (https://github.com/THU-KEG/Agentic-Reward-Modeling).
Constraint Back-translation Improves Complex Instruction Following of Large Language Models
Oct 31, 2024



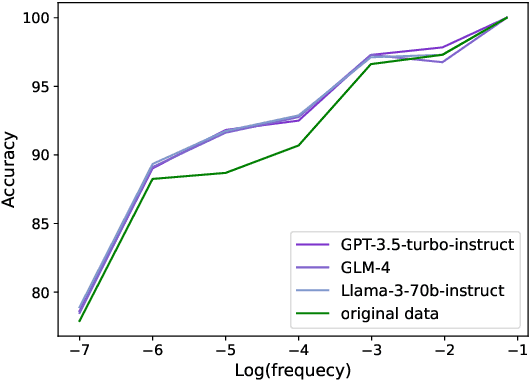
Large language models (LLMs) struggle to follow instructions with complex constraints in format, length, etc. Following the conventional instruction-tuning practice, previous works conduct post-training on complex instruction-response pairs generated by feeding complex instructions to advanced LLMs. However, even advanced LLMs cannot follow complex instructions well, thus limiting the quality of generated data. In this work, we find that existing datasets inherently contain implicit complex constraints and propose a novel data generation technique, constraint back-translation. Specifically, we take the high-quality instruction-response pairs in existing datasets and only adopt advanced LLMs to add complex constraints already met by the responses to the instructions, which naturally reduces costs and data noise. In the experiments, we adopt Llama3-70B-Instruct to back-translate constraints and create a high-quality complex instruction-response dataset, named CRAB. We present that post-training on CRAB improves multiple backbone LLMs' complex instruction-following ability, evaluated on extensive instruction-following benchmarks. We further find that constraint back-translation also serves as a useful auxiliary training objective in post-training. Our code, data, and models will be released to facilitate future research.
MAVEN-Fact: A Large-scale Event Factuality Detection Dataset
Jul 22, 2024Event Factuality Detection (EFD) task determines the factuality of textual events, i.e., classifying whether an event is a fact, possibility, or impossibility, which is essential for faithfully understanding and utilizing event knowledge. However, due to the lack of high-quality large-scale data, event factuality detection is under-explored in event understanding research, which limits the development of EFD community. To address these issues and provide faithful event understanding, we introduce MAVEN-Fact, a large-scale and high-quality EFD dataset based on the MAVEN dataset. MAVEN-Fact includes factuality annotations of 112,276 events, making it the largest EFD dataset. Extensive experiments demonstrate that MAVEN-Fact is challenging for both conventional fine-tuned models and large language models (LLMs). Thanks to the comprehensive annotations of event arguments and relations in MAVEN, MAVEN-Fact also supports some further analyses and we find that adopting event arguments and relations helps in event factuality detection for fine-tuned models but does not benefit LLMs. Furthermore, we preliminarily study an application case of event factuality detection and find it helps in mitigating event-related hallucination in LLMs. Our dataset and codes can be obtained from \url{https://github.com/lcy2723/MAVEN-FACT}
LLMAEL: Large Language Models are Good Context Augmenters for Entity Linking
Jul 04, 2024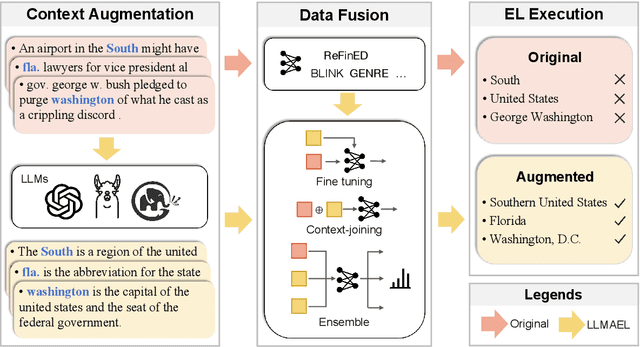

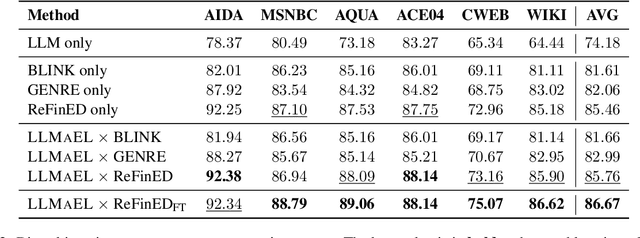
Entity Linking (EL) models are well-trained at mapping mentions to their corresponding entities according to a given context. However, EL models struggle to disambiguate long-tail entities due to their limited training data. Meanwhile, large language models (LLMs) are more robust at interpreting uncommon mentions. Yet, due to a lack of specialized training, LLMs suffer at generating correct entity IDs. Furthermore, training an LLM to perform EL is cost-intensive. Building upon these insights, we introduce LLM-Augmented Entity Linking LLMAEL, a plug-and-play approach to enhance entity linking through LLM data augmentation. We leverage LLMs as knowledgeable context augmenters, generating mention-centered descriptions as additional input, while preserving traditional EL models for task specific processing. Experiments on 6 standard datasets show that the vanilla LLMAEL outperforms baseline EL models in most cases, while the fine-tuned LLMAEL set the new state-of-the-art results across all 6 benchmarks.
ADELIE: Aligning Large Language Models on Information Extraction
May 08, 2024Large language models (LLMs) usually fall short on information extraction (IE) tasks and struggle to follow the complex instructions of IE tasks. This primarily arises from LLMs not being aligned with humans, as mainstream alignment datasets typically do not include IE data. In this paper, we introduce ADELIE (Aligning large language moDELs on Information Extraction), an aligned LLM that effectively solves various IE tasks, including closed IE, open IE, and on-demand IE. We first collect and construct a high-quality alignment corpus IEInstruct for IE. Then we train ADELIE_SFT using instruction tuning on IEInstruct. We further train ADELIE_SFT with direct preference optimization (DPO) objective, resulting in ADELIE_DPO. Extensive experiments on various held-out IE datasets demonstrate that our models (ADELIE_SFT and ADELIE_DPO) achieve state-of-the-art (SoTA) performance among open-source models. We further explore the general capabilities of ADELIE, and experimental results reveal that their general capabilities do not exhibit a noticeable decline. We will release the code, data, and models to facilitate further research.
When does In-context Learning Fall Short and Why? A Study on Specification-Heavy Tasks
Nov 15, 2023In-context learning (ICL) has become the default method for using large language models (LLMs), making the exploration of its limitations and understanding the underlying causes crucial. In this paper, we find that ICL falls short of handling specification-heavy tasks, which are tasks with complicated and extensive task specifications, requiring several hours for ordinary humans to master, such as traditional information extraction tasks. The performance of ICL on these tasks mostly cannot reach half of the state-of-the-art results. To explore the reasons behind this failure, we conduct comprehensive experiments on 18 specification-heavy tasks with various LLMs and identify three primary reasons: inability to specifically understand context, misalignment in task schema comprehension with humans, and inadequate long-text understanding ability. Furthermore, we demonstrate that through fine-tuning, LLMs can achieve decent performance on these tasks, indicating that the failure of ICL is not an inherent flaw of LLMs, but rather a drawback of existing alignment methods that renders LLMs incapable of handling complicated specification-heavy tasks via ICL. To substantiate this, we perform dedicated instruction tuning on LLMs for these tasks and observe a notable improvement. We hope the analyses in this paper could facilitate advancements in alignment methods enabling LLMs to meet more sophisticated human demands.
KoLA: Carefully Benchmarking World Knowledge of Large Language Models
Jun 15, 2023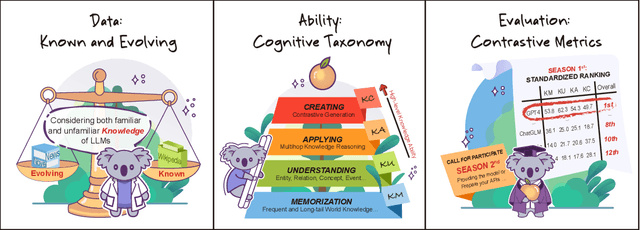
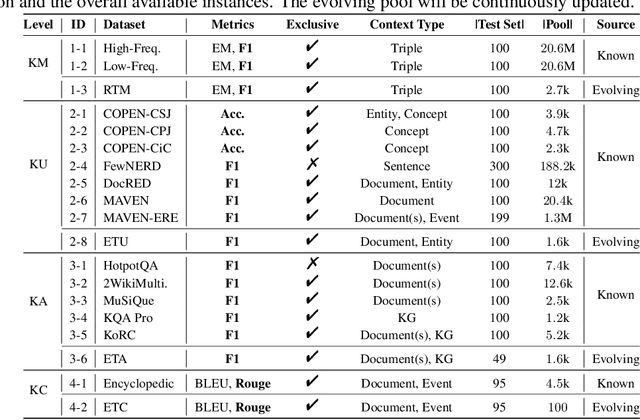
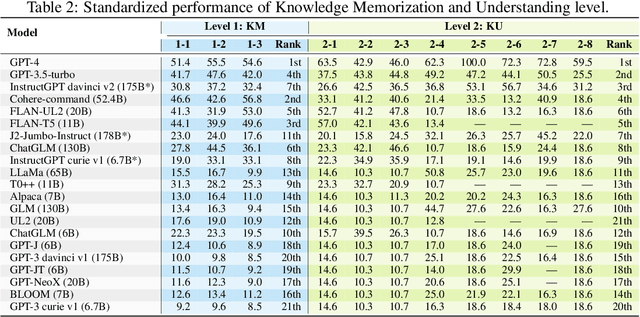

The unprecedented performance of large language models (LLMs) necessitates improvements in evaluations. Rather than merely exploring the breadth of LLM abilities, we believe meticulous and thoughtful designs are essential to thorough, unbiased, and applicable evaluations. Given the importance of world knowledge to LLMs, we construct a Knowledge-oriented LLM Assessment benchmark (KoLA), in which we carefully design three crucial factors: (1) For ability modeling, we mimic human cognition to form a four-level taxonomy of knowledge-related abilities, covering $19$ tasks. (2) For data, to ensure fair comparisons, we use both Wikipedia, a corpus prevalently pre-trained by LLMs, along with continuously collected emerging corpora, aiming to evaluate the capacity to handle unseen data and evolving knowledge. (3) For evaluation criteria, we adopt a contrastive system, including overall standard scores for better numerical comparability across tasks and models and a unique self-contrast metric for automatically evaluating knowledge hallucination. We evaluate $21$ open-source and commercial LLMs and obtain some intriguing findings. The KoLA dataset and open-participation leaderboard are publicly released at https://kola.xlore.cn and will be continuously updated to provide references for developing LLMs and knowledge-related systems.