 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAEGIS: Adversarial Target-Guided Retention-Data-Free Robust Concept Erasure from Diffusion Models
Feb 06, 2026Concept erasure helps stop diffusion models (DMs) from generating harmful content; but current methods face robustness retention trade off. Robustness means the model fine-tuned by concept erasure methods resists reactivation of erased concepts, even under semantically related prompts. Retention means unrelated concepts are preserved so the model's overall utility stays intact. Both are critical for concept erasure in practice, yet addressing them simultaneously is challenging, as existing works typically improve one factor while sacrificing the other. Prior work typically strengthens one while degrading the other, e.g., mapping a single erased prompt to a fixed safe target leaves class level remnants exploitable by prompt attacks, whereas retention-oriented schemes underperform against adaptive adversaries. This paper introduces Adversarial Erasure with Gradient Informed Synergy (AEGIS), a retention-data-free framework that advances both robustness and retention.
* 30 pages,12 figures
Is Gradient Ascent Really Necessary? Memorize to Forget for Machine Unlearning
Feb 06, 2026For ethical and safe AI, machine unlearning rises as a critical topic aiming to protect sensitive, private, and copyrighted knowledge from misuse. To achieve this goal, it is common to conduct gradient ascent (GA) to reverse the training on undesired data. However, such a reversal is prone to catastrophic collapse, which leads to serious performance degradation in general tasks. As a solution, we propose model extrapolation as an alternative to GA, which reaches the counterpart direction in the hypothesis space from one model given another reference model. Therefore, we leverage the original model as the reference, further train it to memorize undesired data while keeping prediction consistency on the rest retained data, to obtain a memorization model. Counterfactual as it might sound, a forget model can be obtained via extrapolation from the memorization model to the reference model. Hence, we avoid directly acquiring the forget model using GA, but proceed with gradient descent for the memorization model, which successfully stabilizes the machine unlearning process. Our model extrapolation is simple and efficient to implement, and it can also effectively converge throughout training to achieve improved unlearning performance.
HierCon: Hierarchical Contrastive Attention for Audio Deepfake Detection
Feb 01, 2026Audio deepfakes generated by modern TTS and voice conversion systems are increasingly difficult to distinguish from real speech, raising serious risks for security and online trust. While state-of-the-art self-supervised models provide rich multi-layer representations, existing detectors treat layers independently and overlook temporal and hierarchical dependencies critical for identifying synthetic artefacts. We propose HierCon, a hierarchical layer attention framework combined with margin-based contrastive learning that models dependencies across temporal frames, neighbouring layers, and layer groups, while encouraging domain-invariant embeddings. Evaluated on ASVspoof 2021 DF and In-the-Wild datasets, our method achieves state-of-the-art performance (1.93% and 6.87% EER), improving over independent layer weighting by 36.6% and 22.5% respectively. The results and attention visualisations confirm that hierarchical modelling enhances generalisation to cross-domain generation techniques and recording conditions.
CEDL: Centre-Enhanced Discriminative Learning for Anomaly Detection
Nov 15, 2025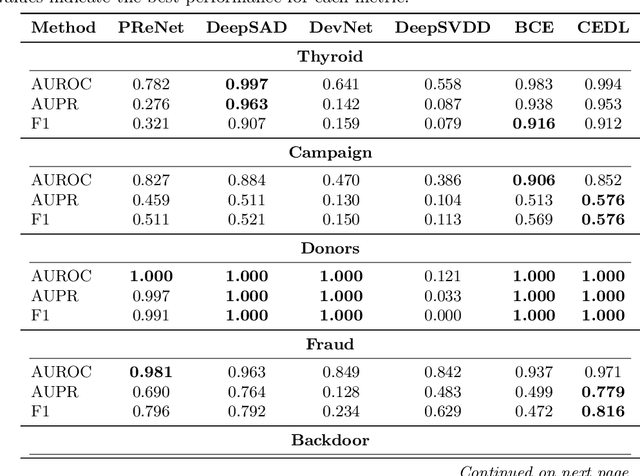
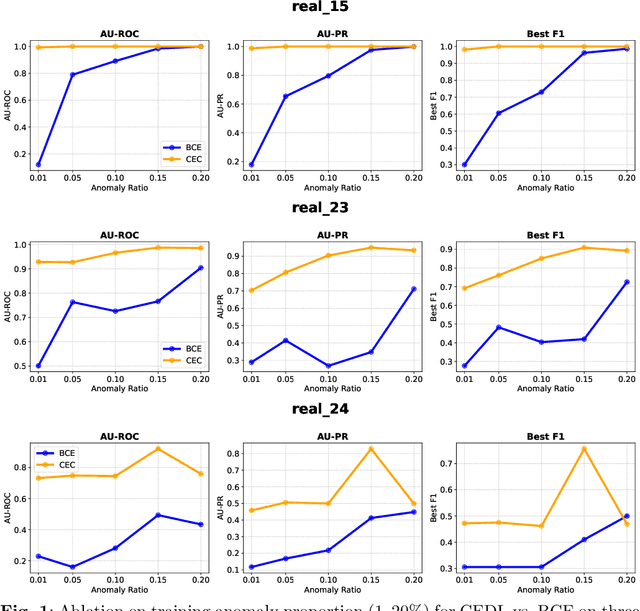
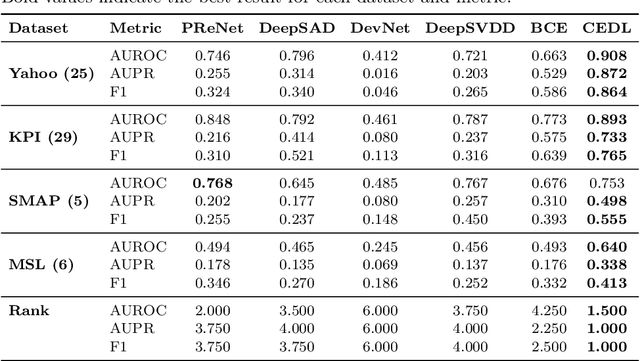
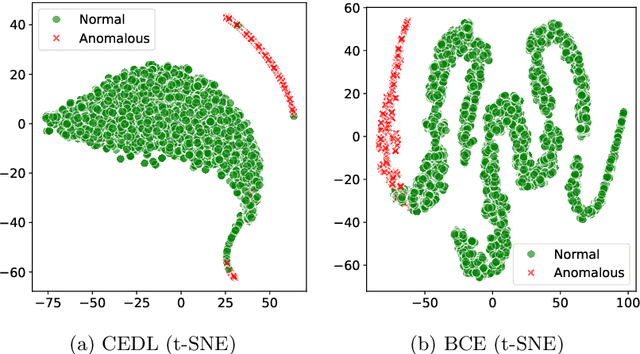
Supervised anomaly detection methods perform well in identifying known anomalies that are well represented in the training set. However, they often struggle to generalise beyond the training distribution due to decision boundaries that lack a clear definition of normality. Existing approaches typically address this by regularising the representation space during training, leading to separate optimisation in latent and label spaces. The learned normality is therefore not directly utilised at inference, and their anomaly scores often fall within arbitrary ranges that require explicit mapping or calibration for probabilistic interpretation. To achieve unified learning of geometric normality and label discrimination, we propose Centre-Enhanced Discriminative Learning (CEDL), a novel supervised anomaly detection framework that embeds geometric normality directly into the discriminative objective. CEDL reparameterises the conventional sigmoid-derived prediction logit through a centre-based radial distance function, unifying geometric and discriminative learning in a single end-to-end formulation. This design enables interpretable, geometry-aware anomaly scoring without post-hoc thresholding or reference calibration. Extensive experiments on tabular, time-series, and image data demonstrate that CEDL achieves competitive and balanced performance across diverse real-world anomaly detection tasks, validating its effectiveness and broad applicability.
AUDETER: A Large-scale Dataset for Deepfake Audio Detection in Open Worlds
Sep 04, 2025



Speech generation systems can produce remarkably realistic vocalisations that are often indistinguishable from human speech, posing significant authenticity challenges. Although numerous deepfake detection methods have been developed, their effectiveness in real-world environments remains unrealiable due to the domain shift between training and test samples arising from diverse human speech and fast evolving speech synthesis systems. This is not adequately addressed by current datasets, which lack real-world application challenges with diverse and up-to-date audios in both real and deep-fake categories. To fill this gap, we introduce AUDETER (AUdio DEepfake TEst Range), a large-scale, highly diverse deepfake audio dataset for comprehensive evaluation and robust development of generalised models for deepfake audio detection. It consists of over 4,500 hours of synthetic audio generated by 11 recent TTS models and 10 vocoders with a broad range of TTS/vocoder patterns, totalling 3 million audio clips, making it the largest deepfake audio dataset by scale. Through extensive experiments with AUDETER, we reveal that i) state-of-the-art (SOTA) methods trained on existing datasets struggle to generalise to novel deepfake audio samples and suffer from high false positive rates on unseen human voice, underscoring the need for a comprehensive dataset; and ii) these methods trained on AUDETER achieve highly generalised detection performance and significantly reduce detection error rate by 44.1% to 51.6%, achieving an error rate of only 4.17% on diverse cross-domain samples in the popular In-the-Wild dataset, paving the way for training generalist deepfake audio detectors. AUDETER is available on GitHub.
Exploring Criteria of Loss Reweighting to Enhance LLM Unlearning
May 17, 2025Loss reweighting has shown significant benefits for machine unlearning with large language models (LLMs). However, their exact functionalities are left unclear and the optimal strategy remains an open question, thus impeding the understanding and improvement of existing methodologies. In this paper, we identify two distinct goals of loss reweighting, namely, Saturation and Importance -- the former indicates that those insufficiently optimized data should be emphasized, while the latter stresses some critical data that are most influential for loss minimization. To study their usefulness, we design specific reweighting strategies for each goal and evaluate their respective effects on unlearning. We conduct extensive empirical analyses on well-established benchmarks, and summarize some important observations as follows: (i) Saturation enhances efficacy more than importance-based reweighting, and their combination can yield additional improvements. (ii) Saturation typically allocates lower weights to data with lower likelihoods, whereas importance-based reweighting does the opposite. (iii) The efficacy of unlearning is also largely influenced by the smoothness and granularity of the weight distributions. Based on these findings, we propose SatImp, a simple reweighting method that combines the advantages of both saturation and importance. Empirical results on extensive datasets validate the efficacy of our method, potentially bridging existing research gaps and indicating directions for future research. Our code is available at https://github.com/Puning97/SatImp-for-LLM-Unlearning.
Temporal-contextual Event Learning for Pedestrian Crossing Intent Prediction
Apr 04, 2025Ensuring the safety of vulnerable road users through accurate prediction of pedestrian crossing intention (PCI) plays a crucial role in the context of autonomous and assisted driving. Analyzing the set of observation video frames in ego-view has been widely used in most PCI prediction methods to forecast the cross intent. However, they struggle to capture the critical events related to pedestrian behaviour along the temporal dimension due to the high redundancy of the video frames, which results in the sub-optimal performance of PCI prediction. Our research addresses the challenge by introducing a novel approach called \underline{T}emporal-\underline{c}ontextual Event \underline{L}earning (TCL). The TCL is composed of the Temporal Merging Module (TMM), which aims to manage the redundancy by clustering the observed video frames into multiple key temporal events. Then, the Contextual Attention Block (CAB) is employed to adaptively aggregate multiple event features along with visual and non-visual data. By synthesizing the temporal feature extraction and contextual attention on the key information across the critical events, TCL can learn expressive representation for the PCI prediction. Extensive experiments are carried out on three widely adopted datasets, including PIE, JAAD-beh, and JAAD-all. The results show that TCL substantially surpasses the state-of-the-art methods. Our code can be accessed at https://github.com/dadaguailhb/TCL.
GRU: Mitigating the Trade-off between Unlearning and Retention for Large Language Models
Mar 12, 2025Large language model (LLM) unlearning has demonstrated its essential role in removing privacy and copyright-related responses, crucial for their legal and safe applications. However, the pursuit of complete unlearning often comes with substantial costs due to its compromises in their general functionality, leading to a notorious trade-off between unlearning and retention. In examining the update process for unlearning dynamically, we find gradients hold essential information for revealing this trade-off. In particular, we look at the varying relationship between retention performance and directional disparities between gradients during unlearning. It motivates the sculpting of an update mechanism derived from gradients from two sources, i.e., harmful for retention and useful for unlearning. Accordingly, we propose Gradient Rectified Unlearning (GRU), an enhanced unlearning framework controlling the updating gradients in a geometry-focused and optimization-driven manner such that their side impacts on other, unrelated responses can be minimized. Specifically, GRU derives a closed-form solution to project the unlearning gradient onto the orthogonal space of that gradient harmful for retention, ensuring minimal deviation from its original direction under the condition that overall performance is retained. Comprehensive experiments are conducted to demonstrate that GRU, as a general framework, is straightforward to implement and efficiently enhances a range of baseline methods through its adaptable and compatible characteristics. Additionally, experimental results show its broad effectiveness across a diverse set of benchmarks for LLM unlearning.
Rethinking LLM Unlearning Objectives: A Gradient Perspective and Go Beyond
Feb 26, 2025



Large language models (LLMs) should undergo rigorous audits to identify potential risks, such as copyright and privacy infringements. Once these risks emerge, timely updates are crucial to remove undesirable responses, ensuring legal and safe model usage. It has spurred recent research into LLM unlearning, focusing on erasing targeted undesirable knowledge without compromising the integrity of other, non-targeted responses. Existing studies have introduced various unlearning objectives to pursue LLM unlearning without necessitating complete retraining. However, each of these objectives has unique properties, and no unified framework is currently available to comprehend them thoroughly. To fill the gap, we propose a toolkit of the gradient effect (G-effect), quantifying the impacts of unlearning objectives on model performance from a gradient perspective. A notable advantage is its broad ability to detail the unlearning impacts from various aspects across instances, updating steps, and LLM layers. Accordingly, the G-effect offers new insights into identifying drawbacks of existing unlearning objectives, further motivating us to explore a series of new solutions for their mitigation and improvements. Finally, we outline promising directions that merit further studies, aiming at contributing to the community to advance this important field.
GenIAS: Generator for Instantiating Anomalies in time Series
Feb 12, 2025



A recent and promising approach for building time series anomaly detection (TSAD) models is to inject synthetic samples of anomalies within real data sets. The existing injection mechanisms have significant limitations - most of them rely on ad hoc, hand-crafted strategies which fail to capture the natural diversity of anomalous patterns, or are restricted to univariate time series settings. To address these challenges, we design a generative model for TSAD using a variational autoencoder, which is referred to as a Generator for Instantiating Anomalies in Time Series (GenIAS). GenIAS is designed to produce diverse and realistic synthetic anomalies for TSAD tasks. By employing a novel learned perturbation mechanism in the latent space and injecting the perturbed patterns in different segments of time series, GenIAS can generate anomalies with greater diversity and varying scales. Further, guided by a new triplet loss function, which uses a min-max margin and a new variance-scaling approach to further enforce the learning of compact normal patterns, GenIAS ensures that anomalies are distinct from normal samples while remaining realistic. The approach is effective for both univariate and multivariate time series. We demonstrate the diversity and realism of the generated anomalies. Our extensive experiments demonstrate that GenIAS - when integrated into a TSAD task - consistently outperforms seventeen traditional and deep anomaly detection models, thereby highlighting the potential of generative models for time series anomaly generation.