 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinancial Transaction Retrieval and Contextual Evidence for Knowledge-Grounded Reasoning
Mar 16, 2026Nowadays, success of financial organizations heavily depends on their ability to process digital traces generated by their clients, e.g., transaction histories, gathered from various sources to improve user modeling pipelines. As general-purpose LLMs struggle with time-distributed tabular data, production stacks still depend on specialized tabular and sequence models with limited transferability and need for labeled data. To address this, we introduce FinTRACE, a retrieval-first architecture that converts raw transactions into reusable feature representations, applies rule-based detectors, and stores the resulting signals in a behavioral knowledge base with graded associations to the objectives of downstream tasks. Across public and industrial benchmarks, FinTRACE substantially improves low-supervision transaction analytics, doubling zero-shot MCC on churn prediction performance from 0.19 to 0.38 and improving 16-shot MCC from 0.25 to 0.40. We further use FinTRACE to ground LLMs via instruction tuning on retrieved behavioral patterns, achieving state-of-the-art LLM results on transaction analytics problems.
Embedding-Aware Feature Discovery: Bridging Latent Representations and Interpretable Features in Event Sequences
Mar 16, 2026Industrial financial systems operate on temporal event sequences such as transactions, user actions, and system logs. While recent research emphasizes representation learning and large language models, production systems continue to rely heavily on handcrafted statistical features due to their interpretability, robustness under limited supervision, and strict latency constraints. This creates a persistent disconnect between learned embeddings and feature-based pipelines. We introduce Embedding-Aware Feature Discovery (EAFD), a unified framework that bridges this gap by coupling pretrained event-sequence embeddings with a self-reflective LLM-driven feature generation agent. EAFD iteratively discovers, evaluates, and refines features directly from raw event sequences using two complementary criteria: \emph{alignment}, which explains information already encoded in embeddings, and \emph{complementarity}, which identifies predictive signals missing from them. Across both open-source and industrial transaction benchmarks, EAFD consistently outperforms embedding-only and feature-based baselines, achieving relative gains of up to $+5.8\%$ over state-of-the-art pretrained embeddings, resulting in new state-of-the-art performance across event-sequence datasets.
Topological Metric for Unsupervised Embedding Quality Evaluation
Dec 17, 2025Modern representation learning increasingly relies on unsupervised and self-supervised methods trained on large-scale unlabeled data. While these approaches achieve impressive generalization across tasks and domains, evaluating embedding quality without labels remains an open challenge. In this work, we propose Persistence, a topology-aware metric based on persistent homology that quantifies the geometric structure and topological richness of embedding spaces in a fully unsupervised manner. Unlike metrics that assume linear separability or rely on covariance structure, Persistence captures global and multi-scale organization. Empirical results across diverse domains show that Persistence consistently achieves top-tier correlations with downstream performance, outperforming existing unsupervised metrics and enabling reliable model and hyperparameter selection.
PINE: Pipeline for Important Node Exploration in Attributed Networks
Dec 08, 2025
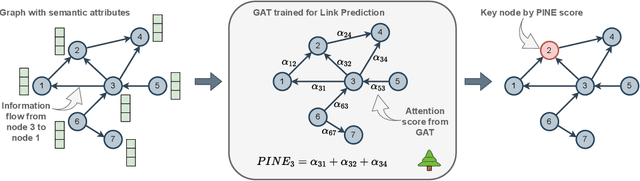
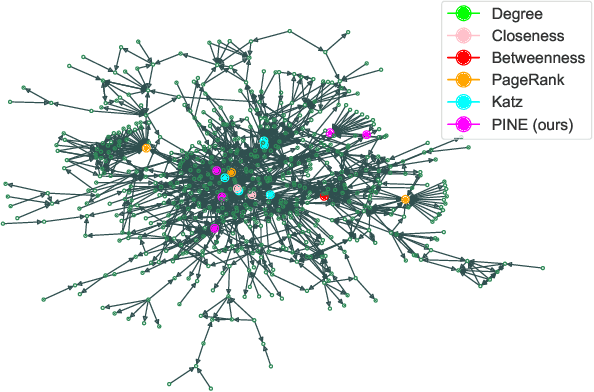
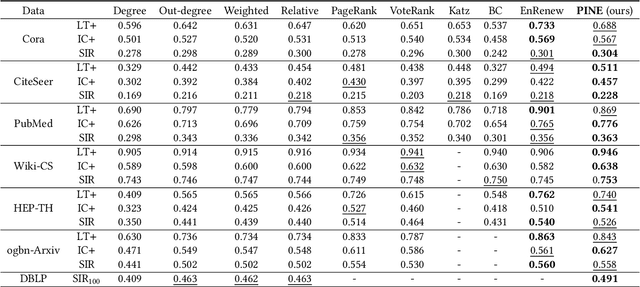
A graph with semantically attributed nodes are a common data structure in a wide range of domains. It could be interlinked web data or citation networks of scientific publications. The essential problem for such a data type is to determine nodes that carry greater importance than all the others, a task that markedly enhances system monitoring and management. Traditional methods to identify important nodes in networks introduce centrality measures, such as node degree or more complex PageRank. However, they consider only the network structure, neglecting the rich node attributes. Recent methods adopt neural networks capable of handling node features, but they require supervision. This work addresses the identified gap--the absence of approaches that are both unsupervised and attribute-aware--by introducing a Pipeline for Important Node Exploration (PINE). At the core of the proposed framework is an attention-based graph model that incorporates node semantic features in the learning process of identifying the structural graph properties. The PINE's node importance scores leverage the obtained attention distribution. We demonstrate the superior performance of the proposed PINE method on various homogeneous and heterogeneous attributed networks. As an industry-implemented system, PINE tackles the real-world challenge of unsupervised identification of key entities within large-scale enterprise graphs.
Artificial intelligence optical hardware empowers high-resolution hyperspectral video understanding at 1.2 Tb/s
Dec 17, 2023Foundation models, exemplified by GPT technology, are discovering new horizons in artificial intelligence by executing tasks beyond their designers' expectations. While the present generation provides fundamental advances in understanding language and images, the next frontier is video comprehension. Progress in this area must overcome the 1 Tb/s data rate demanded to grasp real-time multidimensional video information. This speed limit lies well beyond the capabilities of the existing generation of hardware, imposing a roadblock to further advances. This work introduces a hardware-accelerated integrated optoelectronic platform for multidimensional video understanding in real-time. The technology platform combines artificial intelligence hardware, processing information optically, with state-of-the-art machine vision networks, resulting in a data processing speed of 1.2 Tb/s with hundreds of frequency bands and megapixel spatial resolution at video rates. Such performance, validated in the AI tasks of video semantic segmentation and object understanding in indoor and aerial applications, surpasses the speed of the closest technologies with similar spectral resolution by three to four orders of magnitude. This platform opens up new avenues for research in real-time AI video understanding of multidimensional visual information, helping the empowerment of future human-machine interactions and cognitive processing developments.
Adaptive Compression for Communication-Efficient Distributed Training
Oct 31, 2022
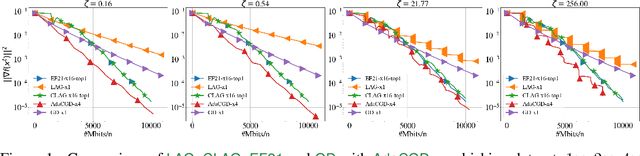

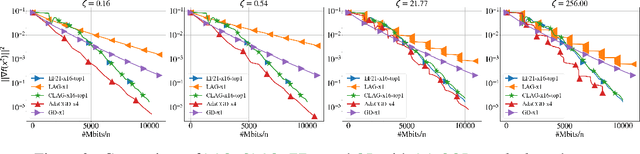
We propose Adaptive Compressed Gradient Descent (AdaCGD) - a novel optimization algorithm for communication-efficient training of supervised machine learning models with adaptive compression level. Our approach is inspired by the recently proposed three point compressor (3PC) framework of Richtarik et al. (2022), which includes error feedback (EF21), lazily aggregated gradient (LAG), and their combination as special cases, and offers the current state-of-the-art rates for these methods under weak assumptions. While the above mechanisms offer a fixed compression level, or adapt between two extremes only, our proposal is to perform a much finer adaptation. In particular, we allow the user to choose any number of arbitrarily chosen contractive compression mechanisms, such as Top-K sparsification with a user-defined selection of sparsification levels K, or quantization with a user-defined selection of quantization levels, or their combination. AdaCGD chooses the appropriate compressor and compression level adaptively during the optimization process. Besides i) proposing a theoretically-grounded multi-adaptive communication compression mechanism, we further ii) extend the 3PC framework to bidirectional compression, i.e., we allow the server to compress as well, and iii) provide sharp convergence bounds in the strongly convex, convex and nonconvex settings. The convex regime results are new even for several key special cases of our general mechanism, including 3PC and EF21. In all regimes, our rates are superior compared to all existing adaptive compression methods.
Real-time Hyperspectral Imaging in Hardware via Trained Metasurface Encoders
Apr 05, 2022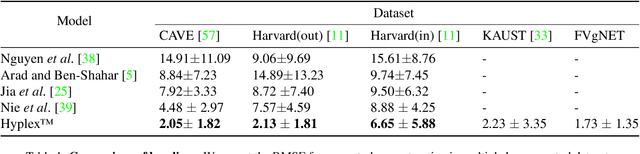

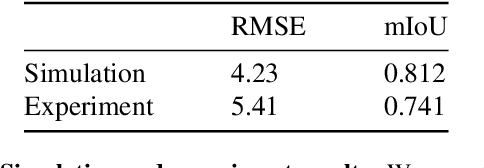
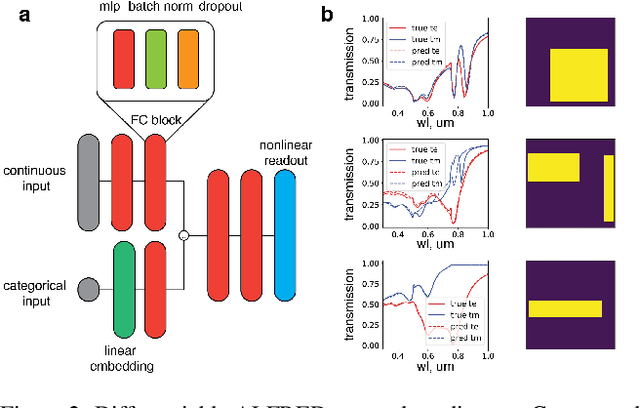
Hyperspectral imaging has attracted significant attention to identify spectral signatures for image classification and automated pattern recognition in computer vision. State-of-the-art implementations of snapshot hyperspectral imaging rely on bulky, non-integrated, and expensive optical elements, including lenses, spectrometers, and filters. These macroscopic components do not allow fast data processing for, e.g real-time and high-resolution videos. This work introduces Hyplex, a new integrated architecture addressing the limitations discussed above. Hyplex is a CMOS-compatible, fast hyperspectral camera that replaces bulk optics with nanoscale metasurfaces inversely designed through artificial intelligence. Hyplex does not require spectrometers but makes use of conventional monochrome cameras, opening up the possibility for real-time and high-resolution hyperspectral imaging at inexpensive costs. Hyplex exploits a model-driven optimization, which connects the physical metasurfaces layer with modern visual computing approaches based on end-to-end training. We design and implement a prototype version of Hyplex and compare its performance against the state-of-the-art for typical imaging tasks such as spectral reconstruction and semantic segmentation. In all benchmarks, Hyplex reports the smallest reconstruction error. We additionally present what is, to the best of our knowledge, the largest publicly available labeled hyperspectral dataset for semantic segmentation.
SDA-GAN: Unsupervised Image Translation Using Spectral Domain Attention-Guided Generative Adversarial Network
Oct 06, 2021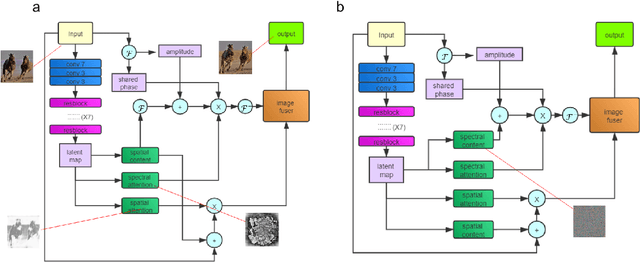
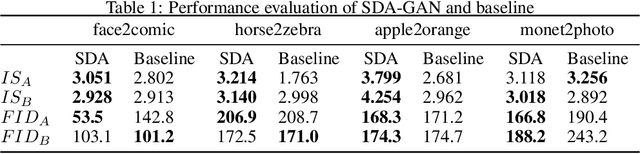

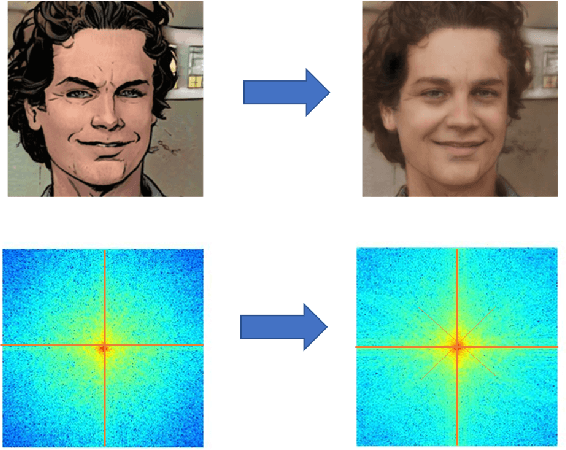
This work introduced a novel GAN architecture for unsupervised image translation on the task of face style transform. A spectral attention-based mechanism is embedded into the design along with spatial attention on the image contents. We proved that neural network has the potential of learning complex transformations such as Fourier transform, within considerable computational cost. The model is trained and tested in comparison to the baseline model, which only uses spatial attention. The performance improvement of our approach is significant especially when the source and target domain include different complexity (reduced FID to 49.18 from 142.84). In the translation process, a spectra filling effect was introduced due to the implementation of FFT and spectral attention. Another style transfer task and real-world object translation are also studied in this paper.