 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRingmaster LMO: Asynchronous Linear Minimization Oracle Momentum Method
May 18, 2026Muon has recently emerged as a strong alternative to AdamW for training neural networks, with encouraging large-scale pretraining results and growing evidence that matrix-structured updates can be faster in practice. Yet Muon, and more generally Linear Minimization Oracle (LMO) based methods, are typically used synchronously. This is problematic in heterogeneous distributed systems, where workers complete gradient computations at different speeds and synchronous training must repeatedly wait for slower workers. In this work, we introduce Ringmaster LMO, an asynchronous LMO-based momentum method for unconstrained stochastic nonconvex optimization. Our method builds on the delay-thresholding idea of Ringmaster ASGD. For SGD-type methods, Ringmaster ASGD achieves optimal time complexity by discarding overly stale gradients. Ringmaster LMO extends this mechanism to general LMO-based updates. We establish convergence guarantees under generalized $(L_0, L_1)$-smoothness and further develop a parameter-agnostic variant with decreasing stepsizes and adaptive delay thresholds. Finally, we translate our iteration guarantees into time complexity bounds under heterogeneous worker computation times. In the classical Euclidean smooth setting, these bounds recover the optimal time complexity of Ringmaster ASGD. Experiments on stochastic quadratic problems and NanoChat language-model pretraining show that the advantages of Ringmaster LMO grow with system heterogeneity and that the method outperforms strong synchronous and asynchronous baselines.
Better LMO-based Momentum Methods with Second-Order Information
Dec 15, 2025The use of momentum in stochastic optimization algorithms has shown empirical success across a range of machine learning tasks. Recently, a new class of stochastic momentum algorithms has emerged within the Linear Minimization Oracle (LMO) framework--leading to state-of-the-art methods, such as Muon, Scion, and Gluon, that effectively solve deep neural network training problems. However, traditional stochastic momentum methods offer convergence guarantees no better than the ${O}(1/K^{1/4})$ rate. While several approaches--such as Hessian-Corrected Momentum (HCM)--have aimed to improve this rate, their theoretical results are generally restricted to the Euclidean norm setting. This limitation hinders their applicability in problems, where arbitrary norms are often required. In this paper, we extend the LMO-based framework by integrating HCM, and provide convergence guarantees under relaxed smoothness and arbitrary norm settings. We establish improved convergence rates of ${O}(1/K^{1/3})$ for HCM, which can adapt to the geometry of the problem and achieve a faster rate than traditional momentum. Experimental results on training Multi-Layer Perceptrons (MLPs) and Long Short-Term Memory (LSTM) networks verify our theoretical observations.
Improved Convergence in Parameter-Agnostic Error Feedback through Momentum
Nov 18, 2025Communication compression is essential for scalable distributed training of modern machine learning models, but it often degrades convergence due to the noise it introduces. Error Feedback (EF) mechanisms are widely adopted to mitigate this issue of distributed compression algorithms. Despite their popularity and training efficiency, existing distributed EF algorithms often require prior knowledge of problem parameters (e.g., smoothness constants) to fine-tune stepsizes. This limits their practical applicability especially in large-scale neural network training. In this paper, we study normalized error feedback algorithms that combine EF with normalized updates, various momentum variants, and parameter-agnostic, time-varying stepsizes, thus eliminating the need for problem-dependent tuning. We analyze the convergence of these algorithms for minimizing smooth functions, and establish parameter-agnostic complexity bounds that are close to the best-known bounds with carefully-tuned problem-dependent stepsizes. Specifically, we show that normalized EF21 achieve the convergence rate of near ${O}(1/T^{1/4})$ for Polyak's heavy-ball momentum, ${O}(1/T^{2/7})$ for Iterative Gradient Transport (IGT), and ${O}(1/T^{1/3})$ for STORM and Hessian-corrected momentum. Our results hold with decreasing stepsizes and small mini-batches. Finally, our empirical experiments confirm our theoretical insights.
Differentially Private Random Block Coordinate Descent
Dec 22, 2024
Coordinate Descent (CD) methods have gained significant attention in machine learning due to their effectiveness in solving high-dimensional problems and their ability to decompose complex optimization tasks. However, classical CD methods were neither designed nor analyzed with data privacy in mind, a critical concern when handling sensitive information. This has led to the development of differentially private CD methods, such as DP-CD (Differentially Private Coordinate Descent) proposed by Mangold et al. (ICML 2022), yet a disparity remains between non-private CD and DP-CD methods. In our work, we propose a differentially private random block coordinate descent method that selects multiple coordinates with varying probabilities in each iteration using sketch matrices. Our algorithm generalizes both DP-CD and the classical DP-SGD (Differentially Private Stochastic Gradient Descent), while preserving the same utility guarantees. Furthermore, we demonstrate that better utility can be achieved through importance sampling, as our method takes advantage of the heterogeneity in coordinate-wise smoothness constants, leading to improved convergence rates.
Error Feedback under $(L_0,L_1)$-Smoothness: Normalization and Momentum
Oct 22, 2024



We provide the first proof of convergence for normalized error feedback algorithms across a wide range of machine learning problems. Despite their popularity and efficiency in training deep neural networks, traditional analyses of error feedback algorithms rely on the smoothness assumption that does not capture the properties of objective functions in these problems. Rather, these problems have recently been shown to satisfy generalized smoothness assumptions, and the theoretical understanding of error feedback algorithms under these assumptions remains largely unexplored. Moreover, to the best of our knowledge, all existing analyses under generalized smoothness either i) focus on single-node settings or ii) make unrealistically strong assumptions for distributed settings, such as requiring data heterogeneity, and almost surely bounded stochastic gradient noise variance. In this paper, we propose distributed error feedback algorithms that utilize normalization to achieve the $O(1/\sqrt{K})$ convergence rate for nonconvex problems under generalized smoothness. Our analyses apply for distributed settings without data heterogeneity conditions, and enable stepsize tuning that is independent of problem parameters. Additionally, we provide strong convergence guarantees of normalized error feedback algorithms for stochastic settings. Finally, we show that due to their larger allowable stepsizes, our new normalized error feedback algorithms outperform their non-normalized counterparts on various tasks, including the minimization of polynomial functions, logistic regression, and ResNet-20 training.
SPAM: Stochastic Proximal Point Method with Momentum Variance Reduction for Non-convex Cross-Device Federated Learning
May 30, 2024
Cross-device training is a crucial subfield of federated learning, where the number of clients can reach into the billions. Standard approaches and local methods are prone to issues such as client drift and insensitivity to data similarities. We propose a novel algorithm (SPAM) for cross-device federated learning with non-convex losses, which solves both issues. We provide sharp analysis under second-order (Hessian) similarity, a condition satisfied by a variety of machine learning problems in practice. Additionally, we extend our results to the partial participation setting, where a cohort of selected clients communicate with the server at each communication round. Our method is the first in its kind, that does not require the smoothness of the objective and provably benefits from clients having similar data.
A Unified Theory of Stochastic Proximal Point Methods without Smoothness
May 24, 2024This paper presents a comprehensive analysis of a broad range of variations of the stochastic proximal point method (SPPM). Proximal point methods have attracted considerable interest owing to their numerical stability and robustness against imperfect tuning, a trait not shared by the dominant stochastic gradient descent (SGD) algorithm. A framework of assumptions that we introduce encompasses methods employing techniques such as variance reduction and arbitrary sampling. A cornerstone of our general theoretical approach is a parametric assumption on the iterates, correction and control vectors. We establish a single theorem that ensures linear convergence under this assumption and the $\mu$-strong convexity of the loss function, and without the need to invoke smoothness. This integral theorem reinstates best known complexity and convergence guarantees for several existing methods which demonstrates the robustness of our approach. We expand our study by developing three new variants of SPPM, and through numerical experiments we elucidate various properties inherent to them.
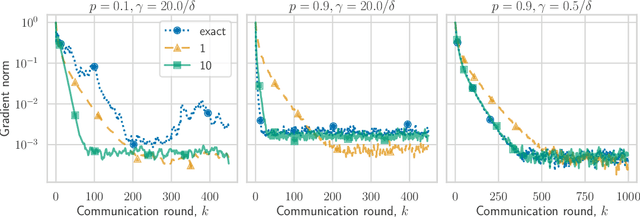
High-Probability Convergence for Composite and Distributed Stochastic Minimization and Variational Inequalities with Heavy-Tailed Noise
Oct 03, 2023

High-probability analysis of stochastic first-order optimization methods under mild assumptions on the noise has been gaining a lot of attention in recent years. Typically, gradient clipping is one of the key algorithmic ingredients to derive good high-probability guarantees when the noise is heavy-tailed. However, if implemented na\"ively, clipping can spoil the convergence of the popular methods for composite and distributed optimization (Prox-SGD/Parallel SGD) even in the absence of any noise. Due to this reason, many works on high-probability analysis consider only unconstrained non-distributed problems, and the existing results for composite/distributed problems do not include some important special cases (like strongly convex problems) and are not optimal. To address this issue, we propose new stochastic methods for composite and distributed optimization based on the clipping of stochastic gradient differences and prove tight high-probability convergence results (including nearly optimal ones) for the new methods. Using similar ideas, we also develop new methods for composite and distributed variational inequalities and analyze the high-probability convergence of these methods.
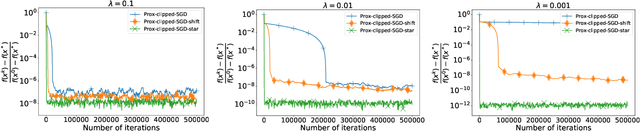
High-Probability Bounds for Stochastic Optimization and Variational Inequalities: the Case of Unbounded Variance
Feb 02, 2023

During recent years the interest of optimization and machine learning communities in high-probability convergence of stochastic optimization methods has been growing. One of the main reasons for this is that high-probability complexity bounds are more accurate and less studied than in-expectation ones. However, SOTA high-probability non-asymptotic convergence results are derived under strong assumptions such as the boundedness of the gradient noise variance or of the objective's gradient itself. In this paper, we propose several algorithms with high-probability convergence results under less restrictive assumptions. In particular, we derive new high-probability convergence results under the assumption that the gradient/operator noise has bounded central $\alpha$-th moment for $\alpha \in (1,2]$ in the following setups: (i) smooth non-convex / Polyak-Lojasiewicz / convex / strongly convex / quasi-strongly convex minimization problems, (ii) Lipschitz / star-cocoercive and monotone / quasi-strongly monotone variational inequalities. These results justify the usage of the considered methods for solving problems that do not fit standard functional classes studied in stochastic optimization.
Adaptive Compression for Communication-Efficient Distributed Training
Oct 31, 2022
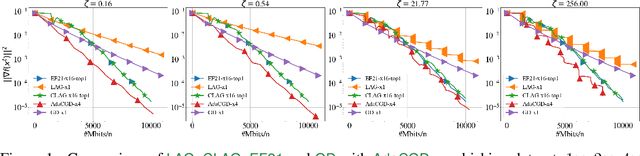

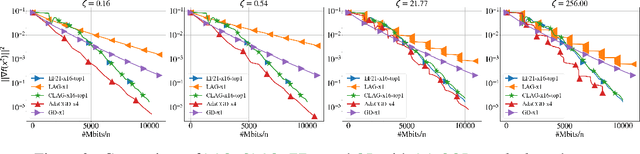
We propose Adaptive Compressed Gradient Descent (AdaCGD) - a novel optimization algorithm for communication-efficient training of supervised machine learning models with adaptive compression level. Our approach is inspired by the recently proposed three point compressor (3PC) framework of Richtarik et al. (2022), which includes error feedback (EF21), lazily aggregated gradient (LAG), and their combination as special cases, and offers the current state-of-the-art rates for these methods under weak assumptions. While the above mechanisms offer a fixed compression level, or adapt between two extremes only, our proposal is to perform a much finer adaptation. In particular, we allow the user to choose any number of arbitrarily chosen contractive compression mechanisms, such as Top-K sparsification with a user-defined selection of sparsification levels K, or quantization with a user-defined selection of quantization levels, or their combination. AdaCGD chooses the appropriate compressor and compression level adaptively during the optimization process. Besides i) proposing a theoretically-grounded multi-adaptive communication compression mechanism, we further ii) extend the 3PC framework to bidirectional compression, i.e., we allow the server to compress as well, and iii) provide sharp convergence bounds in the strongly convex, convex and nonconvex settings. The convex regime results are new even for several key special cases of our general mechanism, including 3PC and EF21. In all regimes, our rates are superior compared to all existing adaptive compression methods.