 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study on Monthly Marine Heatwave Forecasts in New Zealand: An Investigation of Imbalanced Regression Loss Functions with Neural Network Models
Feb 19, 2025Marine heatwaves (MHWs) are extreme ocean-temperature events with significant impacts on marine ecosystems and related industries. Accurate forecasts (one to six months ahead) of MHWs would aid in mitigating these impacts. However, forecasting MHWs presents a challenging imbalanced regression task due to the rarity of extreme temperature anomalies in comparison to more frequent moderate conditions. In this study, we examine monthly MHW forecasts for 12 locations around New Zealand. We use a fully-connected neural network and compare standard and specialized regression loss functions, including the mean squared error (MSE), the mean absolute error (MAE), the Huber, the weighted MSE, the focal-R, the balanced MSE, and a proposed scaling-weighted MSE. Results show that (i) short lead times (one month) are considerably more predictable than three- and six-month leads, (ii) models trained with the standard MSE or MAE losses excel at forecasting average conditions but struggle to capture extremes, and (iii) specialized loss functions such as the balanced MSE and our scaling-weighted MSE substantially improve forecasting of MHW and suspected MHW events. These findings underscore the importance of tailored loss functions for imbalanced regression, particularly in forecasting rare but impactful events such as MHWs.
Gradient Descent and the Power Method: Exploiting their connection to find the leftmost eigen-pair and escape saddle points
Nov 02, 2022



This work shows that applying Gradient Descent (GD) with a fixed step size to minimize a (possibly nonconvex) quadratic function is equivalent to running the Power Method (PM) on the gradients. The connection between GD with a fixed step size and the PM, both with and without fixed momentum, is thus established. Consequently, valuable eigen-information is available via GD. Recent examples show that GD with a fixed step size, applied to locally quadratic nonconvex functions, can take exponential time to escape saddle points (Simon S. Du, Chi Jin, Jason D. Lee, Michael I. Jordan, Aarti Singh, and Barnabas Poczos: "Gradient descent can take exponential time to escape saddle points"; S. Paternain, A. Mokhtari, and A. Ribeiro: "A newton-based method for nonconvex optimization with fast evasion of saddle points"). Here, those examples are revisited and it is shown that eigenvalue information was missing, so that the examples may not provide a complete picture of the potential practical behaviour of GD. Thus, ongoing investigation of the behaviour of GD on nonconvex functions, possibly with an \emph{adaptive} or \emph{variable} step size, is warranted. It is shown that, in the special case of a quadratic in $R^2$, if an eigenvalue is known, then GD with a fixed step size will converge in two iterations, and a complete eigen-decomposition is available. By considering the dynamics of the gradients and iterates, new step size strategies are proposed to improve the practical performance of GD. Several numerical examples are presented, which demonstrate the advantages of exploiting the GD--PM connection.
Stochastic Gradient Methods with Preconditioned Updates
Jun 01, 2022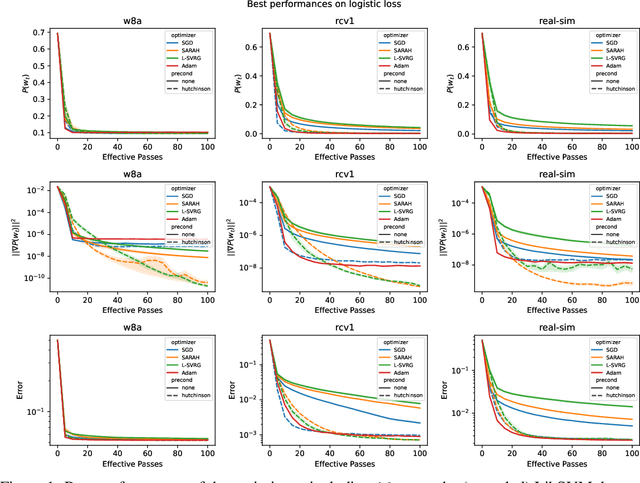
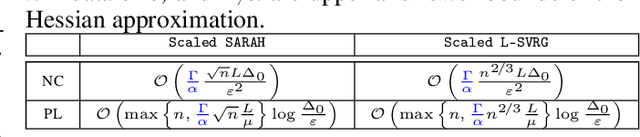
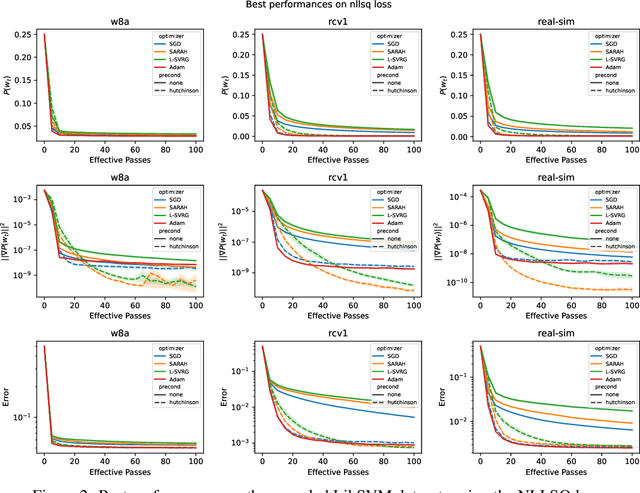

This work considers non-convex finite sum minimization. There are a number of algorithms for such problems, but existing methods often work poorly when the problem is badly scaled and/or ill-conditioned, and a primary goal of this work is to introduce methods that alleviate this issue. Thus, here we include a preconditioner that is based upon Hutchinson's approach to approximating the diagonal of the Hessian, and couple it with several gradient based methods to give new `scaled' algorithms: {\tt Scaled SARAH} and {\tt Scaled L-SVRG}. Theoretical complexity guarantees under smoothness assumptions are presented, and we prove linear convergence when both smoothness and the PL-condition is assumed. Because our adaptively scaled methods use approximate partial second order curvature information, they are better able to mitigate the impact of badly scaled problems, and this improved practical performance is demonstrated in the numerical experiments that are also presented in this work.
SONIA: A Symmetric Blockwise Truncated Optimization Algorithm
Jun 06, 2020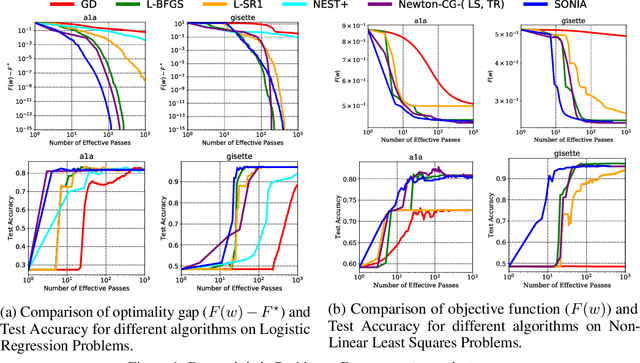
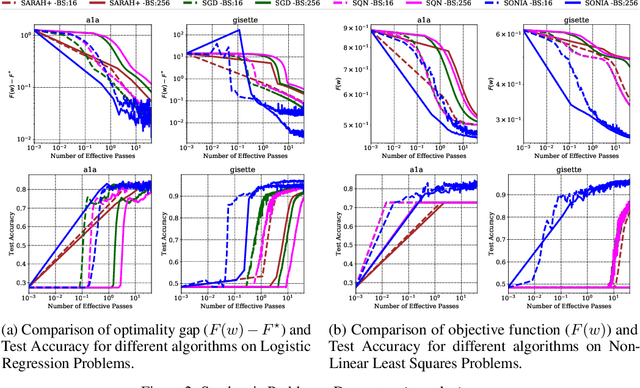


This work presents a new algorithm for empirical risk minimization. The algorithm bridges the gap between first- and second-order methods by computing a search direction that uses a second-order-type update in one subspace, coupled with a scaled steepest descent step in the orthogonal complement. To this end, partial curvature information is incorporated to help with ill-conditioning, while simultaneously allowing the algorithm to scale to the large problem dimensions often encountered in machine learning applications. Theoretical results are presented to confirm that the algorithm converges to a stationary point in both the strongly convex and nonconvex cases. A stochastic variant of the algorithm is also presented, along with corresponding theoretical guarantees. Numerical results confirm the strengths of the new approach on standard machine learning problems.
Underestimate Sequences via Quadratic Averaging
Oct 10, 2017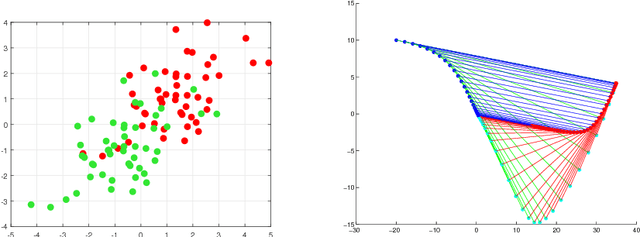

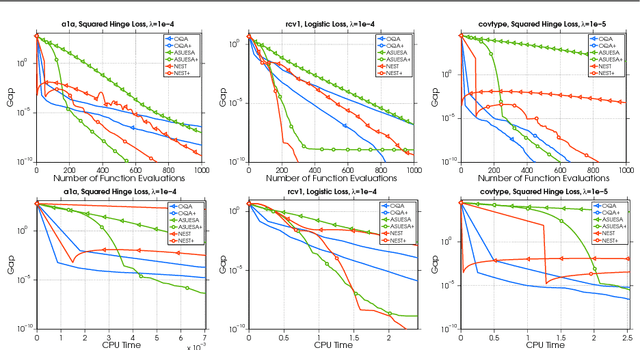
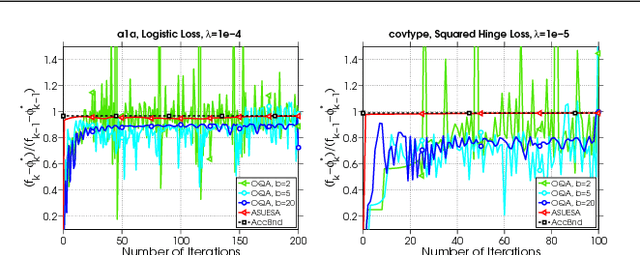
In this work we introduce the concept of an Underestimate Sequence (UES), which is a natural extension of Nesterov's estimate sequence. Our definition of a UES utilizes three sequences, one of which is a lower bound (or under-estimator) of the objective function. The question of how to construct an appropriate sequence of lower bounds is also addressed, and we present lower bounds for strongly convex smooth functions and for strongly convex composite functions, which adhere to the UES framework. Further, we propose several first order methods for minimizing strongly convex functions in both the smooth and composite cases. The algorithms, based on efficiently updating lower bounds on the objective functions, have natural stopping conditions, which provides the user with a certificate of optimality. Convergence of all algorithms is guaranteed through the UES framework, and we show that all presented algorithms converge linearly, with the accelerated variants enjoying the optimal linear rate of convergence.
Linear Convergence of the Randomized Feasible Descent Method Under the Weak Strong Convexity Assumption
Jun 08, 2015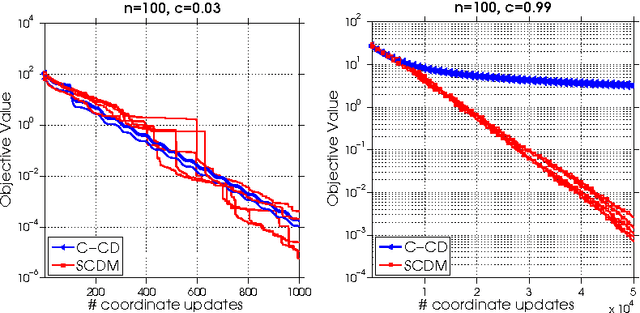
In this paper we generalize the framework of the feasible descent method (FDM) to a randomized (R-FDM) and a coordinate-wise random feasible descent method (RC-FDM) framework. We show that the famous SDCA algorithm for optimizing the SVM dual problem, or the stochastic coordinate descent method for the LASSO problem, fits into the framework of RC-FDM. We prove linear convergence for both R-FDM and RC-FDM under the weak strong convexity assumption. Moreover, we show that the duality gap converges linearly for RC-FDM, which implies that the duality gap also converges linearly for SDCA applied to the SVM dual problem.
Inexact Coordinate Descent: Complexity and Preconditioning
Dec 10, 2014
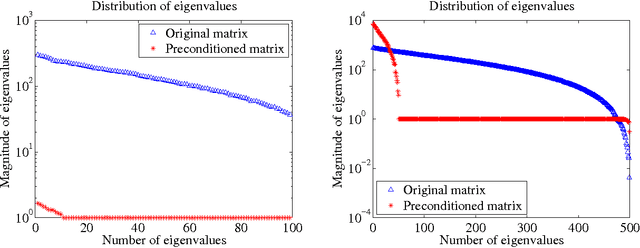
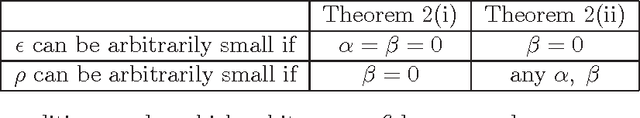
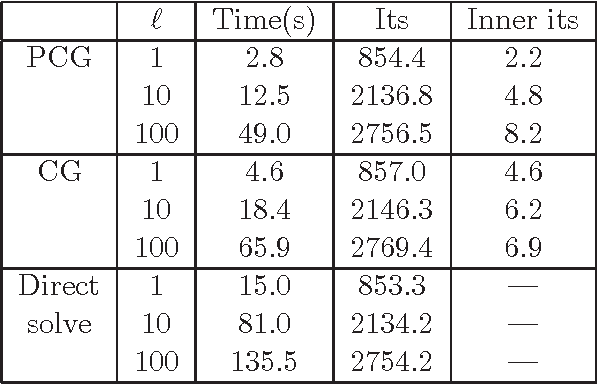
In this paper we consider the problem of minimizing a convex function using a randomized block coordinate descent method. One of the key steps at each iteration of the algorithm is determining the update to a block of variables. Existing algorithms assume that in order to compute the update, a particular subproblem is solved exactly. In his work we relax this requirement, and allow for the subproblem to be solved inexactly, leading to an inexact block coordinate descent method. Our approach incorporates the best known results for exact updates as a special case. Moreover, these theoretical guarantees are complemented by practical considerations: the use of iterative techniques to determine the update as well as the use of preconditioning for further acceleration.
Separable Approximations and Decomposition Methods for the Augmented Lagrangian
Aug 30, 2013

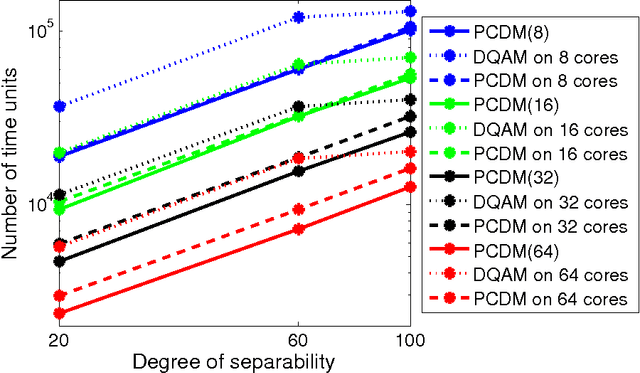
In this paper we study decomposition methods based on separable approximations for minimizing the augmented Lagrangian. In particular, we study and compare the Diagonal Quadratic Approximation Method (DQAM) of Mulvey and Ruszczy\'{n}ski and the Parallel Coordinate Descent Method (PCDM) of Richt\'arik and Tak\'a\v{c}. We show that the two methods are equivalent for feasibility problems up to the selection of a single step-size parameter. Furthermore, we prove an improved complexity bound for PCDM under strong convexity, and show that this bound is at least $8(L'/\bar{L})(\omega-1)^2$ times better than the best known bound for DQAM, where $\omega$ is the degree of partial separability and $L'$ and $\bar{L}$ are the maximum and average of the block Lipschitz constants of the gradient of the quadratic penalty appearing in the augmented Lagrangian.