 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoubly Adaptive Scaled Algorithm for Machine Learning Using Second-Order Information
Sep 11, 2021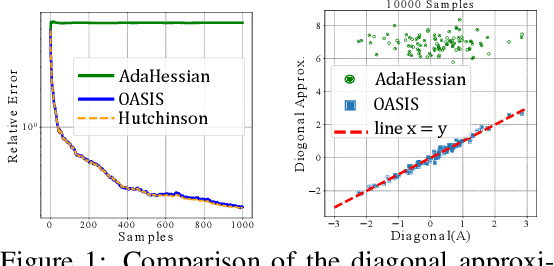
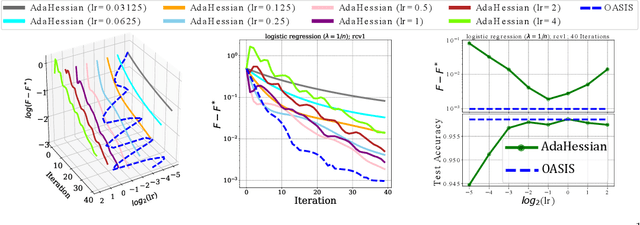
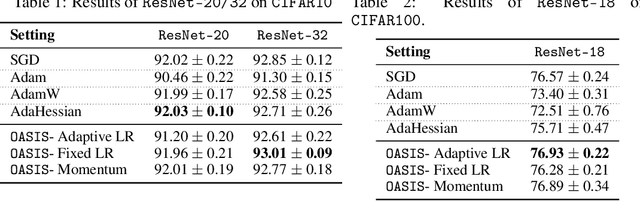

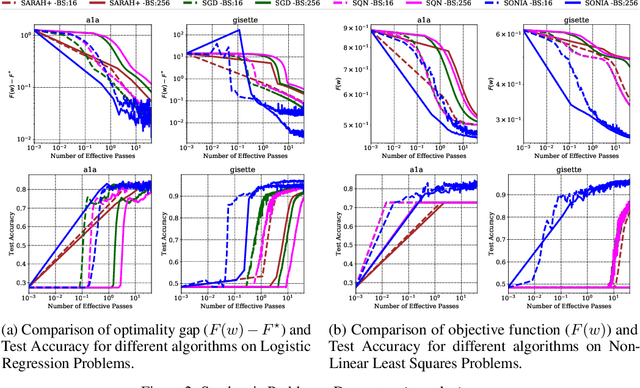
We present a novel adaptive optimization algorithm for large-scale machine learning problems. Equipped with a low-cost estimate of local curvature and Lipschitz smoothness, our method dynamically adapts the search direction and step-size. The search direction contains gradient information preconditioned by a well-scaled diagonal preconditioning matrix that captures the local curvature information. Our methodology does not require the tedious task of learning rate tuning, as the learning rate is updated automatically without adding an extra hyperparameter. We provide convergence guarantees on a comprehensive collection of optimization problems, including convex, strongly convex, and nonconvex problems, in both deterministic and stochastic regimes. We also conduct an extensive empirical evaluation on standard machine learning problems, justifying our algorithm's versatility and demonstrating its strong performance compared to other start-of-the-art first-order and second-order methods.
DynNet: Physics-based neural architecture design for linear and nonlinear structural response modeling and prediction
Jul 03, 2020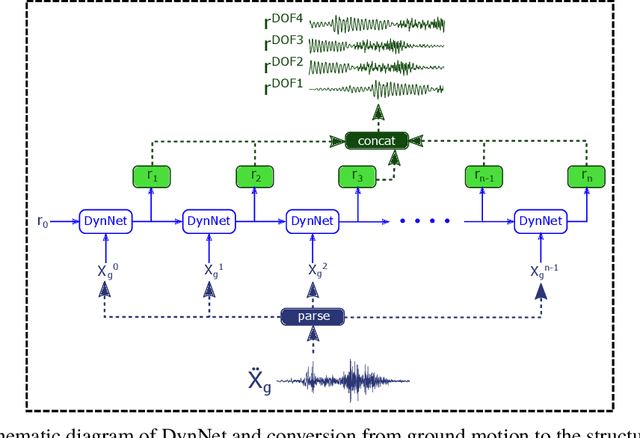
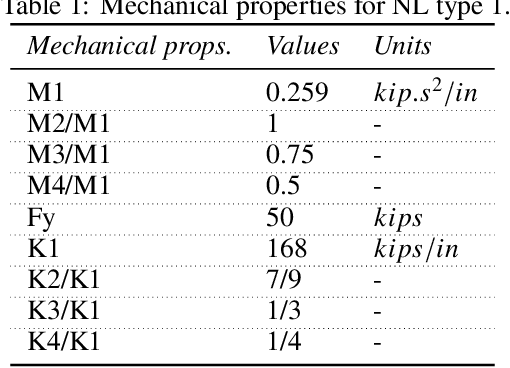
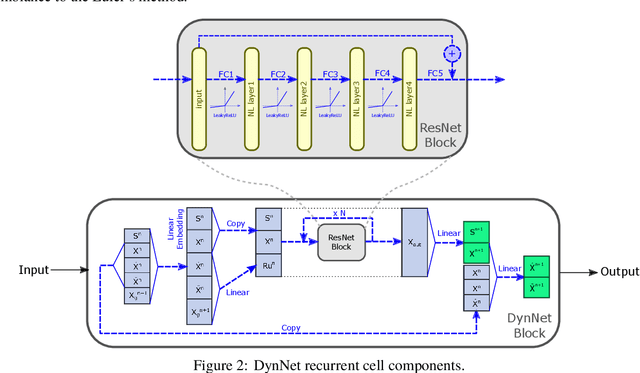
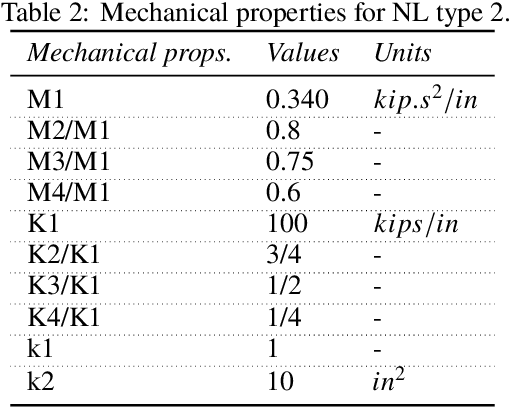
Data-driven models for predicting dynamic responses of linear and nonlinear systems are of great importance due to their wide application from probabilistic analysis to inverse problems such as system identification and damage diagnosis. In this study, a physics-based recurrent neural network model is designed that is able to learn the dynamics of linear and nonlinear multiple degrees of freedom systems given a ground motion. The model is able to estimate a complete set of responses, including displacement, velocity, acceleration, and internal forces. Compared to the most advanced counterparts, this model requires a smaller number of trainable variables while the accuracy of predictions is higher for long trajectories. In addition, the architecture of the recurrent block is inspired by differential equation solver algorithms and it is expected that this approach yields more generalized solutions. In the training phase, we propose multiple novel techniques to dramatically accelerate the learning process using smaller datasets, such as hardsampling, utilization of trajectory loss function, and implementation of a trust-region approach. Numerical case studies are conducted to examine the strength of the network to learn different nonlinear behaviors. It is shown that the network is able to capture different nonlinear behaviors of dynamic systems with very high accuracy and with no need for prior information or very large datasets.
SONIA: A Symmetric Blockwise Truncated Optimization Algorithm
Jun 06, 2020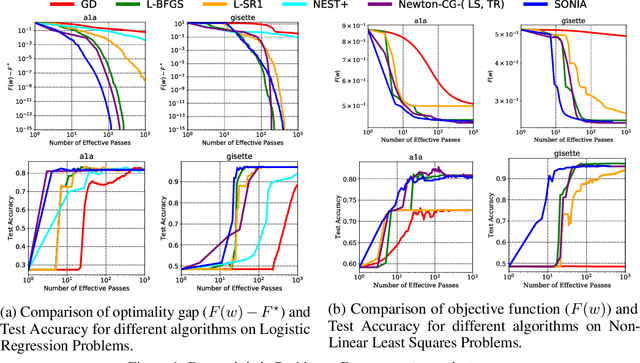


This work presents a new algorithm for empirical risk minimization. The algorithm bridges the gap between first- and second-order methods by computing a search direction that uses a second-order-type update in one subspace, coupled with a scaled steepest descent step in the orthogonal complement. To this end, partial curvature information is incorporated to help with ill-conditioning, while simultaneously allowing the algorithm to scale to the large problem dimensions often encountered in machine learning applications. Theoretical results are presented to confirm that the algorithm converges to a stationary point in both the strongly convex and nonconvex cases. A stochastic variant of the algorithm is also presented, along with corresponding theoretical guarantees. Numerical results confirm the strengths of the new approach on standard machine learning problems.
Scaling Up Quasi-Newton Algorithms: Communication Efficient Distributed SR1
May 30, 2019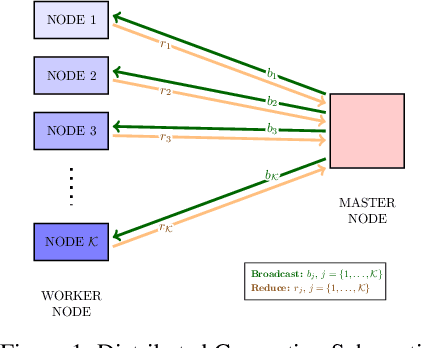
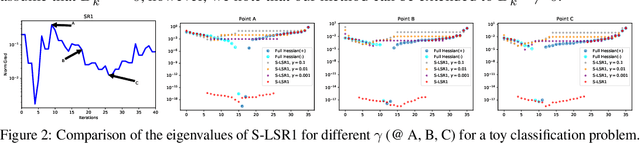
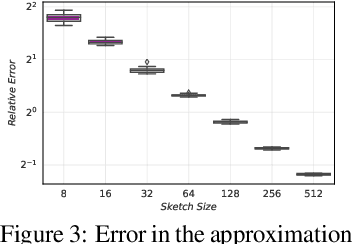

In this paper, we present a scalable distributed implementation of the sampled LSR1 (S-LSR1) algorithm. First, we show that a naive distributed implementation of S-LSR1 requires multiple rounds of expensive communications at every iteration and thus is inefficient. We then propose DS-LSR1, a communication-efficient variant of the S-LSR1 method, that drastically reduces the amount of data communicated at every iteration, that has favorable work-load balancing across nodes and that is matrix-free and inverse-free. The proposed method scales well in terms of both the dimension of the problem and the number of data points. Finally, we illustrate the performance of DS-LSR1 on standard neural network training tasks.
Don't Forget Your Teacher: A Corrective Reinforcement Learning Framework
May 30, 2019
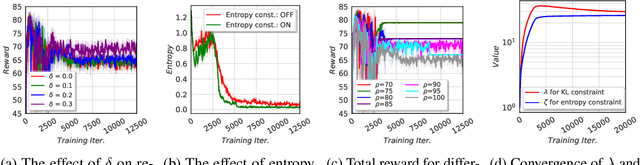
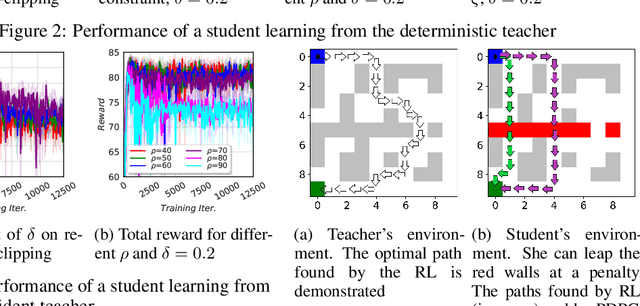
Although reinforcement learning (RL) can provide reliable solutions in many settings, practitioners are often wary of the discrepancies between the RL solution and their status quo procedures. Therefore, they may be reluctant to adapt to the novel way of executing tasks proposed by RL. On the other hand, many real-world problems require relatively small adjustments from the status quo policies to achieve improved performance. Therefore, we propose a student-teacher RL mechanism in which the RL (the "student") learns to maximize its reward, subject to a constraint that bounds the difference between the RL policy and the "teacher" policy. The teacher can be another RL policy (e.g., trained under a slightly different setting), the status quo policy, or any other exogenous policy. We formulate this problem using a stochastic optimization model and solve it using a primal-dual policy gradient algorithm. We prove that the policy is asymptotically optimal. However, a naive implementation suffers from high variance and convergence to a stochastic optimal policy. With a few practical adjustments to address these issues, our numerical experiments confirm the effectiveness of our proposed method in multiple GridWorld scenarios.
Quasi-Newton Methods for Deep Learning: Forget the Past, Just Sample
Jan 28, 2019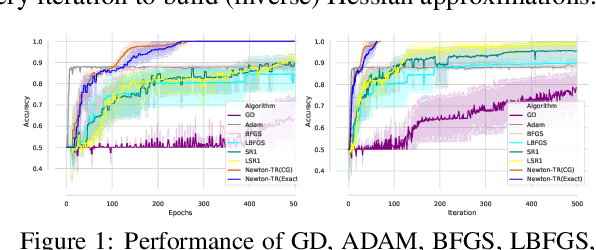

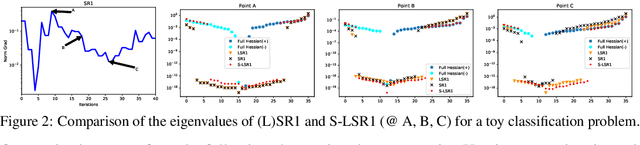
We present two sampled quasi-Newton methods for deep learning: sampled LBFGS (S-LBFGS) and sampled LSR1 (S-LSR1). Contrary to the classical variants of these methods that sequentially build Hessian or inverse Hessian approximations as the optimization progresses, our proposed methods sample points randomly around the current iterate at every iteration to produce these approximations. As a result, the approximations constructed make use of more reliable (recent and local) information, and do not depend on past iterate information that could be significantly stale. Our proposed algorithms are efficient in terms of accessed data points (epochs) and have enough concurrency to take advantage of parallel/distributed computing environments. We provide convergence guarantees for our proposed methods. Numerical tests on a toy classification problem as well as on popular benchmarking neural network training tasks reveal that the methods outperform their classical variants and are competitive with state-of-the-art first-order methods such as ADAM.
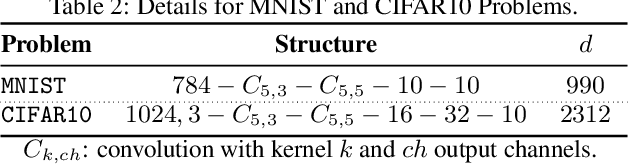
Efficient Distributed Hessian Free Algorithm for Large-scale Empirical Risk Minimization via Accumulating Sample Strategy
Oct 26, 2018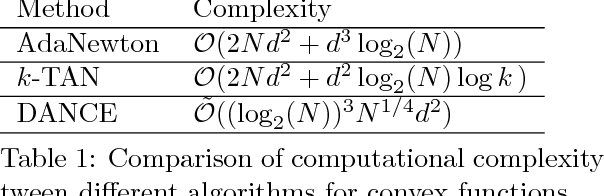

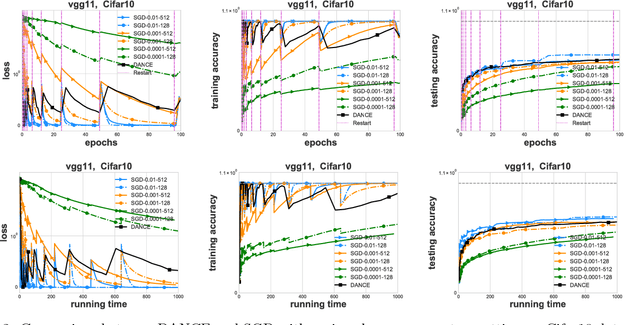
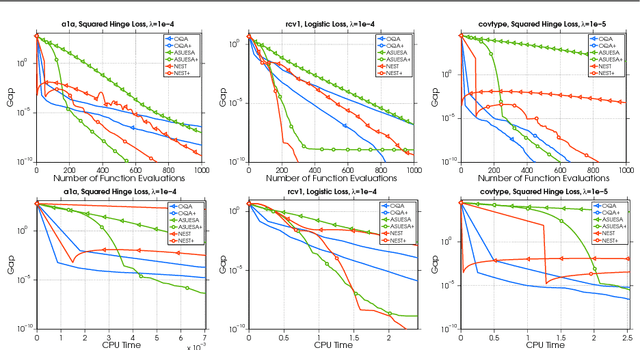
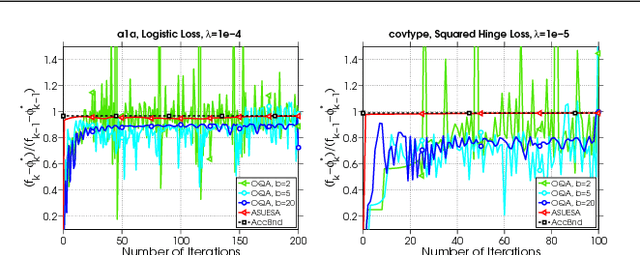
In this paper, we propose a Distributed Accumulated Newton Conjugate gradiEnt (DANCE) method in which sample size is gradually increasing to quickly obtain a solution whose empirical loss is under satisfactory statistical accuracy. Our proposed method is multistage in which the solution of a stage serves as a warm start for the next stage which contains more samples (including the samples in the previous stage). The proposed multistage algorithm reduces the number of passes over data to achieve the statistical accuracy of the full training set. Moreover, our algorithm in nature is easy to be distributed and shares the strong scaling property indicating that acceleration is always expected by using more computing nodes. Various iteration complexity results regarding descent direction computation, communication efficiency and stopping criteria are analyzed under convex setting. Our numerical results illustrate that the proposed method outperforms other comparable methods for solving learning problems including neural networks.
Underestimate Sequences via Quadratic Averaging
Oct 10, 2017

In this work we introduce the concept of an Underestimate Sequence (UES), which is a natural extension of Nesterov's estimate sequence. Our definition of a UES utilizes three sequences, one of which is a lower bound (or under-estimator) of the objective function. The question of how to construct an appropriate sequence of lower bounds is also addressed, and we present lower bounds for strongly convex smooth functions and for strongly convex composite functions, which adhere to the UES framework. Further, we propose several first order methods for minimizing strongly convex functions in both the smooth and composite cases. The algorithms, based on efficiently updating lower bounds on the objective functions, have natural stopping conditions, which provides the user with a certificate of optimality. Convergence of all algorithms is guaranteed through the UES framework, and we show that all presented algorithms converge linearly, with the accelerated variants enjoying the optimal linear rate of convergence.