 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Decision Making for Stochastic Multi-echelon Inventory Optimization with Deep Neural Networks as Decision Makers
Jun 10, 2020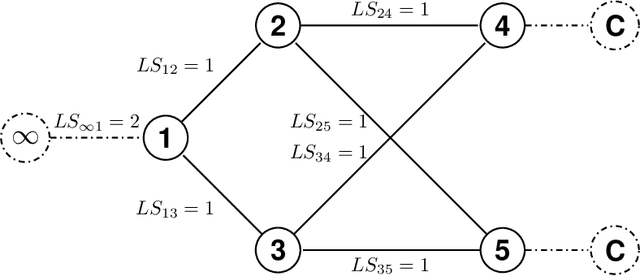
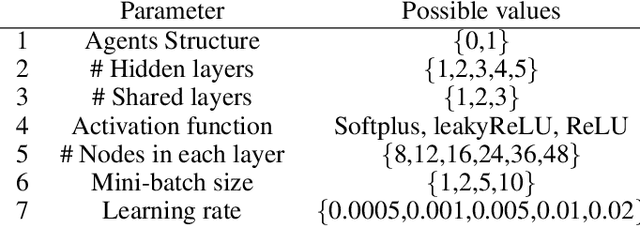
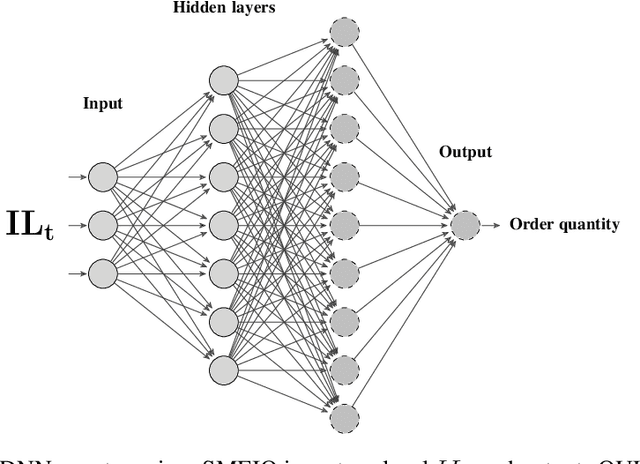
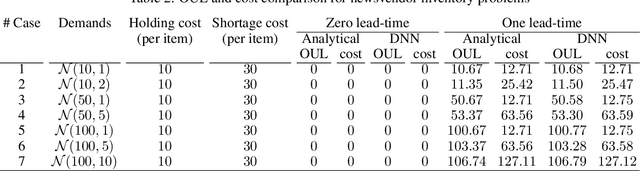
This study focuses on simultaneous decision making for stochastic multi-echelon inventory optimization problems. Mixed supply chain networks are considered that may contain assembly or distribution nodes, or both, and may use nonlinear cost structure. We present a framework which uses deep neural networks as agents responsible for finding order-up-to levels for any desired components of the general supply chain network. Agents simultaneously interact with the environment in an unsupervised manner to minimize total inventory cost. Not only does this study consider several decision-makers simultaneously for stages of a general supply chain network, but it also presents clear and interpretable order-up-to levels. First, we numerically show the effectiveness of the method by solving newsvendor and serial supply chain networks and compare the results with the available closed form solutions for these settings. Then, we investigate a mixed supply chain network and a more general case study. The findings indicate that the proposed method performs better in terms of objective function values and the number of interactions with the environment compared to alternatives. In addition, the method finds inventory policies similar to simple base-stock policies for general SCNs. Moreover, we generally notice that for echelons closer to the source, fixed optimal order-up-to levels can be considerably larger than the expected demands these echelons observe.
C. H. Robinson Uses Heuristics to Solve Rich Vehicle Routing Problems
Dec 31, 2019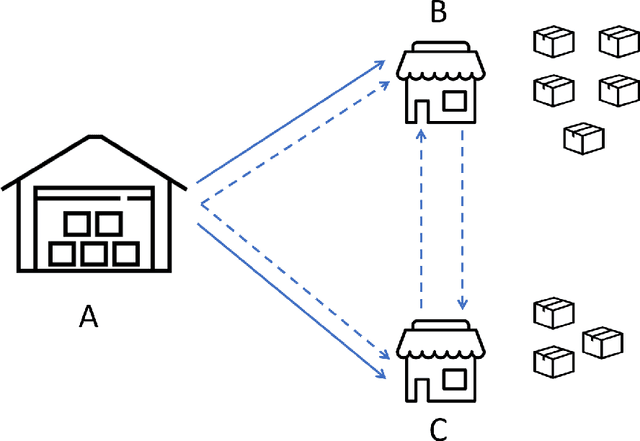
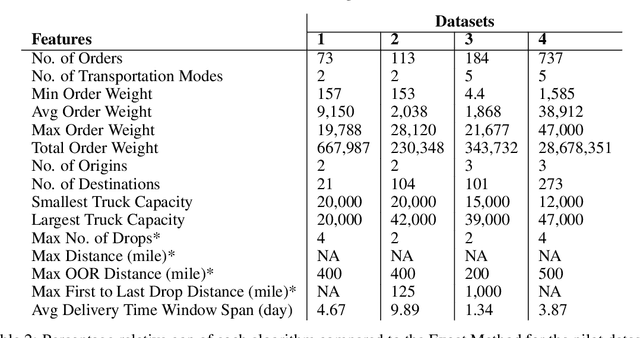

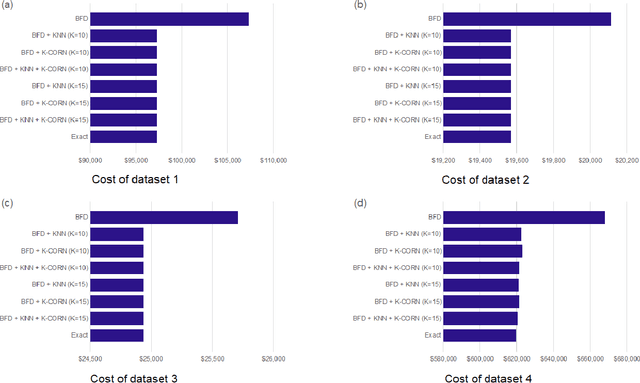
We consider a wide family of vehicle routing problem variants with many complex and practical constraints, known as rich vehicle routing problems, which are faced on a daily basis by C.H. Robinson (CHR). Since CHR has many customers, each with distinct requirements, various routing problems with different objectives and constraints should be solved. We propose a set partitioning framework with a number of route generation algorithms, which have shown to be effective in solving a variety of different problems. The proposed algorithms have outperformed the existing technologies at CHR on 10 benchmark instances and since, have been embedded into the company's transportation planning and execution technology platform.
Feature Engineering and Forecasting via Integration of Derivative-free Optimization and Ensemble of Sequence-to-sequence Networks: Renewable Energy Case Studies
Sep 12, 2019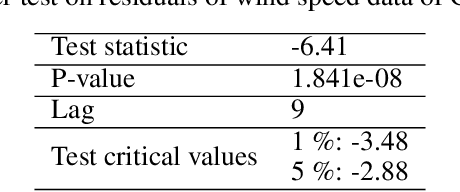
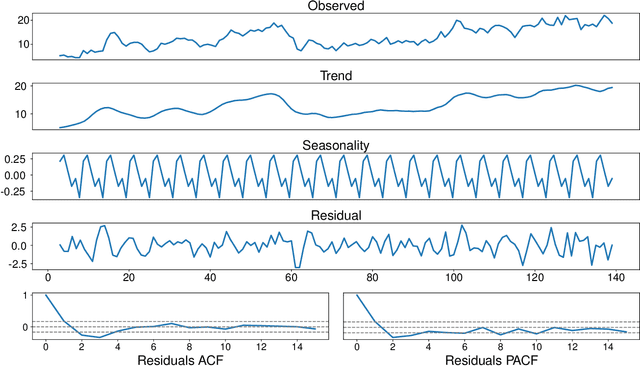
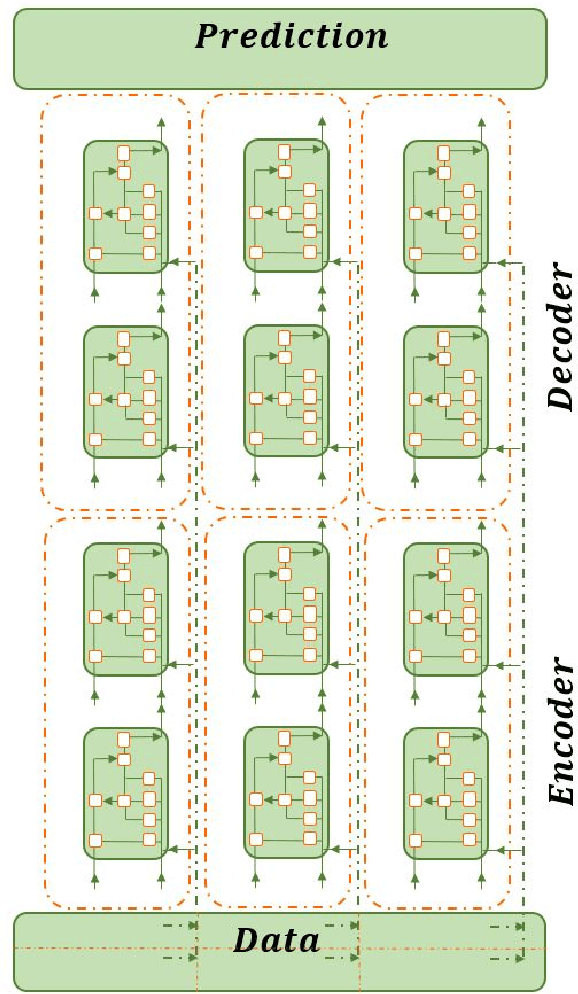

This research introduces a framework for forecasting, reconstruction and feature engineering of multivariate processes. We integrate derivative-free optimization with ensemble of sequence-to-sequence networks. We design a new resampling technique called additive which along with Bootstrap aggregating (bagging) resampling are applied to initialize the ensemble structure. We explore the proposed framework performance on three renewable energy sources wind, solar and ocean wave. We conduct several short- to long-term forecasts showing the superiority of the proposed method compare to numerous machine learning techniques. The findings indicate that the introduced method performs reasonably better when the forecasting horizon becomes longer. In addition, we modify the framework for automated feature selection. The model represents a clear interpretation of the selected features. We investigate the effects of different environmental and marine factors on the wind speed and ocean output power respectively and report the selected features. Moreover, we explore the online forecasting setting and illustrate that the model exceeds alternatives through different measurement errors.
Multivariate, Multistep Forecasting, Reconstruction and Feature Selection of Ocean Waves via Recurrent and Sequence-to-Sequence Networks
Jun 01, 2019
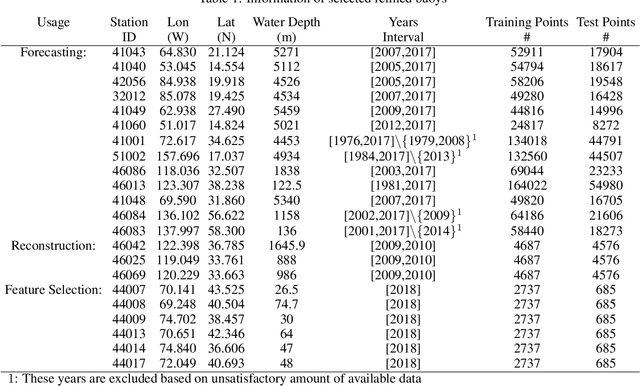
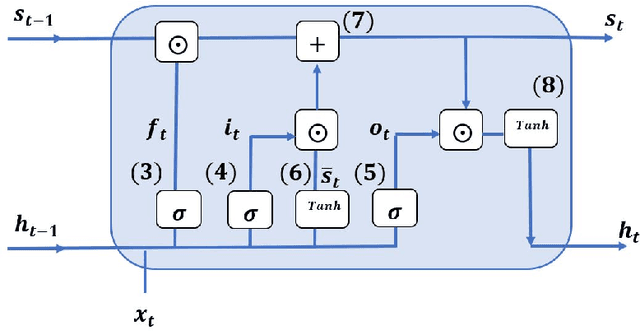
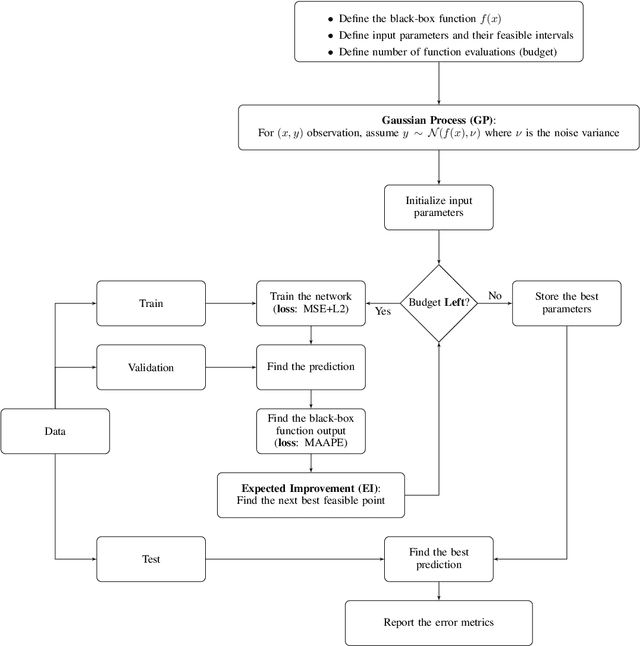
This article explores the concepts of ocean wave multivariate multistep forecasting, reconstruction and feature selection. We introduce recurrent neural network frameworks, integrated with Bayesian hyperparameter optimization and Elastic Net methods. We consider both short- and long-term forecasts and reconstruction, for significant wave height and output power of the ocean waves. Sequence-to-sequence neural networks are being developed for the first time to reconstruct the missing characteristics of ocean waves based on information from nearby wave sensors. Our results indicate that the Adam and AMSGrad optimization algorithms are the most robust ones to optimize the sequence-to-sequence network. For the case of significant wave height reconstruction, we compare the proposed methods with alternatives on a well-studied dataset. We show the superiority of the proposed methods considering several error metrics. We design a new case study based on measurement stations along the east coast of the United States and investigate the feature selection concept. Comparisons substantiate the benefit of utilizing Elastic Net. Moreover, case study results indicate that when the number of features is considerable, having deeper structures improves the performance.
Don't Forget Your Teacher: A Corrective Reinforcement Learning Framework
May 30, 2019
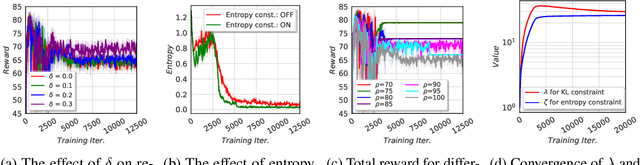
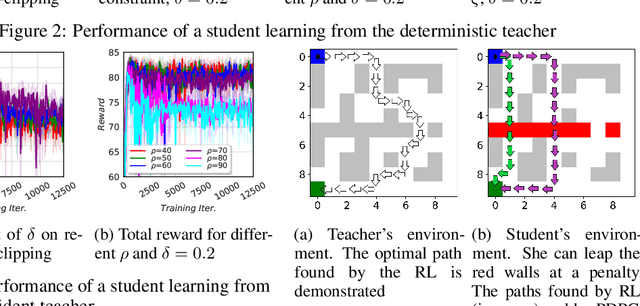
Although reinforcement learning (RL) can provide reliable solutions in many settings, practitioners are often wary of the discrepancies between the RL solution and their status quo procedures. Therefore, they may be reluctant to adapt to the novel way of executing tasks proposed by RL. On the other hand, many real-world problems require relatively small adjustments from the status quo policies to achieve improved performance. Therefore, we propose a student-teacher RL mechanism in which the RL (the "student") learns to maximize its reward, subject to a constraint that bounds the difference between the RL policy and the "teacher" policy. The teacher can be another RL policy (e.g., trained under a slightly different setting), the status quo policy, or any other exogenous policy. We formulate this problem using a stochastic optimization model and solve it using a primal-dual policy gradient algorithm. We prove that the policy is asymptotically optimal. However, a naive implementation suffers from high variance and convergence to a stochastic optimal policy. With a few practical adjustments to address these issues, our numerical experiments confirm the effectiveness of our proposed method in multiple GridWorld scenarios.
Reinforcement Learning for Solving the Vehicle Routing Problem
May 21, 2018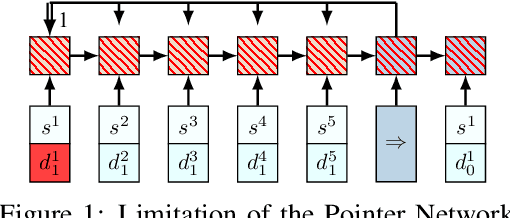
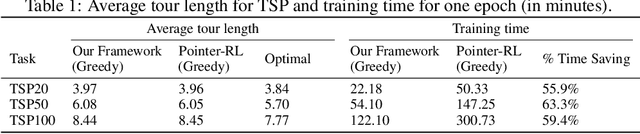
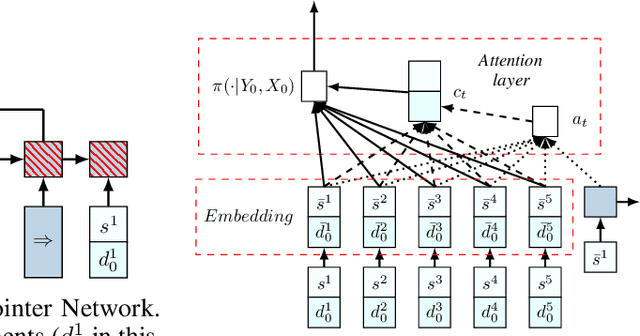
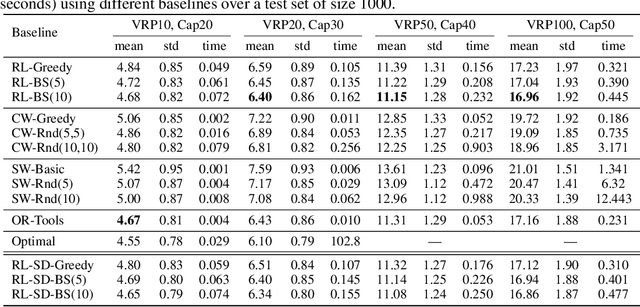
We present an end-to-end framework for solving the Vehicle Routing Problem (VRP) using reinforcement learning. In this approach, we train a single model that finds near-optimal solutions for problem instances sampled from a given distribution, only by observing the reward signals and following feasibility rules. Our model represents a parameterized stochastic policy, and by applying a policy gradient algorithm to optimize its parameters, the trained model produces the solution as a sequence of consecutive actions in real time, without the need to re-train for every new problem instance. On capacitated VRP, our approach outperforms classical heuristics and Google's OR-Tools on medium-sized instances in solution quality with comparable computation time (after training). We demonstrate how our approach can handle problems with split delivery and explore the effect of such deliveries on the solution quality. Our proposed framework can be applied to other variants of the VRP such as the stochastic VRP, and has the potential to be applied more generally to combinatorial optimization problems.