 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTree-based Dialogue Reinforced Policy Optimization for Red-Teaming Attacks
Oct 02, 2025Despite recent rapid progress in AI safety, current large language models remain vulnerable to adversarial attacks in multi-turn interaction settings, where attackers strategically adapt their prompts across conversation turns and pose a more critical yet realistic challenge. Existing approaches that discover safety vulnerabilities either rely on manual red-teaming with human experts or employ automated methods using pre-defined templates and human-curated attack data, with most focusing on single-turn attacks. However, these methods did not explore the vast space of possible multi-turn attacks, failing to consider novel attack trajectories that emerge from complex dialogue dynamics and strategic conversation planning. This gap is particularly critical given recent findings that LLMs exhibit significantly higher vulnerability to multi-turn attacks compared to single-turn attacks. We propose DialTree-RPO, an on-policy reinforcement learning framework integrated with tree search that autonomously discovers diverse multi-turn attack strategies by treating the dialogue as a sequential decision-making problem, enabling systematic exploration without manually curated data. Through extensive experiments, our approach not only achieves more than 25.9% higher ASR across 10 target models compared to previous state-of-the-art approaches, but also effectively uncovers new attack strategies by learning optimal dialogue policies that maximize attack success across multiple turns.
Towards optimized actions in critical situations of soccer games with deep reinforcement learning
Sep 14, 2021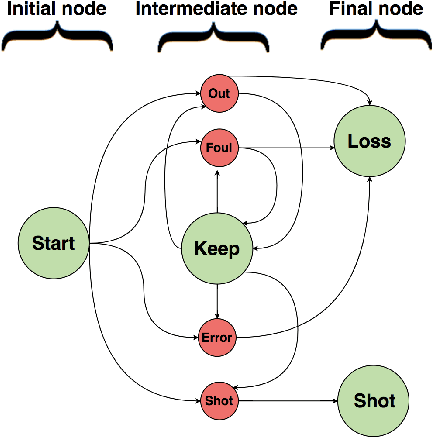
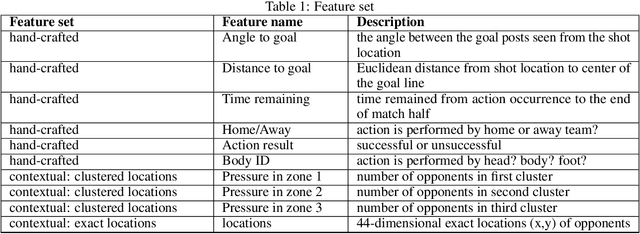
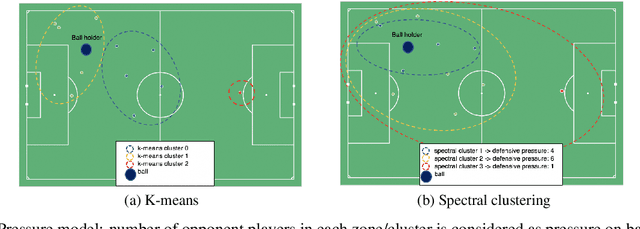
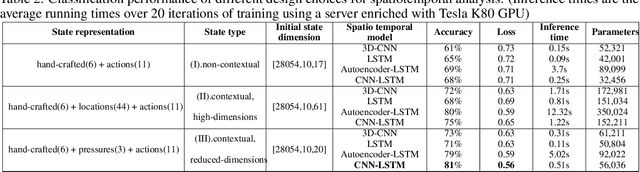
Soccer is a sparse rewarding game: any smart or careless action in critical situations can change the result of the match. Therefore players, coaches, and scouts are all curious about the best action to be performed in critical situations, such as the times with a high probability of losing ball possession or scoring a goal. This work proposes a new state representation for the soccer game and a batch reinforcement learning to train a smart policy network. This network gets the contextual information of the situation and proposes the optimal action to maximize the expected goal for the team. We performed extensive numerical experiments on the soccer logs made by InStat for 104 European soccer matches. The results show that in all 104 games, the optimized policy obtains higher rewards than its counterpart in the behavior policy. Besides, our framework learns policies that are close to the expected behavior in the real world. For instance, in the optimized policy, we observe that some actions such as foul, or ball out can be sometimes more rewarding than a shot in specific situations.
AttendLight: Universal Attention-Based Reinforcement Learning Model for Traffic Signal Control
Oct 12, 2020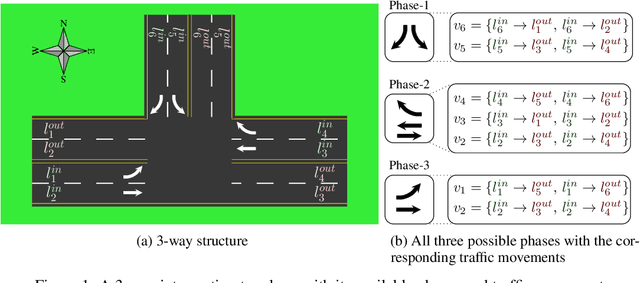

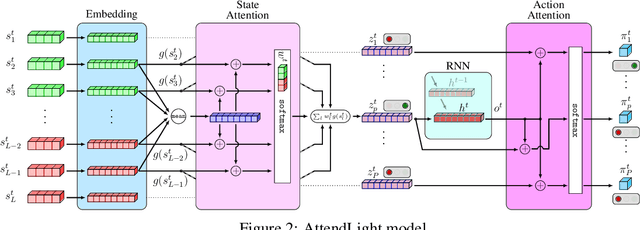
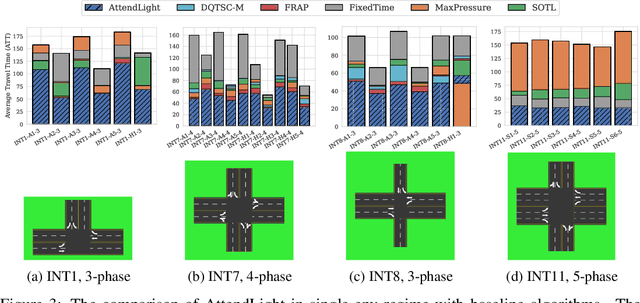
We propose AttendLight, an end-to-end Reinforcement Learning (RL) algorithm for the problem of traffic signal control. Previous approaches for this problem have the shortcoming that they require training for each new intersection with a different structure or traffic flow distribution. AttendLight solves this issue by training a single, universal model for intersections with any number of roads, lanes, phases (possible signals), and traffic flow. To this end, we propose a deep RL model which incorporates two attention models. The first attention model is introduced to handle different numbers of roads-lanes; and the second attention model is intended for enabling decision-making with any number of phases in an intersection. As a result, our proposed model works for any intersection configuration, as long as a similar configuration is represented in the training set. Experiments were conducted with both synthetic and real-world standard benchmark data-sets. The results we show cover intersections with three or four approaching roads; one-directional/bi-directional roads with one, two, and three lanes; different number of phases; and different traffic flows. We consider two regimes: (i) single-environment training, single-deployment, and (ii) multi-environment training, multi-deployment. AttendLight outperforms both classical and other RL-based approaches on all cases in both regimes.
Reinforcement Learning for Solving the Vehicle Routing Problem
May 21, 2018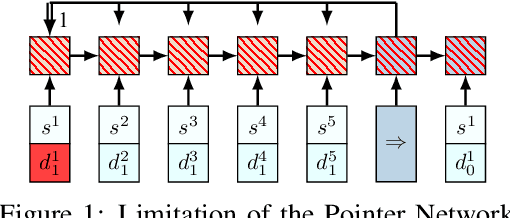
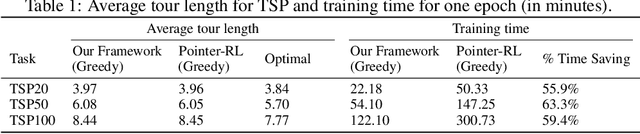
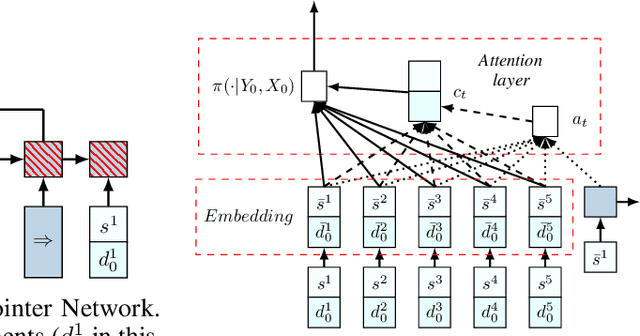
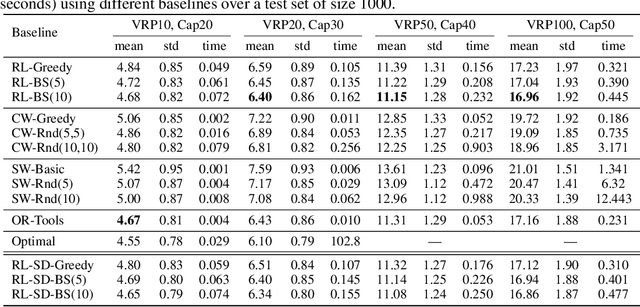
We present an end-to-end framework for solving the Vehicle Routing Problem (VRP) using reinforcement learning. In this approach, we train a single model that finds near-optimal solutions for problem instances sampled from a given distribution, only by observing the reward signals and following feasibility rules. Our model represents a parameterized stochastic policy, and by applying a policy gradient algorithm to optimize its parameters, the trained model produces the solution as a sequence of consecutive actions in real time, without the need to re-train for every new problem instance. On capacitated VRP, our approach outperforms classical heuristics and Google's OR-Tools on medium-sized instances in solution quality with comparable computation time (after training). We demonstrate how our approach can handle problems with split delivery and explore the effect of such deliveries on the solution quality. Our proposed framework can be applied to other variants of the VRP such as the stochastic VRP, and has the potential to be applied more generally to combinatorial optimization problems.