 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards optimized actions in critical situations of soccer games with deep reinforcement learning
Paper and Code
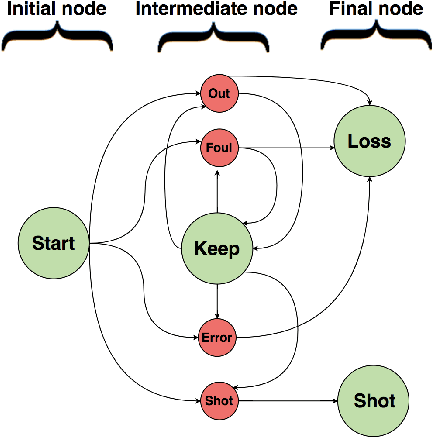
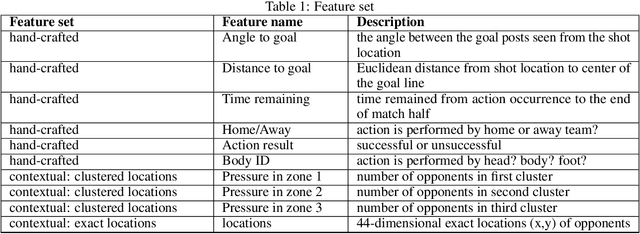
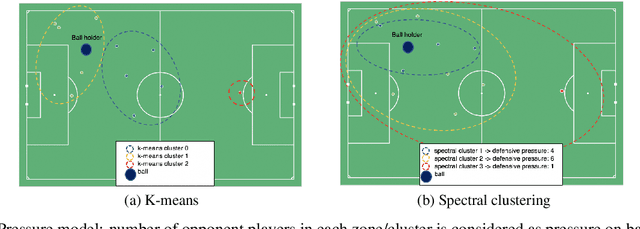
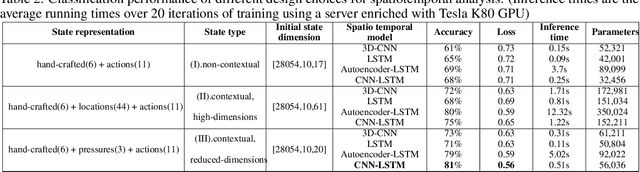
Soccer is a sparse rewarding game: any smart or careless action in critical situations can change the result of the match. Therefore players, coaches, and scouts are all curious about the best action to be performed in critical situations, such as the times with a high probability of losing ball possession or scoring a goal. This work proposes a new state representation for the soccer game and a batch reinforcement learning to train a smart policy network. This network gets the contextual information of the situation and proposes the optimal action to maximize the expected goal for the team. We performed extensive numerical experiments on the soccer logs made by InStat for 104 European soccer matches. The results show that in all 104 games, the optimized policy obtains higher rewards than its counterpart in the behavior policy. Besides, our framework learns policies that are close to the expected behavior in the real world. For instance, in the optimized policy, we observe that some actions such as foul, or ball out can be sometimes more rewarding than a shot in specific situations.