 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIDST Challenge at SaTML 2025: Membership Inference over Diffusion-models-based Synthetic Tabular data
Mar 19, 2026Synthetic data is often perceived as a silver-bullet solution to data anonymization and privacy-preserving data publishing. Drawn from generative models like diffusion models, synthetic data is expected to preserve the statistical properties of the original dataset while remaining resilient to privacy attacks. Recent developments of diffusion models have been effective on a wide range of data types, but their privacy resilience, particularly for tabular formats, remains largely unexplored. MIDST challenge sought a quantitative evaluation of the privacy gain of synthetic tabular data generated by diffusion models, with a specific focus on its resistance to membership inference attacks (MIAs). Given the heterogeneity and complexity of tabular data, multiple target models were explored for MIAs, including diffusion models for single tables of mixed data types and multi-relational tables with interconnected constraints. MIDST inspired the development of novel black-box and white-box MIAs tailored to these target diffusion models as a key outcome, enabling a comprehensive evaluation of their privacy efficacy. The MIDST GitHub repository is available at https://github.com/VectorInstitute/MIDST
CAPID: Context-Aware PII Detection for Question-Answering Systems
Feb 10, 2026Detecting personally identifiable information (PII) in user queries is critical for ensuring privacy in question-answering systems. Current approaches mainly redact all PII, disregarding the fact that some of them may be contextually relevant to the user's question, resulting in a degradation of response quality. Large language models (LLMs) might be able to help determine which PII are relevant, but due to their closed source nature and lack of privacy guarantees, they are unsuitable for sensitive data processing. To achieve privacy-preserving PII detection, we propose CAPID, a practical approach that fine-tunes a locally owned small language model (SLM) that filters sensitive information before it is passed to LLMs for QA. However, existing datasets do not capture the context-dependent relevance of PII needed to train such a model effectively. To fill this gap, we propose a synthetic data generation pipeline that leverages LLMs to produce a diverse, domain-rich dataset spanning multiple PII types and relevance levels. Using this dataset, we fine-tune an SLM to detect PII spans, classify their types, and estimate contextual relevance. Our experiments show that relevance-aware PII detection with a fine-tuned SLM substantially outperforms existing baselines in span, relevance and type accuracy while preserving significantly higher downstream utility under anonymization.
Co-Designing Quantum Codes with Transversal Diagonal Gates via Multi-Agent Systems
Oct 23, 2025

We present a multi-agent, human-in-the-loop workflow that co-designs quantum codes with prescribed transversal diagonal gates. It builds on the Subset-Sum Linear Programming (SSLP) framework (arXiv:2504.20847), which partitions basis strings by modular residues and enforces $Z$-marginal Knill-Laflamme (KL) equalities via small LPs. The workflow is powered by GPT-5 and implemented within TeXRA (https://texra.ai)-a multi-agent research assistant platform that supports an iterative tool-use loop agent and a derivation-then-edit workflow reasoning agent. We work in a LaTeX-Python environment where agents reason, edit documents, execute code, and synchronize their work to Git/Overleaf. Within this workspace, three roles collaborate: a Synthesis Agent formulates the problem; a Search Agent sweeps/screens candidates and exactifies numerics into rationals; and an Audit Agent independently checks all KL equalities and the induced logical action. As a first step we focus on distance $d=2$ with nondegenerate residues. For code dimension $K\in\{2,3,4\}$ and $n\le6$ qubits, systematic sweeps yield certificate-backed tables cataloging attainable cyclic logical groups-all realized by new codes-e.g., for $K=3$ we obtain order $16$ at $n=6$. From verified instances, Synthesis Agent abstracts recurring structures into closed-form families and proves they satisfy the KL equalities for all parameters. It further demonstrates that SSLP accommodates residue degeneracy by exhibiting a new $((6,4,2))$ code implementing the transversal controlled-phase $diag(1,1,1,i)$. Overall, the workflow recasts diagonal-transversal feasibility as an analytical pipeline executed at scale, combining systematic enumeration with exact analytical reconstruction. It yields reproducible code constructions, supports targeted extensions to larger $K$ and higher distances, and leads toward data-driven classification.
Paper2Poster: Towards Multimodal Poster Automation from Scientific Papers
May 27, 2025Academic poster generation is a crucial yet challenging task in scientific communication, requiring the compression of long-context interleaved documents into a single, visually coherent page. To address this challenge, we introduce the first benchmark and metric suite for poster generation, which pairs recent conference papers with author-designed posters and evaluates outputs on (i)Visual Quality-semantic alignment with human posters, (ii)Textual Coherence-language fluency, (iii)Holistic Assessment-six fine-grained aesthetic and informational criteria scored by a VLM-as-judge, and notably (iv)PaperQuiz-the poster's ability to convey core paper content as measured by VLMs answering generated quizzes. Building on this benchmark, we propose PosterAgent, a top-down, visual-in-the-loop multi-agent pipeline: the (a)Parser distills the paper into a structured asset library; the (b)Planner aligns text-visual pairs into a binary-tree layout that preserves reading order and spatial balance; and the (c)Painter-Commenter loop refines each panel by executing rendering code and using VLM feedback to eliminate overflow and ensure alignment. In our comprehensive evaluation, we find that GPT-4o outputs-though visually appealing at first glance-often exhibit noisy text and poor PaperQuiz scores, and we find that reader engagement is the primary aesthetic bottleneck, as human-designed posters rely largely on visual semantics to convey meaning. Our fully open-source variants (e.g. based on the Qwen-2.5 series) outperform existing 4o-driven multi-agent systems across nearly all metrics, while using 87% fewer tokens. It transforms a 22-page paper into a finalized yet editable .pptx poster - all for just $0.005. These findings chart clear directions for the next generation of fully automated poster-generation models. The code and datasets are available at https://github.com/Paper2Poster/Paper2Poster.
Deep-ICE: The first globally optimal algorithm for empirical risk minimization of two-layer maxout and ReLU networks
May 09, 2025This paper introduces the first globally optimal algorithm for the empirical risk minimization problem of two-layer maxout and ReLU networks, i.e., minimizing the number of misclassifications. The algorithm has a worst-case time complexity of $O\left(N^{DK+1}\right)$, where $K$ denotes the number of hidden neurons and $D$ represents the number of features. It can be can be generalized to accommodate arbitrary computable loss functions without affecting its computational complexity. Our experiments demonstrate that the proposed algorithm provides provably exact solutions for small-scale datasets. To handle larger datasets, we introduce a novel coreset selection method that reduces the data size to a manageable scale, making it feasible for our algorithm. This extension enables efficient processing of large-scale datasets and achieves significantly improved performance, with a 20-30\% reduction in misclassifications for both training and prediction, compared to state-of-the-art approaches (neural networks trained using gradient descent and support vector machines), when applied to the same models (two-layer networks with fixed hidden nodes and linear models).
Provably optimal decision trees with arbitrary splitting rules in polynomial time
Mar 03, 2025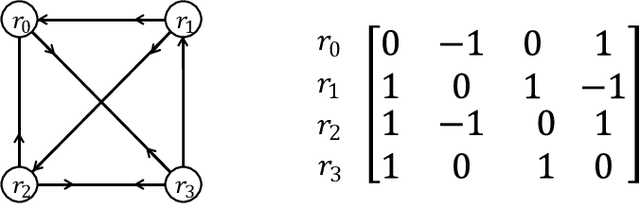
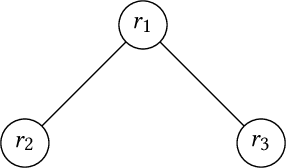
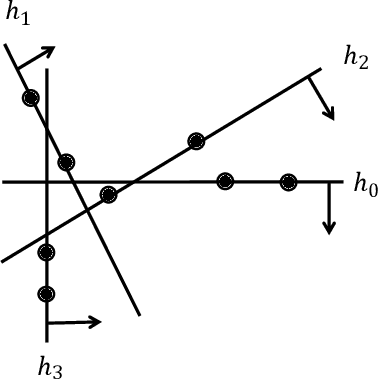
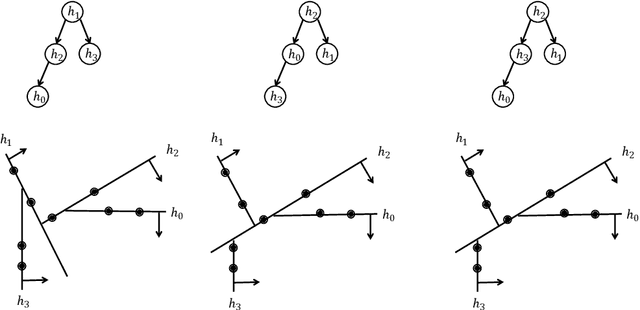
In this paper, we introduce a generic data structure called decision trees, which integrates several well-known data structures, including binary search trees, K-D trees, binary space partition trees, and decision tree models from machine learning. We provide the first axiomatic definition of decision trees. These axioms establish a firm mathematical foundation for studying decision tree problems. We refer to decision trees that satisfy the axioms as proper decision trees. We prove that only proper decision trees can be uniquely characterized as K-permutations. Since permutations are among the most well-studied combinatorial structures, this characterization provides a fundamental basis for analyzing the combinatorial and algorithmic properties of decision trees. As a result of this advancement, we develop the first provably correct polynomial-time algorithm for solving the optimal decision tree problem. Our algorithm is derived using a formal program derivation framework, which enables step-by-step equational reasoning to construct side-effect-free programs with guaranteed correctness. The derived algorithm is correct by construction and is applicable to decision tree problems defined by any splitting rules that adhere to the axioms and any objective functions that can be specified in a given form. Examples include the decision tree problems where splitting rules are defined by axis-parallel hyperplanes, arbitrary hyperplanes, and hypersurfaces. By extending the axioms, we can potentially address a broader range of problems. Moreover, the derived algorithm can easily accommodate various constraints, such as tree depth and leaf size, and is amenable to acceleration techniques such as thinning method.
Distribution alignment based transfer fusion frameworks on quantum devices for seeking quantum advantages
Nov 04, 2024



The scarcity of labelled data is specifically an urgent challenge in the field of quantum machine learning (QML). Two transfer fusion frameworks are proposed in this paper to predict the labels of a target domain data by aligning its distribution to a different but related labelled source domain on quantum devices. The frameworks fuses the quantum data from two different, but related domains through a quantum information infusion channel. The predicting tasks in the target domain can be achieved with quantum advantages by post-processing quantum measurement results. One framework, the quantum basic linear algebra subroutines (QBLAS) based implementation, can theoretically achieve the procedure of transfer fusion with quadratic speedup on a universal quantum computer. In addition, the other framework, a hardware-scalable architecture, is implemented on the noisy intermediate-scale quantum (NISQ) devices through a variational hybrid quantum-classical procedure. Numerical experiments on the synthetic and handwritten digits datasets demonstrate that the variatioinal transfer fusion (TF) framework can reach state-of-the-art (SOTA) quantum DA method performance.
ClavaDDPM: Multi-relational Data Synthesis with Cluster-guided Diffusion Models
May 28, 2024



Recent research in tabular data synthesis has focused on single tables, whereas real-world applications often involve complex data with tens or hundreds of interconnected tables. Previous approaches to synthesizing multi-relational (multi-table) data fall short in two key aspects: scalability for larger datasets and capturing long-range dependencies, such as correlations between attributes spread across different tables. Inspired by the success of diffusion models in tabular data modeling, we introduce $\textbf{C}luster$ $\textbf{La}tent$ $\textbf{Va}riable$ $guided$ $\textbf{D}enoising$ $\textbf{D}iffusion$ $\textbf{P}robabilistic$ $\textbf{M}odels$ (ClavaDDPM). This novel approach leverages clustering labels as intermediaries to model relationships between tables, specifically focusing on foreign key constraints. ClavaDDPM leverages the robust generation capabilities of diffusion models while incorporating efficient algorithms to propagate the learned latent variables across tables. This enables ClavaDDPM to capture long-range dependencies effectively. Extensive evaluations on multi-table datasets of varying sizes show that ClavaDDPM significantly outperforms existing methods for these long-range dependencies while remaining competitive on utility metrics for single-table data.
EKM: An exact, polynomial-time algorithm for the $K$-medoids problem
May 16, 2024
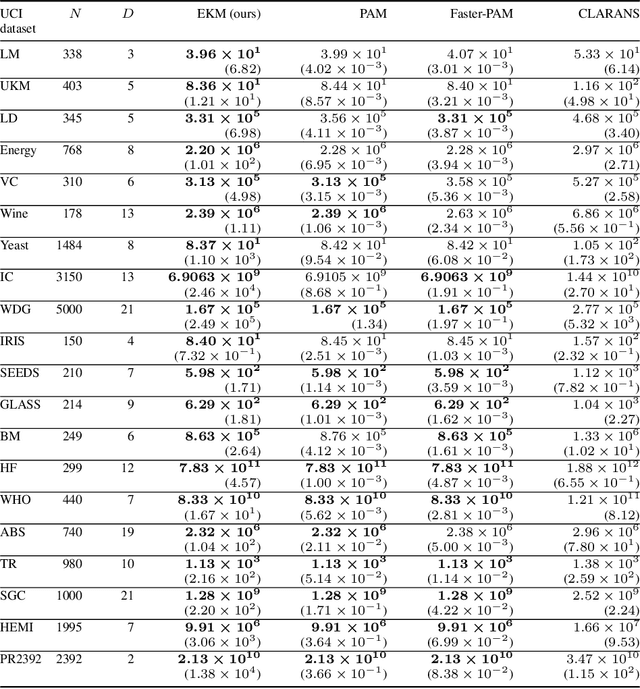
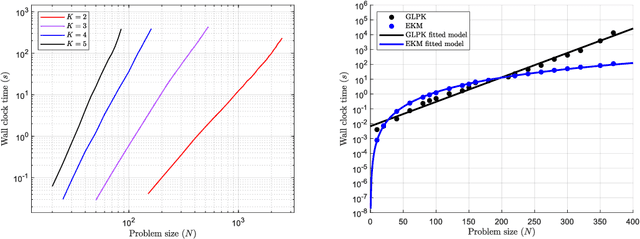
The $K$-medoids problem is a challenging combinatorial clustering task, widely used in data analysis applications. While numerous algorithms have been proposed to solve this problem, none of these are able to obtain an exact (globally optimal) solution for the problem in polynomial time. In this paper, we present EKM: a novel algorithm for solving this problem exactly with worst-case $O\left(N^{K+1}\right)$ time complexity. EKM is developed according to recent advances in transformational programming and combinatorial generation, using formal program derivation steps. The derived algorithm is provably correct by construction. We demonstrate the effectiveness of our algorithm by comparing it against various approximate methods on numerous real-world datasets. We show that the wall-clock run time of our algorithm matches the worst-case time complexity analysis on synthetic datasets, clearly outperforming the exponential time complexity of benchmark branch-and-bound based MIP solvers. To our knowledge, this is the first, rigorously-proven polynomial time, practical algorithm for this ubiquitous problem.
An efficient, provably exact algorithm for the 0-1 loss linear classification problem
Jun 21, 2023



Algorithms for solving the linear classification problem have a long history, dating back at least to 1936 with linear discriminant analysis. For linearly separable data, many algorithms can obtain the exact solution to the corresponding 0-1 loss classification problem efficiently, but for data which is not linearly separable, it has been shown that this problem, in full generality, is NP-hard. Alternative approaches all involve approximations of some kind, including the use of surrogates for the 0-1 loss (for example, the hinge or logistic loss) or approximate combinatorial search, none of which can be guaranteed to solve the problem exactly. Finding efficient algorithms to obtain an exact i.e. globally optimal solution for the 0-1 loss linear classification problem with fixed dimension, remains an open problem. In research we report here, we detail the construction of a new algorithm, incremental cell enumeration (ICE), that can solve the 0-1 loss classification problem exactly in polynomial time. To our knowledge, this is the first, rigorously-proven polynomial time algorithm for this long-standing problem.