 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClavaDDPM: Multi-relational Data Synthesis with Cluster-guided Diffusion Models
May 28, 2024



Recent research in tabular data synthesis has focused on single tables, whereas real-world applications often involve complex data with tens or hundreds of interconnected tables. Previous approaches to synthesizing multi-relational (multi-table) data fall short in two key aspects: scalability for larger datasets and capturing long-range dependencies, such as correlations between attributes spread across different tables. Inspired by the success of diffusion models in tabular data modeling, we introduce $\textbf{C}luster$ $\textbf{La}tent$ $\textbf{Va}riable$ $guided$ $\textbf{D}enoising$ $\textbf{D}iffusion$ $\textbf{P}robabilistic$ $\textbf{M}odels$ (ClavaDDPM). This novel approach leverages clustering labels as intermediaries to model relationships between tables, specifically focusing on foreign key constraints. ClavaDDPM leverages the robust generation capabilities of diffusion models while incorporating efficient algorithms to propagate the learned latent variables across tables. This enables ClavaDDPM to capture long-range dependencies effectively. Extensive evaluations on multi-table datasets of varying sizes show that ClavaDDPM significantly outperforms existing methods for these long-range dependencies while remaining competitive on utility metrics for single-table data.
CLASS Meet SPOCK: An Education Tutoring Chatbot based on Learning Science Principles
May 22, 2023


We present a design framework called Conversational Learning with Analytical Step-by-Step Strategies (CLASS) for developing high-performance Intelligent Tutoring Systems (ITS). The CLASS framework aims to empower ITS with with two critical capabilities: imparting tutor-like step-by-step guidance and enabling tutor-like conversations in natural language to effectively engage learners. To empower ITS with the aforementioned capabilities, the CLASS framework employs two carefully curated synthetic datasets. The first scaffolding dataset encompasses a variety of elements, including problems, their corresponding subproblems, hints, incorrect solutions, and tailored feedback. This dataset provides ITS with essential problem-solving strategies necessary for guiding students through each step of the conversation. The second conversational dataset contains simulated student-tutor conversations that involve the application of problem-solving strategies learned from the first dataset. In the second dataset, the tutoring system adheres to a pre-defined response template, which helps to maintain consistency and structure in ITS's responses during its interactions. This structured methodology facilitates seamless integration of user feedback and yields valuable insights into ITS's internal decision-making process, allowing for continuous refinement and improvement of the system. We also present a proof-of-concept ITS, referred to as SPOCK, trained using the CLASS framework with a focus on college level introductory biology content. A carefully constructed protocol was developed for SPOCK's preliminary evaluation, examining aspects such as the factual accuracy and relevance of its responses. Experts in the field of biology offered favorable remarks, particularly highlighting SPOCK's capability to break down questions into manageable subproblems and provide step-by-step guidance to students.
Explainable Reinforcement Learning via Model Transforms
Sep 24, 2022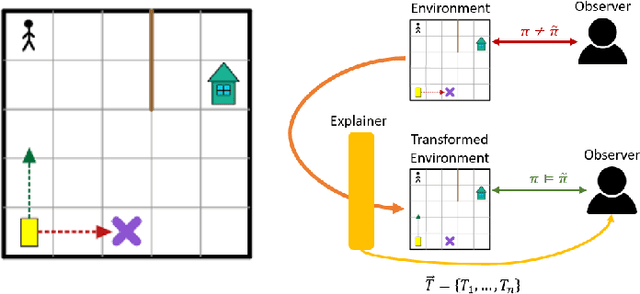
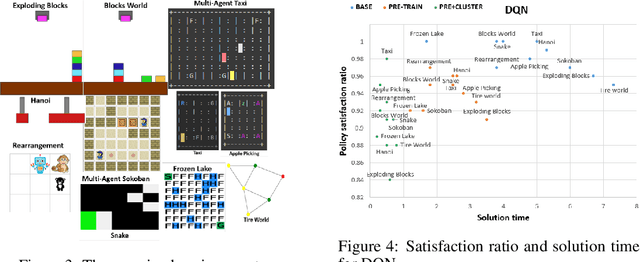
Understanding emerging behaviors of reinforcement learning (RL) agents may be difficult since such agents are often trained in complex environments using highly complex decision making procedures. This has given rise to a variety of approaches to explainability in RL that aim to reconcile discrepancies that may arise between the behavior of an agent and the behavior that is anticipated by an observer. Most recent approaches have relied either on domain knowledge, that may not always be available, on an analysis of the agent's policy, or on an analysis of specific elements of the underlying environment, typically modeled as a Markov Decision Process (MDP). Our key claim is that even if the underlying MDP is not fully known (e.g., the transition probabilities have not been accurately learned) or is not maintained by the agent (i.e., when using model-free methods), it can nevertheless be exploited to automatically generate explanations. For this purpose, we suggest using formal MDP abstractions and transforms, previously used in the literature for expediting the search for optimal policies, to automatically produce explanations. Since such transforms are typically based on a symbolic representation of the environment, they may represent meaningful explanations for gaps between the anticipated and actual agent behavior. We formally define this problem, suggest a class of transforms that can be used for explaining emergent behaviors, and suggest methods that enable efficient search for an explanation. We demonstrate the approach on a set of standard benchmarks.