 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFERMI: Exploiting Relations for Membership Inference Against Tabular Diffusion Models
May 12, 2026Diffusion models are the leading approach for tabular data synthesis and are increasingly used to share sensitive records. Whether they actually protect privacy has become a pressing question. Membership inference attacks are the standard tool for this purpose, yet existing attacks assume a single-table setting and ignore the multi-relational structure of real sensitive data. A core challenge in assessing privacy risks from membership inference attacks in multi-table settings is how to leverage auxiliary information from relations associated with the target table, such as its parent tables. Particularly, we study a practical setting in which such auxiliary information is available only when training the attack model. At inference time, the attacker observes only the attribute values of the target record from the target table. We propose FERMI (FEature-mapping for Relational Membership Inference), which resolves this gap by enriching single-table features with relational membership signal. Across three tabular diffusion architectures and three real-world relational datasets, FERMI consistently improves attack performance over single-table baselines, with TPR@$0.1$FPR rising by up to 53% over the single-table baseline in the white-box setting and 22% in the black-box setting.
MIDST Challenge at SaTML 2025: Membership Inference over Diffusion-models-based Synthetic Tabular data
Mar 19, 2026Synthetic data is often perceived as a silver-bullet solution to data anonymization and privacy-preserving data publishing. Drawn from generative models like diffusion models, synthetic data is expected to preserve the statistical properties of the original dataset while remaining resilient to privacy attacks. Recent developments of diffusion models have been effective on a wide range of data types, but their privacy resilience, particularly for tabular formats, remains largely unexplored. MIDST challenge sought a quantitative evaluation of the privacy gain of synthetic tabular data generated by diffusion models, with a specific focus on its resistance to membership inference attacks (MIAs). Given the heterogeneity and complexity of tabular data, multiple target models were explored for MIAs, including diffusion models for single tables of mixed data types and multi-relational tables with interconnected constraints. MIDST inspired the development of novel black-box and white-box MIAs tailored to these target diffusion models as a key outcome, enabling a comprehensive evaluation of their privacy efficacy. The MIDST GitHub repository is available at https://github.com/VectorInstitute/MIDST
CAPID: Context-Aware PII Detection for Question-Answering Systems
Feb 10, 2026Detecting personally identifiable information (PII) in user queries is critical for ensuring privacy in question-answering systems. Current approaches mainly redact all PII, disregarding the fact that some of them may be contextually relevant to the user's question, resulting in a degradation of response quality. Large language models (LLMs) might be able to help determine which PII are relevant, but due to their closed source nature and lack of privacy guarantees, they are unsuitable for sensitive data processing. To achieve privacy-preserving PII detection, we propose CAPID, a practical approach that fine-tunes a locally owned small language model (SLM) that filters sensitive information before it is passed to LLMs for QA. However, existing datasets do not capture the context-dependent relevance of PII needed to train such a model effectively. To fill this gap, we propose a synthetic data generation pipeline that leverages LLMs to produce a diverse, domain-rich dataset spanning multiple PII types and relevance levels. Using this dataset, we fine-tune an SLM to detect PII spans, classify their types, and estimate contextual relevance. Our experiments show that relevance-aware PII detection with a fine-tuned SLM substantially outperforms existing baselines in span, relevance and type accuracy while preserving significantly higher downstream utility under anonymization.
ClavaDDPM: Multi-relational Data Synthesis with Cluster-guided Diffusion Models
May 28, 2024



Recent research in tabular data synthesis has focused on single tables, whereas real-world applications often involve complex data with tens or hundreds of interconnected tables. Previous approaches to synthesizing multi-relational (multi-table) data fall short in two key aspects: scalability for larger datasets and capturing long-range dependencies, such as correlations between attributes spread across different tables. Inspired by the success of diffusion models in tabular data modeling, we introduce $\textbf{C}luster$ $\textbf{La}tent$ $\textbf{Va}riable$ $guided$ $\textbf{D}enoising$ $\textbf{D}iffusion$ $\textbf{P}robabilistic$ $\textbf{M}odels$ (ClavaDDPM). This novel approach leverages clustering labels as intermediaries to model relationships between tables, specifically focusing on foreign key constraints. ClavaDDPM leverages the robust generation capabilities of diffusion models while incorporating efficient algorithms to propagate the learned latent variables across tables. This enables ClavaDDPM to capture long-range dependencies effectively. Extensive evaluations on multi-table datasets of varying sizes show that ClavaDDPM significantly outperforms existing methods for these long-range dependencies while remaining competitive on utility metrics for single-table data.
On Privacy and Confidentiality of Communications in Organizational Graphs
May 27, 2021
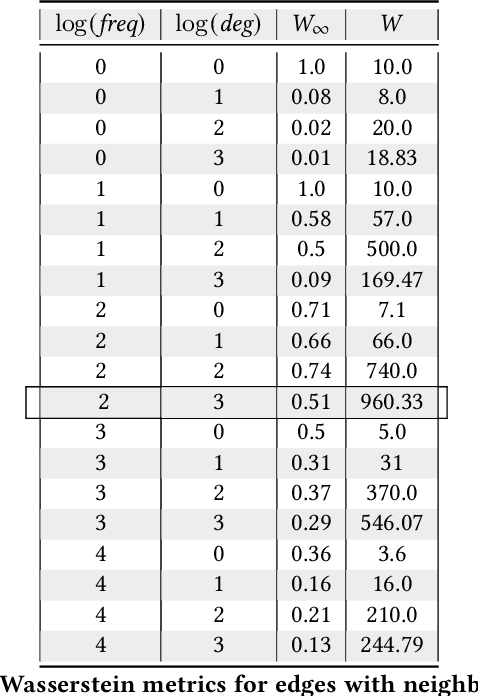
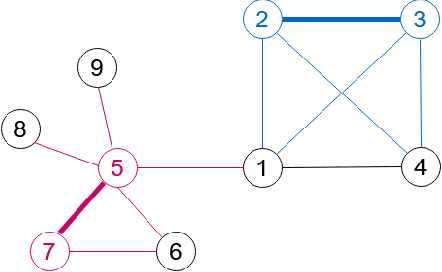
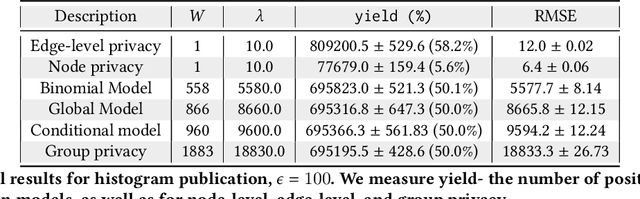
Machine learned models trained on organizational communication data, such as emails in an enterprise, carry unique risks of breaching confidentiality, even if the model is intended only for internal use. This work shows how confidentiality is distinct from privacy in an enterprise context, and aims to formulate an approach to preserving confidentiality while leveraging principles from differential privacy. The goal is to perform machine learning tasks, such as learning a language model or performing topic analysis, using interpersonal communications in the organization, while not learning about confidential information shared in the organization. Works that apply differential privacy techniques to natural language processing tasks usually assume independently distributed data, and overlook potential correlation among the records. Ignoring this correlation results in a fictional promise of privacy. Naively extending differential privacy techniques to focus on group privacy instead of record-level privacy is a straightforward approach to mitigate this issue. This approach, although providing a more realistic privacy-guarantee, is over-cautious and severely impacts model utility. We show this gap between these two extreme measures of privacy over two language tasks, and introduce a middle-ground solution. We propose a model that captures the correlation in the social network graph, and incorporates this correlation in the privacy calculations through Pufferfish privacy principles.
On the Robustness of the Backdoor-based Watermarking in Deep Neural Networks
Jun 18, 2019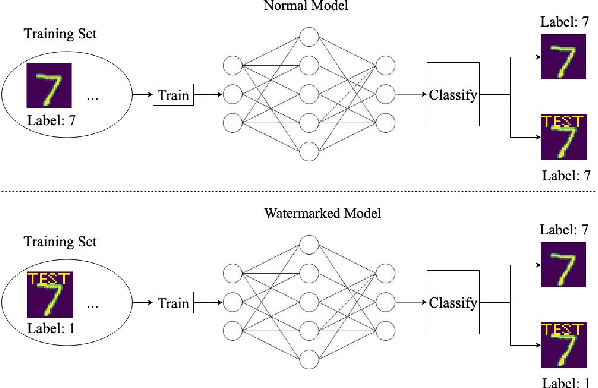
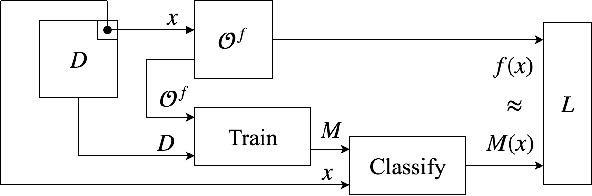
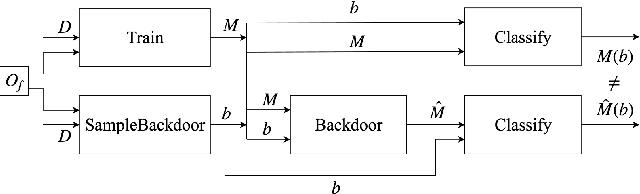
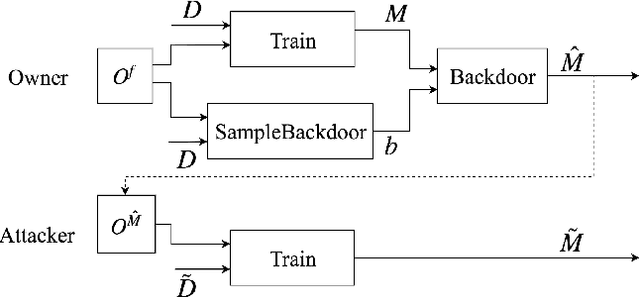
Obtaining the state of the art performance of deep learning models imposes a high cost to model generators, due to the tedious data preparation and the substantial processing requirements. To protect the model from unauthorized re-distribution, watermarking approaches have been introduced in the past couple of years. The watermark allows the legitimate owner to detect copyright violations of their model. We investigate the robustness and reliability of state-of-the-art deep neural network watermarking schemes. We focus on backdoor-based watermarking and show that an adversary can remove the watermark fully by just relying on public data and without any access to the model's sensitive information such as the training data set, the trigger set or the model parameters. We as well prove the security inadequacy of the backdoor-based watermarking in keeping the watermark hidden by proposing an attack that detects whether a model contains a watermark.