 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness of the Backdoor-based Watermarking in Deep Neural Networks
Paper and Code
Jun 18, 2019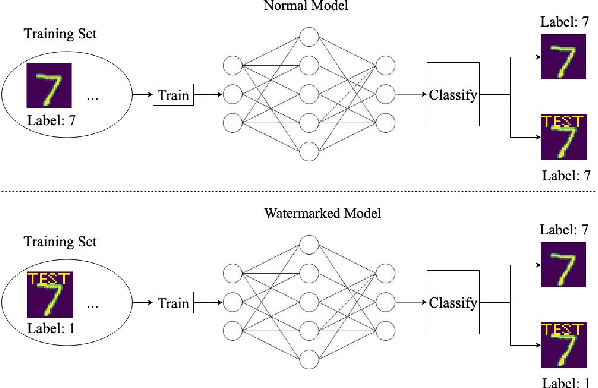
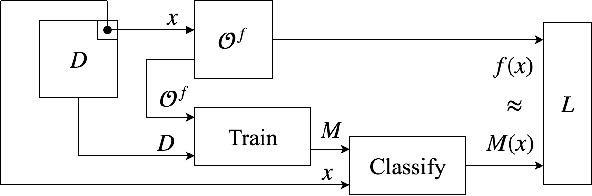
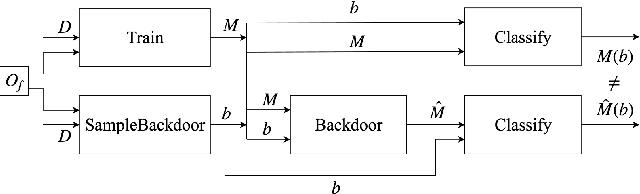
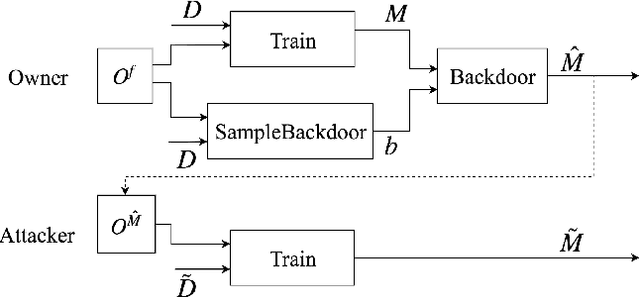
Obtaining the state of the art performance of deep learning models imposes a high cost to model generators, due to the tedious data preparation and the substantial processing requirements. To protect the model from unauthorized re-distribution, watermarking approaches have been introduced in the past couple of years. The watermark allows the legitimate owner to detect copyright violations of their model. We investigate the robustness and reliability of state-of-the-art deep neural network watermarking schemes. We focus on backdoor-based watermarking and show that an adversary can remove the watermark fully by just relying on public data and without any access to the model's sensitive information such as the training data set, the trigger set or the model parameters. We as well prove the security inadequacy of the backdoor-based watermarking in keeping the watermark hidden by proposing an attack that detects whether a model contains a watermark.