 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Synthetic Clinical Note Generation with Privacy Guarantees
Sep 12, 2024



In the field of machine learning, domain-specific annotated data is an invaluable resource for training effective models. However, in the medical domain, this data often includes Personal Health Information (PHI), raising significant privacy concerns. The stringent regulations surrounding PHI limit the availability and sharing of medical datasets, which poses a substantial challenge for researchers and practitioners aiming to develop advanced machine learning models. In this paper, we introduce a novel method to "clone" datasets containing PHI. Our approach ensures that the cloned datasets retain the essential characteristics and utility of the original data without compromising patient privacy. By leveraging differential-privacy techniques and a novel fine-tuning task, our method produces datasets that are free from identifiable information while preserving the statistical properties necessary for model training. We conduct utility testing to evaluate the performance of machine learning models trained on the cloned datasets. The results demonstrate that our cloned datasets not only uphold privacy standards but also enhance model performance compared to those trained on traditional anonymized datasets. This work offers a viable solution for the ethical and effective utilization of sensitive medical data in machine learning, facilitating progress in medical research and the development of robust predictive models.
Active Data Pattern Extraction Attacks on Generative Language Models
Jul 14, 2022
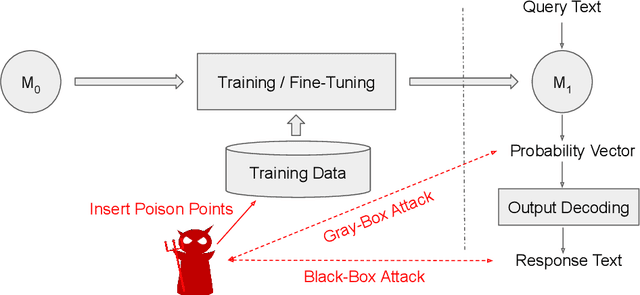

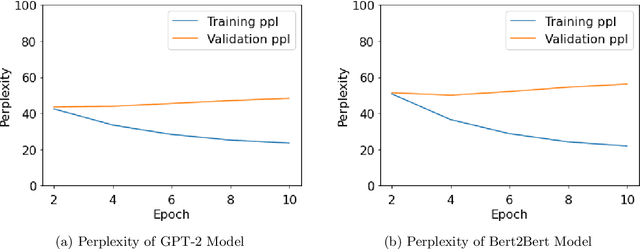
With the wide availability of large pre-trained language model checkpoints, such as GPT-2 and BERT, the recent trend has been to fine-tune them on a downstream task to achieve the state-of-the-art performance with a small computation overhead. One natural example is the Smart Reply application where a pre-trained model is fine-tuned for suggesting a number of responses given a query message. In this work, we set out to investigate potential information leakage vulnerabilities in a typical Smart Reply pipeline and show that it is possible for an adversary, having black-box or gray-box access to a Smart Reply model, to extract sensitive user information present in the training data. We further analyse the privacy impact of specific components, e.g. the decoding strategy, pertained to this application through our attack settings. We explore potential mitigation strategies and demonstrate how differential privacy can be a strong defense mechanism to such data extraction attacks.
On Privacy and Confidentiality of Communications in Organizational Graphs
May 27, 2021
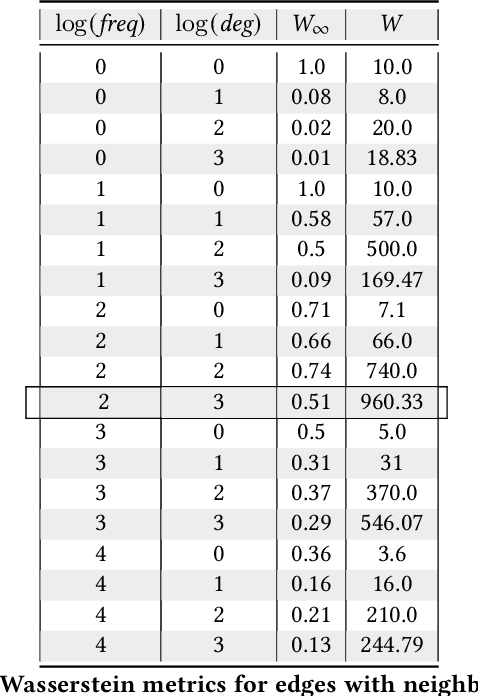
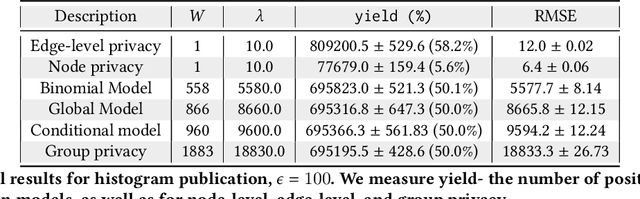
Machine learned models trained on organizational communication data, such as emails in an enterprise, carry unique risks of breaching confidentiality, even if the model is intended only for internal use. This work shows how confidentiality is distinct from privacy in an enterprise context, and aims to formulate an approach to preserving confidentiality while leveraging principles from differential privacy. The goal is to perform machine learning tasks, such as learning a language model or performing topic analysis, using interpersonal communications in the organization, while not learning about confidential information shared in the organization. Works that apply differential privacy techniques to natural language processing tasks usually assume independently distributed data, and overlook potential correlation among the records. Ignoring this correlation results in a fictional promise of privacy. Naively extending differential privacy techniques to focus on group privacy instead of record-level privacy is a straightforward approach to mitigate this issue. This approach, although providing a more realistic privacy-guarantee, is over-cautious and severely impacts model utility. We show this gap between these two extreme measures of privacy over two language tasks, and introduce a middle-ground solution. We propose a model that captures the correlation in the social network graph, and incorporates this correlation in the privacy calculations through Pufferfish privacy principles.