 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.
Active Data Pattern Extraction Attacks on Generative Language Models
Jul 14, 2022
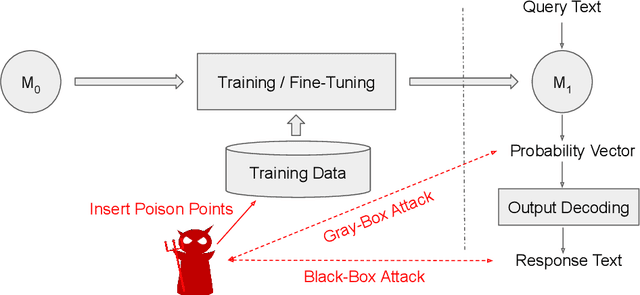

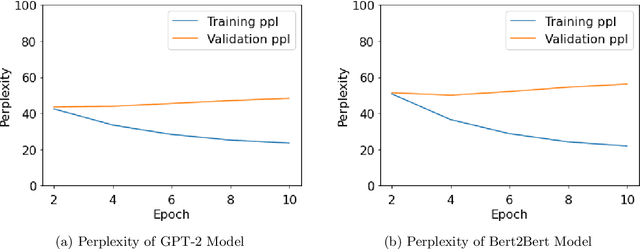
With the wide availability of large pre-trained language model checkpoints, such as GPT-2 and BERT, the recent trend has been to fine-tune them on a downstream task to achieve the state-of-the-art performance with a small computation overhead. One natural example is the Smart Reply application where a pre-trained model is fine-tuned for suggesting a number of responses given a query message. In this work, we set out to investigate potential information leakage vulnerabilities in a typical Smart Reply pipeline and show that it is possible for an adversary, having black-box or gray-box access to a Smart Reply model, to extract sensitive user information present in the training data. We further analyse the privacy impact of specific components, e.g. the decoding strategy, pertained to this application through our attack settings. We explore potential mitigation strategies and demonstrate how differential privacy can be a strong defense mechanism to such data extraction attacks.
Fenchel Duals for Drifting Adversaries
Sep 23, 2013We describe a primal-dual framework for the design and analysis of online convex optimization algorithms for {\em drifting regret}. Existing literature shows (nearly) optimal drifting regret bounds only for the $\ell_2$ and the $\ell_1$-norms. Our work provides a connection between these algorithms and the Online Mirror Descent ($\omd$) updates; one key insight that results from our work is that in order for these algorithms to succeed, it suffices to have the gradient of the regularizer to be bounded (in an appropriate norm). For situations (like for the $\ell_1$ norm) where the vanilla regularizer does not have this property, we have to {\em shift} the regularizer to ensure this. Thus, this helps explain the various updates presented in \cite{bansal10, buchbinder12}. We also consider the online variant of the problem with 1-lookahead, and with movement costs in the $\ell_2$-norm. Our primal dual approach yields nearly optimal competitive ratios for this problem.