 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Data Pattern Extraction Attacks on Generative Language Models
Paper and Code
Jul 14, 2022
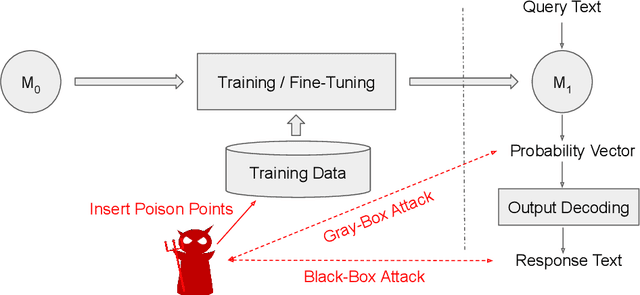

With the wide availability of large pre-trained language model checkpoints, such as GPT-2 and BERT, the recent trend has been to fine-tune them on a downstream task to achieve the state-of-the-art performance with a small computation overhead. One natural example is the Smart Reply application where a pre-trained model is fine-tuned for suggesting a number of responses given a query message. In this work, we set out to investigate potential information leakage vulnerabilities in a typical Smart Reply pipeline and show that it is possible for an adversary, having black-box or gray-box access to a Smart Reply model, to extract sensitive user information present in the training data. We further analyse the privacy impact of specific components, e.g. the decoding strategy, pertained to this application through our attack settings. We explore potential mitigation strategies and demonstrate how differential privacy can be a strong defense mechanism to such data extraction attacks.