 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Synthetic Clinical Note Generation with Privacy Guarantees
Sep 12, 2024



In the field of machine learning, domain-specific annotated data is an invaluable resource for training effective models. However, in the medical domain, this data often includes Personal Health Information (PHI), raising significant privacy concerns. The stringent regulations surrounding PHI limit the availability and sharing of medical datasets, which poses a substantial challenge for researchers and practitioners aiming to develop advanced machine learning models. In this paper, we introduce a novel method to "clone" datasets containing PHI. Our approach ensures that the cloned datasets retain the essential characteristics and utility of the original data without compromising patient privacy. By leveraging differential-privacy techniques and a novel fine-tuning task, our method produces datasets that are free from identifiable information while preserving the statistical properties necessary for model training. We conduct utility testing to evaluate the performance of machine learning models trained on the cloned datasets. The results demonstrate that our cloned datasets not only uphold privacy standards but also enhance model performance compared to those trained on traditional anonymized datasets. This work offers a viable solution for the ethical and effective utilization of sensitive medical data in machine learning, facilitating progress in medical research and the development of robust predictive models.
In-Context Learning on a Budget: A Case Study in Named Entity Recognition
Jun 19, 2024Few shot in-context learning (ICL) typically assumes access to large annotated training sets. However, in many real world scenarios, such as domain adaptation, there is only a limited budget to annotate a small number of samples, with the goal of maximizing downstream performance. We study various methods for selecting samples to annotate within a predefined budget, specifically focusing on the named entity recognition (NER) task, which has real-world applications, is expensive to annotate, and is relatively less studied in ICL setups. Across different models and datasets, we find that a relatively small pool of annotated samples can achieve results comparable to using the entire training set. Moreover, we discover that random selection of samples for annotation yields surprisingly good performance. Finally, we observe that a diverse annotation pool is correlated with improved performance. We hope that future work adopts our realistic paradigm which takes annotation budget into account.
Federated Multilingual Models for Medical Transcript Analysis
Nov 04, 2022Federated Learning (FL) is a novel machine learning approach that allows the model trainer to access more data samples, by training the model across multiple decentralized data sources, while data access constraints are in place. Such trained models can achieve significantly higher performance beyond what can be done when trained on a single data source. As part of FL's promises, none of the training data is ever transmitted to any central location, ensuring that sensitive data remains local and private. These characteristics make FL perfectly suited for large-scale applications in healthcare, where a variety of compliance constraints restrict how data may be handled, processed, and stored. Despite the apparent benefits of federated learning, the heterogeneity in the local data distributions pose significant challenges, and such challenges are even more pronounced in the case of multilingual data providers. In this paper we present a federated learning system for training a large-scale multi-lingual model suitable for fine-tuning on downstream tasks such as medical entity tagging. Our work represents one of the first such production-scale systems, capable of training across multiple highly heterogeneous data providers, and achieving levels of accuracy that could not be otherwise achieved by using central training with public data. Finally, we show that the global model performance can be further improved by a training step performed locally.
Question Answering as an Automatic Evaluation Metric for News Article Summarization
Jun 02, 2019
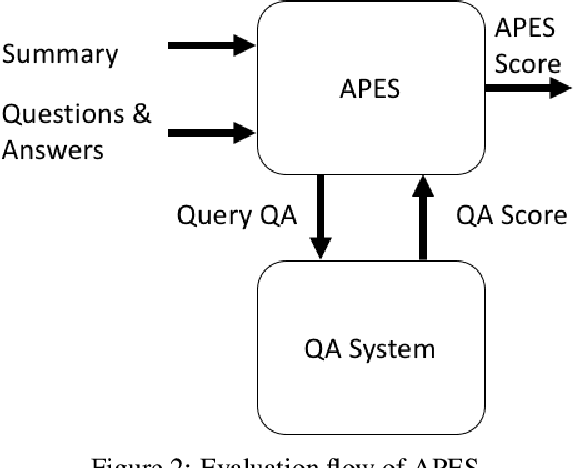

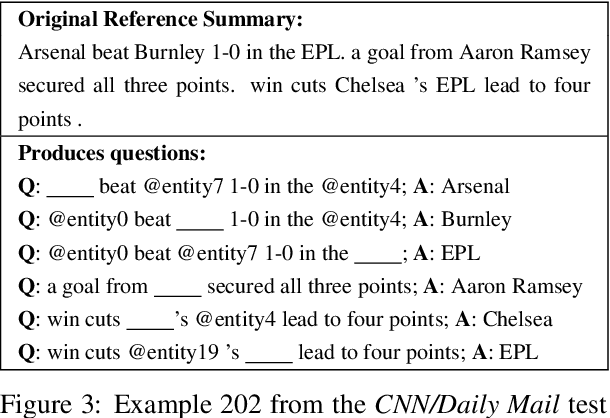
Recent work in the field of automatic summarization and headline generation focuses on maximizing ROUGE scores for various news datasets. We present an alternative, extrinsic, evaluation metric for this task, Answering Performance for Evaluation of Summaries. APES utilizes recent progress in the field of reading-comprehension to quantify the ability of a summary to answer a set of manually created questions regarding central entities in the source article. We first analyze the strength of this metric by comparing it to known manual evaluation metrics. We then present an end-to-end neural abstractive model that maximizes APES, while increasing ROUGE scores to competitive results.
Query Focused Abstractive Summarization: Incorporating Query Relevance, Multi-Document Coverage, and Summary Length Constraints into seq2seq Models
Jan 25, 2018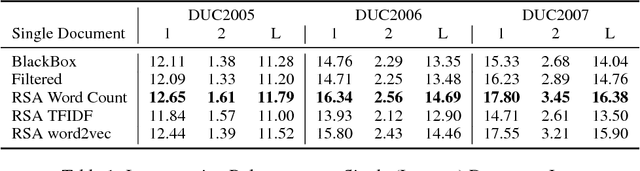
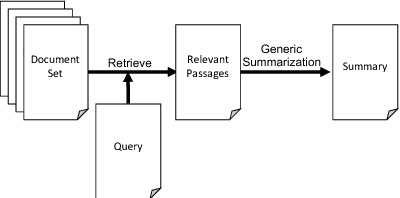

Query Focused Summarization (QFS) has been addressed mostly using extractive methods. Such methods, however, produce text which suffers from low coherence. We investigate how abstractive methods can be applied to QFS, to overcome such limitations. Recent developments in neural-attention based sequence-to-sequence models have led to state-of-the-art results on the task of abstractive generic single document summarization. Such models are trained in an end to end method on large amounts of training data. We address three aspects to make abstractive summarization applicable to QFS: (a)since there is no training data, we incorporate query relevance into a pre-trained abstractive model; (b) since existing abstractive models are trained in a single-document setting, we design an iterated method to embed abstractive models within the multi-document requirement of QFS; (c) the abstractive models we adapt are trained to generate text of specific length (about 100 words), while we aim at generating output of a different size (about 250 words); we design a way to adapt the target size of the generated summaries to a given size ratio. We compare our method (Relevance Sensitive Attention for QFS) to extractive baselines and with various ways to combine abstractive models on the DUC QFS datasets and demonstrate solid improvements on ROUGE performance.
Multi-Label Classification of Patient Notes a Case Study on ICD Code Assignment
Nov 20, 2017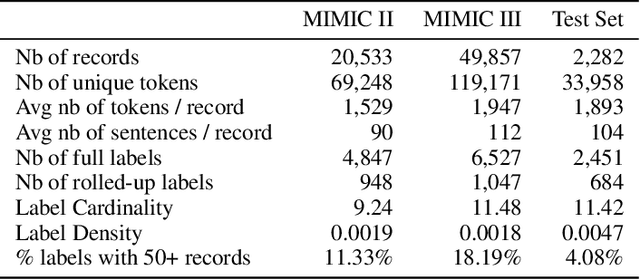
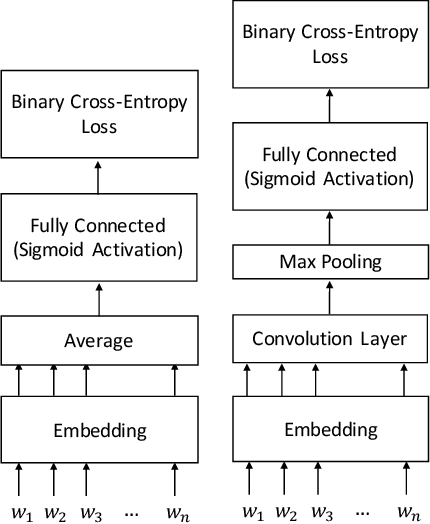

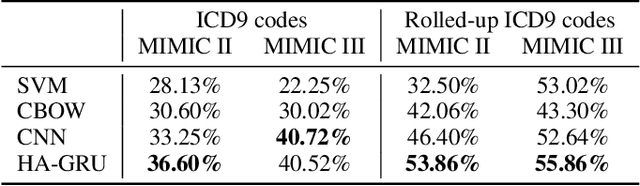
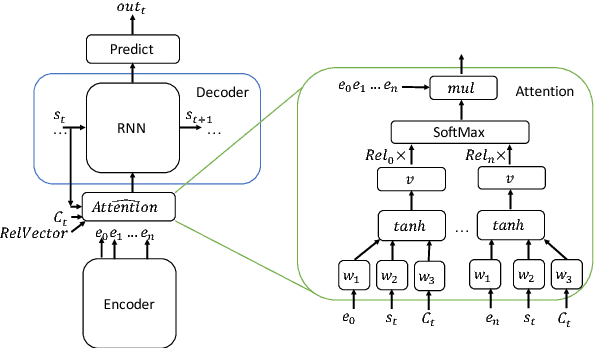
In the context of the Electronic Health Record, automated diagnosis coding of patient notes is a useful task, but a challenging one due to the large number of codes and the length of patient notes. We investigate four models for assigning multiple ICD codes to discharge summaries taken from both MIMIC II and III. We present Hierarchical Attention-GRU (HA-GRU), a hierarchical approach to tag a document by identifying the sentences relevant for each label. HA-GRU achieves state-of-the art results. Furthermore, the learned sentence-level attention layer highlights the model decision process, allows easier error analysis, and suggests future directions for improvement.