 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring How LLMs Capture and Represent Domain-Specific Knowledge
Apr 24, 2025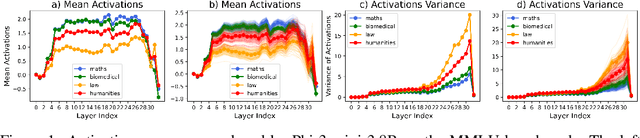

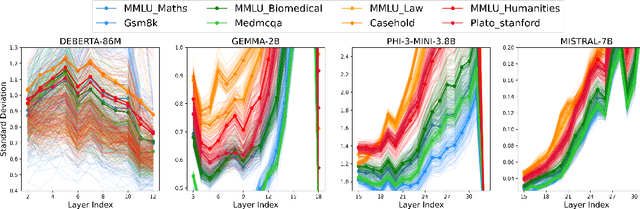

We study whether Large Language Models (LLMs) inherently capture domain-specific nuances in natural language. Our experiments probe the domain sensitivity of LLMs by examining their ability to distinguish queries from different domains using hidden states generated during the prefill phase. We reveal latent domain-related trajectories that indicate the model's internal recognition of query domains. We also study the robustness of these domain representations to variations in prompt styles and sources. Our approach leverages these representations for model selection, mapping the LLM that best matches the domain trace of the input query (i.e., the model with the highest performance on similar traces). Our findings show that LLMs can differentiate queries for related domains, and that the fine-tuned model is not always the most accurate. Unlike previous work, our interpretations apply to both closed and open-ended generative tasks
EcoAct: Economic Agent Determines When to Register What Action
Nov 03, 2024



Recent advancements have enabled Large Language Models (LLMs) to function as agents that can perform actions using external tools. This requires registering, i.e., integrating tool information into the LLM context prior to taking actions. Current methods indiscriminately incorporate all candidate tools into the agent's context and retain them across multiple reasoning steps. This process remains opaque to LLM agents and is not integrated into their reasoning procedures, leading to inefficiencies due to increased context length from irrelevant tools. To address this, we introduce EcoAct, a tool using algorithm that allows LLMs to selectively register tools as needed, optimizing context use. By integrating the tool registration process into the reasoning procedure, EcoAct reduces computational costs by over 50% in multiple steps reasoning tasks while maintaining performance, as demonstrated through extensive experiments. Moreover, it can be plugged into any reasoning pipeline with only minor modifications to the prompt, making it applicable to LLM agents now and future.
Sweeping Heterogeneity with Smart MoPs: Mixture of Prompts for LLM Task Adaptation
Oct 05, 2023

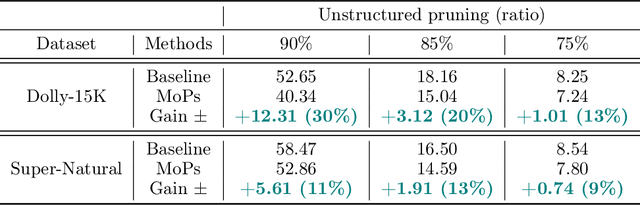
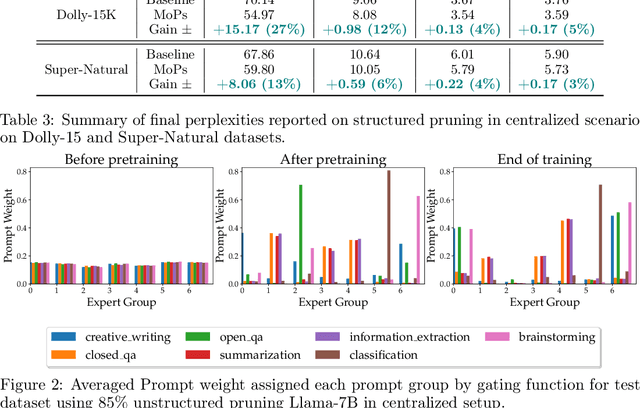
Large Language Models (LLMs) have the ability to solve a variety of tasks, such as text summarization and mathematical questions, just out of the box, but they are often trained with a single task in mind. Due to high computational costs, the current trend is to use prompt instruction tuning to better adjust monolithic, pretrained LLMs for new -- but often individual -- downstream tasks. Thus, how one would expand prompt tuning to handle -- concomitantly -- heterogeneous tasks and data distributions is a widely open question. To address this gap, we suggest the use of \emph{Mixture of Prompts}, or MoPs, associated with smart gating functionality: the latter -- whose design is one of the contributions of this paper -- can identify relevant skills embedded in different groups of prompts and dynamically assign combined experts (i.e., collection of prompts), based on the target task. Additionally, MoPs are empirically agnostic to any model compression technique applied -- for efficiency reasons -- as well as instruction data source and task composition. In practice, MoPs can simultaneously mitigate prompt training "interference" in multi-task, multi-source scenarios (e.g., task and data heterogeneity across sources), as well as possible implications from model approximations. As a highlight, MoPs manage to decrease final perplexity from $\sim20\%$ up to $\sim70\%$, as compared to baselines, in the federated scenario, and from $\sim 3\%$ up to $\sim30\%$ in the centralized scenario.
Fed-ZERO: Efficient Zero-shot Personalization with Federated Mixture of Experts
Jun 14, 2023



One of the goals in Federated Learning (FL) is to create personalized models that can adapt to the context of each participating client, while utilizing knowledge from a shared global model. Yet, often, personalization requires a fine-tuning step using clients' labeled data in order to achieve good performance. This may not be feasible in scenarios where incoming clients are fresh and/or have privacy concerns. It, then, remains open how one can achieve zero-shot personalization in these scenarios. We propose a novel solution by using a Mixture-of-Experts (MoE) framework within a FL setup. Our method leverages the diversity of the clients to train specialized experts on different subsets of classes, and a gating function to route the input to the most relevant expert(s). Our gating function harnesses the knowledge of a pretrained model common expert to enhance its routing decisions on-the-fly. As a highlight, our approach can improve accuracy up to 18\% in state of the art FL settings, while maintaining competitive zero-shot performance. In practice, our method can handle non-homogeneous data distributions, scale more efficiently, and improve the state-of-the-art performance on common FL benchmarks.
Federated Multilingual Models for Medical Transcript Analysis
Nov 04, 2022Federated Learning (FL) is a novel machine learning approach that allows the model trainer to access more data samples, by training the model across multiple decentralized data sources, while data access constraints are in place. Such trained models can achieve significantly higher performance beyond what can be done when trained on a single data source. As part of FL's promises, none of the training data is ever transmitted to any central location, ensuring that sensitive data remains local and private. These characteristics make FL perfectly suited for large-scale applications in healthcare, where a variety of compliance constraints restrict how data may be handled, processed, and stored. Despite the apparent benefits of federated learning, the heterogeneity in the local data distributions pose significant challenges, and such challenges are even more pronounced in the case of multilingual data providers. In this paper we present a federated learning system for training a large-scale multi-lingual model suitable for fine-tuning on downstream tasks such as medical entity tagging. Our work represents one of the first such production-scale systems, capable of training across multiple highly heterogeneous data providers, and achieving levels of accuracy that could not be otherwise achieved by using central training with public data. Finally, we show that the global model performance can be further improved by a training step performed locally.
FLUTE: A Scalable, Extensible Framework for High-Performance Federated Learning Simulations
Mar 25, 2022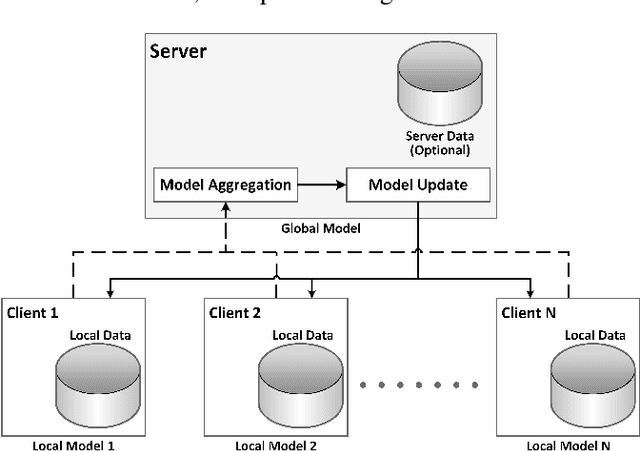
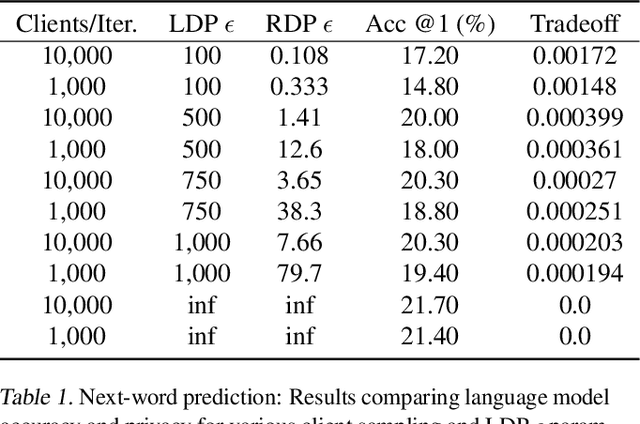
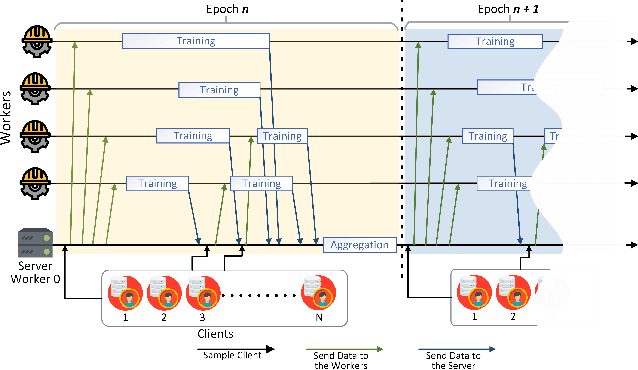
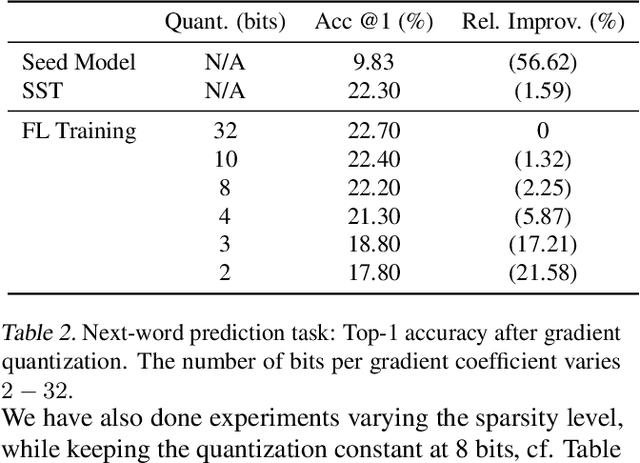
In this paper we introduce "Federated Learning Utilities and Tools for Experimentation" (FLUTE), a high-performance open source platform for federated learning research and offline simulations. The goal of FLUTE is to enable rapid prototyping and simulation of new federated learning algorithms at scale, including novel optimization, privacy, and communications strategies. We describe the architecture of FLUTE, enabling arbitrary federated modeling schemes to be realized, we compare the platform with other state-of-the-art platforms, and we describe available features of FLUTE for experimentation in core areas of active research, such as optimization, privacy and scalability. We demonstrate the effectiveness of the platform with a series of experiments for text prediction and speech recognition, including the addition of differential privacy, quantization, scaling and a variety of optimization and federation approaches.