 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Scheduling for LLM Inference
Jun 13, 2025Conventional operating system scheduling algorithms are largely content-ignorant, making decisions based on factors such as latency or fairness without considering the actual intents or semantics of processes. Consequently, these algorithms often do not prioritize tasks that require urgent attention or carry higher importance, such as in emergency management scenarios. However, recent advances in language models enable semantic analysis of processes, allowing for more intelligent and context-aware scheduling decisions. In this paper, we introduce the concept of semantic scheduling in scheduling of requests from large language models (LLM), where the semantics of the process guide the scheduling priorities. We present a novel scheduling algorithm with optimal time complexity, designed to minimize the overall waiting time in LLM-based prompt scheduling. To illustrate its effectiveness, we present a medical emergency management application, underscoring the potential benefits of semantic scheduling for critical, time-sensitive tasks. The code and data are available at https://github.com/Wenyueh/latency_optimization_with_priority_constraints.
Why Does Your CoT Prompt (Not) Work? Theoretical Analysis of Prompt Space Complexity, its Interaction with Answer Space During CoT Reasoning with LLMs: A Recurrent Perspective
Mar 13, 2025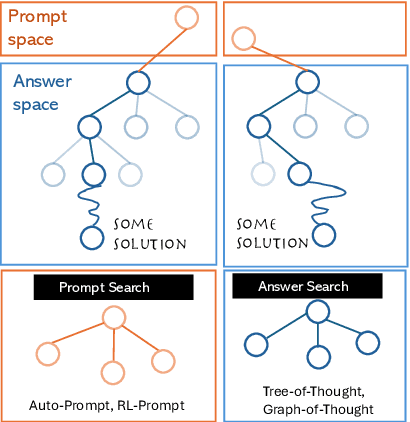
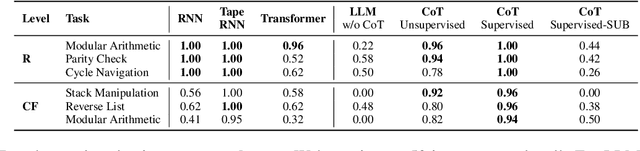

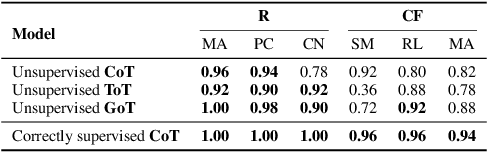
Despite the remarkable successes of Large Language Models (LLMs), their fundamental Transformer architecture possesses inherent theoretical limitations that restrict their capability to handle reasoning tasks with increasing computational complexity. Chain-of-Thought (CoT) prompting has emerged as a practical solution, supported by several theoretical studies. However, current CoT-based methods (including ToT, GoT, etc.) generally adopt a "one-prompt-fits-all" strategy, using fixed templates (e.g., "think step by step") across diverse reasoning tasks. This method forces models to navigate an extremely complex prompt space to identify effective reasoning paths. The current prompt designing research are also heavily relying on trial-and-error rather than theoretically informed guidance. In this paper, we provide a rigorous theoretical analysis of the complexity and interplay between two crucial spaces: the prompt space (the space of potential prompt structures) and the answer space (the space of reasoning solutions generated by LLMs) in CoT reasoning. We demonstrate how reliance on a single universal prompt (e.g. think step by step) can negatively impact the theoretical computability of LLMs, illustrating that prompt complexity directly influences the structure and effectiveness of the navigation in answer space. Our analysis highlights that sometimes human supervision is critical for efficiently navigating the prompt space. We theoretically and empirically show that task-specific prompting significantly outperforms unsupervised prompt generation, emphasizing the necessity of thoughtful human guidance in CoT prompting.
EcoAct: Economic Agent Determines When to Register What Action
Nov 03, 2024



Recent advancements have enabled Large Language Models (LLMs) to function as agents that can perform actions using external tools. This requires registering, i.e., integrating tool information into the LLM context prior to taking actions. Current methods indiscriminately incorporate all candidate tools into the agent's context and retain them across multiple reasoning steps. This process remains opaque to LLM agents and is not integrated into their reasoning procedures, leading to inefficiencies due to increased context length from irrelevant tools. To address this, we introduce EcoAct, a tool using algorithm that allows LLMs to selectively register tools as needed, optimizing context use. By integrating the tool registration process into the reasoning procedure, EcoAct reduces computational costs by over 50% in multiple steps reasoning tasks while maintaining performance, as demonstrated through extensive experiments. Moreover, it can be plugged into any reasoning pipeline with only minor modifications to the prompt, making it applicable to LLM agents now and future.
Supervised Chain of Thought
Oct 18, 2024



Large Language Models (LLMs) have revolutionized natural language processing and hold immense potential for advancing Artificial Intelligence. However, the core architecture of most mainstream LLMs -- the Transformer -- has inherent limitations in computational depth, rendering them theoretically incapable of solving many reasoning tasks that demand increasingly deep computations. Chain of Thought (CoT) prompting has emerged as a technique to address these architectural limitations, as evidenced by several theoretical studies. It offers a promising approach to solving complex reasoning tasks that were previously beyond the capabilities of these models. Despite its successes, CoT and its variants (such as Tree of Thought, Graph of Thought, etc.) rely on a "one-prompt-for-all" approach, using a single prompt structure (e.g., "think step by step") for a wide range of tasks -- from counting and sorting to solving mathematical and algorithmic problems. This approach poses significant challenges for models to generate the correct reasoning steps, as the model must navigate through a vast prompt template space to find the appropriate template for each task. In this work, we build upon previous theoretical analyses of CoT to demonstrate how the one-prompt-for-all approach can negatively affect the computability of LLMs. We partition the solution search space into two: the prompt space and the answer space. Our findings show that task-specific supervision is essential for navigating the prompt space accurately and achieving optimal performance. Through experiments with state-of-the-art LLMs, we reveal a gap in reasoning performance when supervision is applied versus when it is not.
OCCAM: Towards Cost-Efficient and Accuracy-Aware Image Classification Inference
Jun 06, 2024



Image classification is a fundamental building block for a majority of computer vision applications. With the growing popularity and capacity of machine learning models, people can easily access trained image classifiers as a service online or offline. However, model use comes with a cost and classifiers of higher capacity usually incur higher inference costs. To harness the respective strengths of different classifiers, we propose a principled approach, OCCAM, to compute the best classifier assignment strategy over image classification queries (termed as the optimal model portfolio) so that the aggregated accuracy is maximized, under user-specified cost budgets. Our approach uses an unbiased and low-variance accuracy estimator and effectively computes the optimal solution by solving an integer linear programming problem. On a variety of real-world datasets, OCCAM achieves 40% cost reduction with little to no accuracy drop.
Hybrid LLM: Cost-Efficient and Quality-Aware Query Routing
Apr 22, 2024Large language models (LLMs) excel in most NLP tasks but also require expensive cloud servers for deployment due to their size, while smaller models that can be deployed on lower cost (e.g., edge) devices, tend to lag behind in terms of response quality. Therefore in this work we propose a hybrid inference approach which combines their respective strengths to save cost and maintain quality. Our approach uses a router that assigns queries to the small or large model based on the predicted query difficulty and the desired quality level. The desired quality level can be tuned dynamically at test time to seamlessly trade quality for cost as per the scenario requirements. In experiments our approach allows us to make up to 40% fewer calls to the large model, with no drop in response quality.
LLM Performance Predictors are good initializers for Architecture Search
Oct 25, 2023Large language models (LLMs) have become an integral component in solving a wide range of NLP tasks. In this work, we explore a novel use case of using LLMs to build performance predictors (PP): models that, given a specific deep neural network architecture, predict its performance on a downstream task. We design PP prompts for LLMs consisting of: (i) role: description of the role assigned to the LLM, (ii) instructions: set of instructions to be followed by the LLM to carry out performance prediction, (iii) hyperparameters: a definition of each architecture-specific hyperparameter and (iv) demonstrations: sample architectures along with their efficiency metrics and 'training from scratch' performance. For machine translation (MT) tasks, we discover that GPT-4 with our PP prompts (LLM-PP) can predict the performance of architecture with a mean absolute error matching the SOTA and a marginal degradation in rank correlation coefficient compared to SOTA performance predictors. Further, we show that the predictions from LLM-PP can be distilled to a small regression model (LLM-Distill-PP). LLM-Distill-PP models surprisingly retain the performance of LLM-PP largely and can be a cost-effective alternative for heavy use cases of performance estimation. Specifically, for neural architecture search (NAS), we propose a Hybrid-Search algorithm for NAS (HS-NAS), which uses LLM-Distill-PP for the initial part of search, resorting to the baseline predictor for rest of the search. We show that HS-NAS performs very similar to SOTA NAS across benchmarks, reduces search hours by 50% roughly, and in some cases, improves latency, GFLOPs, and model size.
On Efficient Approximate Queries over Machine Learning Models
Jun 06, 2022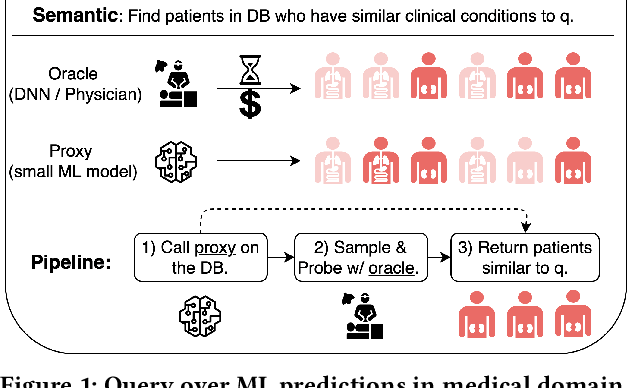

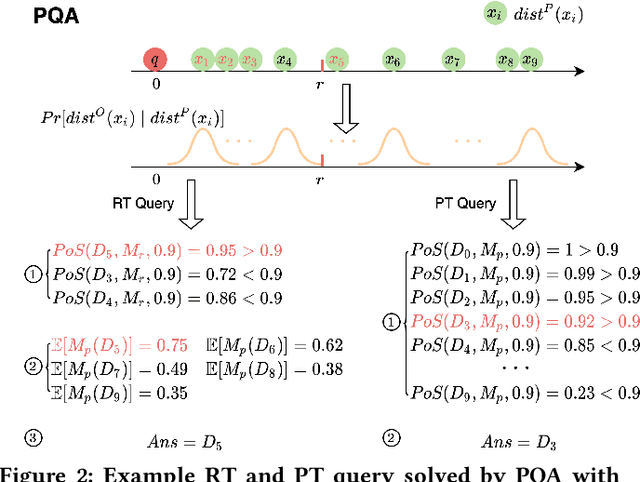

The question of answering queries over ML predictions has been gaining attention in the database community. This question is challenging because the cost of finding high quality answers corresponds to invoking an oracle such as a human expert or an expensive deep neural network model on every single item in the DB and then applying the query. We develop a novel unified framework for approximate query answering by leveraging a proxy to minimize the oracle usage of finding high quality answers for both Precision-Target (PT) and Recall-Target (RT) queries. Our framework uses a judicious combination of invoking the expensive oracle on data samples and applying the cheap proxy on the objects in the DB. It relies on two assumptions. Under the Proxy Quality assumption, proxy quality can be quantified in a probabilistic manner w.r.t. the oracle. This allows us to develop two algorithms: PQA that efficiently finds high quality answers with high probability and no oracle calls, and PQE, a heuristic extension that achieves empirically good performance with a small number of oracle calls. Alternatively, under the Core Set Closure assumption, we develop two algorithms: CSC that efficiently returns high quality answers with high probability and minimal oracle usage, and CSE, which extends it to more general settings. Our extensive experiments on five real-world datasets on both query types, PT and RT, demonstrate that our algorithms outperform the state-of-the-art and achieve high result quality with provable statistical guarantees.