 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFORESTLLM: Large Language Models Make Random Forest Great on Few-shot Tabular Learning
Jan 16, 2026Tabular data high-stakes critical decision-making in domains such as finance, healthcare, and scientific discovery. Yet, learning effectively from tabular data in few-shot settings, where labeled examples are scarce, remains a fundamental challenge. Traditional tree-based methods often falter in these regimes due to their reliance on statistical purity metrics, which become unstable and prone to overfitting with limited supervision. At the same time, direct applications of large language models (LLMs) often overlook its inherent structure, leading to suboptimal performance. To overcome these limitations, we propose FORESTLLM, a novel framework that unifies the structural inductive biases of decision forests with the semantic reasoning capabilities of LLMs. Crucially, FORESTLLM leverages the LLM only during training, treating it as an offline model designer that encodes rich, contextual knowledge into a lightweight, interpretable forest model, eliminating the need for LLM inference at test time. Our method is two-fold. First, we introduce a semantic splitting criterion in which the LLM evaluates candidate partitions based on their coherence over both labeled and unlabeled data, enabling the induction of more robust and generalizable tree structures under few-shot supervision. Second, we propose a one-time in-context inference mechanism for leaf node stabilization, where the LLM distills the decision path and its supporting examples into a concise, deterministic prediction, replacing noisy empirical estimates with semantically informed outputs. Across a diverse suite of few-shot classification and regression benchmarks, FORESTLLM achieves state-of-the-art performance.
Reflection Pretraining Enables Token-Level Self-Correction in Biological Sequence Models
Dec 24, 2025



Chain-of-Thought (CoT) prompting has significantly advanced task-solving capabilities in natural language processing with large language models. Unlike standard prompting, CoT encourages the model to generate intermediate reasoning steps, non-answer tokens, that help guide the model toward more accurate final outputs. These intermediate steps enable more complex reasoning processes such as error correction, memory management, future planning, and self-reflection. However, applying CoT to non-natural language domains, such as protein and RNA language models, is not yet possible, primarily due to the limited expressiveness of their token spaces (e.g., amino acid tokens). In this work, we propose and define the concept of language expressiveness: the ability of a given language, using its tokens and grammar, to encode information. We show that the limited expressiveness of protein language severely restricts the applicability of CoT-style reasoning. To overcome this, we introduce reflection pretraining, for the first time in a biological sequence model, which enables the model to engage in intermediate reasoning through the generation of auxiliary "thinking tokens" beyond simple answer tokens. Theoretically, we demonstrate that our augmented token set significantly enhances biological language expressiveness, thereby improving the overall reasoning capacity of the model. Experimentally, our pretraining approach teaches protein models to self-correct and leads to substantial performance gains compared to standard pretraining.
Probing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
Dec 18, 2025Despite advances in scientific AI, a coherent framework for Scientific General Intelligence (SGI)-the ability to autonomously conceive, investigate, and reason across scientific domains-remains lacking. We present an operational SGI definition grounded in the Practical Inquiry Model (PIM: Deliberation, Conception, Action, Perception) and operationalize it via four scientist-aligned tasks: deep research, idea generation, dry/wet experiments, and experimental reasoning. SGI-Bench comprises over 1,000 expert-curated, cross-disciplinary samples inspired by Science's 125 Big Questions, enabling systematic evaluation of state-of-the-art LLMs. Results reveal gaps: low exact match (10--20%) in deep research despite step-level alignment; ideas lacking feasibility and detail; high code executability but low execution result accuracy in dry experiments; low sequence fidelity in wet protocols; and persistent multimodal comparative-reasoning challenges. We further introduce Test-Time Reinforcement Learning (TTRL), which optimizes retrieval-augmented novelty rewards at inference, enhancing hypothesis novelty without reference answer. Together, our PIM-grounded definition, workflow-centric benchmark, and empirical insights establish a foundation for AI systems that genuinely participate in scientific discovery.
Accurate de novo sequencing of the modified proteome with OmniNovo
Dec 13, 2025Post-translational modifications (PTMs) serve as a dynamic chemical language regulating protein function, yet current proteomic methods remain blind to a vast portion of the modified proteome. Standard database search algorithms suffer from a combinatorial explosion of search spaces, limiting the identification of uncharacterized or complex modifications. Here we introduce OmniNovo, a unified deep learning framework for reference-free sequencing of unmodified and modified peptides directly from tandem mass spectra. Unlike existing tools restricted to specific modification types, OmniNovo learns universal fragmentation rules to decipher diverse PTMs within a single coherent model. By integrating a mass-constrained decoding algorithm with rigorous false discovery rate estimation, OmniNovo achieves state-of-the-art accuracy, identifying 51\% more peptides than standard approaches at a 1\% false discovery rate. Crucially, the model generalizes to biological sites unseen during training, illuminating the dark matter of the proteome and enabling unbiased comprehensive analysis of cellular regulation.
TimeSeriesScientist: A General-Purpose AI Agent for Time Series Analysis
Oct 02, 2025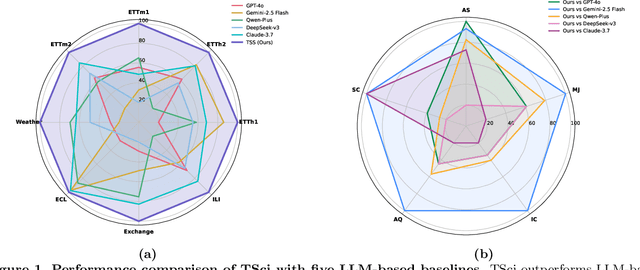
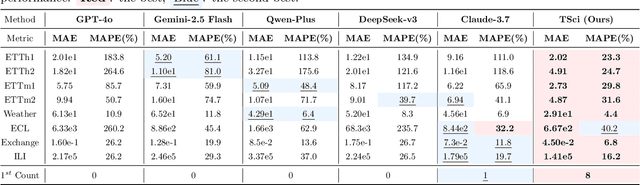
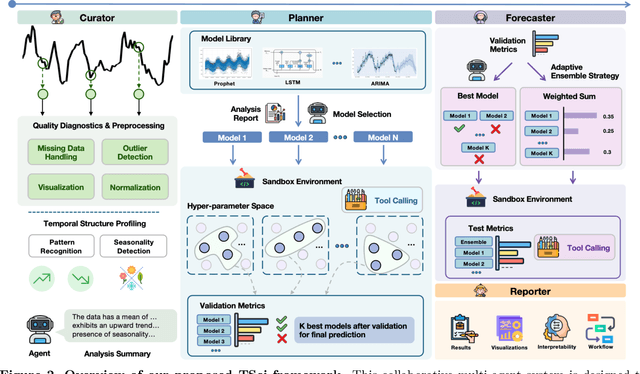
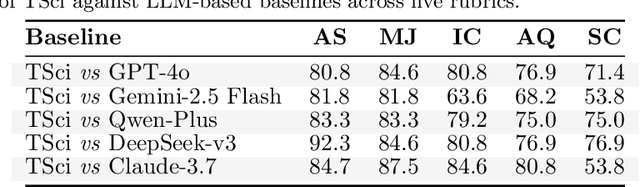
Time series forecasting is central to decision-making in domains as diverse as energy, finance, climate, and public health. In practice, forecasters face thousands of short, noisy series that vary in frequency, quality, and horizon, where the dominant cost lies not in model fitting, but in the labor-intensive preprocessing, validation, and ensembling required to obtain reliable predictions. Prevailing statistical and deep learning models are tailored to specific datasets or domains and generalize poorly. A general, domain-agnostic framework that minimizes human intervention is urgently in demand. In this paper, we introduce TimeSeriesScientist (TSci), the first LLM-driven agentic framework for general time series forecasting. The framework comprises four specialized agents: Curator performs LLM-guided diagnostics augmented by external tools that reason over data statistics to choose targeted preprocessing; Planner narrows the hypothesis space of model choice by leveraging multi-modal diagnostics and self-planning over the input; Forecaster performs model fitting and validation and, based on the results, adaptively selects the best model configuration as well as ensemble strategy to make final predictions; and Reporter synthesizes the whole process into a comprehensive, transparent report. With transparent natural-language rationales and comprehensive reports, TSci transforms the forecasting workflow into a white-box system that is both interpretable and extensible across tasks. Empirical results on eight established benchmarks demonstrate that TSci consistently outperforms both statistical and LLM-based baselines, reducing forecast error by an average of 10.4% and 38.2%, respectively. Moreover, TSci produces a clear and rigorous report that makes the forecasting workflow more transparent and interpretable.
PosterGen: Aesthetic-Aware Paper-to-Poster Generation via Multi-Agent LLMs
Aug 24, 2025Multi-agent systems built upon large language models (LLMs) have demonstrated remarkable capabilities in tackling complex compositional tasks. In this work, we apply this paradigm to the paper-to-poster generation problem, a practical yet time-consuming process faced by researchers preparing for conferences. While recent approaches have attempted to automate this task, most neglect core design and aesthetic principles, resulting in posters that require substantial manual refinement. To address these design limitations, we propose PosterGen, a multi-agent framework that mirrors the workflow of professional poster designers. It consists of four collaborative specialized agents: (1) Parser and Curator agents extract content from the paper and organize storyboard; (2) Layout agent maps the content into a coherent spatial layout; (3) Stylist agents apply visual design elements such as color and typography; and (4) Renderer composes the final poster. Together, these agents produce posters that are both semantically grounded and visually appealing. To evaluate design quality, we introduce a vision-language model (VLM)-based rubric that measures layout balance, readability, and aesthetic coherence. Experimental results show that PosterGen consistently matches in content fidelity, and significantly outperforms existing methods in visual designs, generating posters that are presentation-ready with minimal human refinements.
Curriculum Learning for Biological Sequence Prediction: The Case of De Novo Peptide Sequencing
Jun 16, 2025Peptide sequencing-the process of identifying amino acid sequences from mass spectrometry data-is a fundamental task in proteomics. Non-Autoregressive Transformers (NATs) have proven highly effective for this task, outperforming traditional methods. Unlike autoregressive models, which generate tokens sequentially, NATs predict all positions simultaneously, leveraging bidirectional context through unmasked self-attention. However, existing NAT approaches often rely on Connectionist Temporal Classification (CTC) loss, which presents significant optimization challenges due to CTC's complexity and increases the risk of training failures. To address these issues, we propose an improved non-autoregressive peptide sequencing model that incorporates a structured protein sequence curriculum learning strategy. This approach adjusts protein's learning difficulty based on the model's estimated protein generational capabilities through a sampling process, progressively learning peptide generation from simple to complex sequences. Additionally, we introduce a self-refining inference-time module that iteratively enhances predictions using learned NAT token embeddings, improving sequence accuracy at a fine-grained level. Our curriculum learning strategy reduces NAT training failures frequency by more than 90% based on sampled training over various data distributions. Evaluations on nine benchmark species demonstrate that our approach outperforms all previous methods across multiple metrics and species.
Scientists' First Exam: Probing Cognitive Abilities of MLLM via Perception, Understanding, and Reasoning
Jun 12, 2025Scientific discoveries increasingly rely on complex multimodal reasoning based on information-intensive scientific data and domain-specific expertise. Empowered by expert-level scientific benchmarks, scientific Multimodal Large Language Models (MLLMs) hold the potential to significantly enhance this discovery process in realistic workflows. However, current scientific benchmarks mostly focus on evaluating the knowledge understanding capabilities of MLLMs, leading to an inadequate assessment of their perception and reasoning abilities. To address this gap, we present the Scientists' First Exam (SFE) benchmark, designed to evaluate the scientific cognitive capacities of MLLMs through three interconnected levels: scientific signal perception, scientific attribute understanding, scientific comparative reasoning. Specifically, SFE comprises 830 expert-verified VQA pairs across three question types, spanning 66 multimodal tasks across five high-value disciplines. Extensive experiments reveal that current state-of-the-art GPT-o3 and InternVL-3 achieve only 34.08% and 26.52% on SFE, highlighting significant room for MLLMs to improve in scientific realms. We hope the insights obtained in SFE will facilitate further developments in AI-enhanced scientific discoveries.
Universal Biological Sequence Reranking for Improved De Novo Peptide Sequencing
May 23, 2025De novo peptide sequencing is a critical task in proteomics. However, the performance of current deep learning-based methods is limited by the inherent complexity of mass spectrometry data and the heterogeneous distribution of noise signals, leading to data-specific biases. We present RankNovo, the first deep reranking framework that enhances de novo peptide sequencing by leveraging the complementary strengths of multiple sequencing models. RankNovo employs a list-wise reranking approach, modeling candidate peptides as multiple sequence alignments and utilizing axial attention to extract informative features across candidates. Additionally, we introduce two new metrics, PMD (Peptide Mass Deviation) and RMD (residual Mass Deviation), which offer delicate supervision by quantifying mass differences between peptides at both the sequence and residue levels. Extensive experiments demonstrate that RankNovo not only surpasses its base models used to generate training candidates for reranking pre-training, but also sets a new state-of-the-art benchmark. Moreover, RankNovo exhibits strong zero-shot generalization to unseen models whose generations were not exposed during training, highlighting its robustness and potential as a universal reranking framework for peptide sequencing. Our work presents a novel reranking strategy that fundamentally challenges existing single-model paradigms and advances the frontier of accurate de novo sequencing. Our source code is provided on GitHub.
Tokenization Constraints in LLMs: A Study of Symbolic and Arithmetic Reasoning Limits
May 20, 2025Tokenization is the first - and often underappreciated - layer of computation in language models. While Chain-of-Thought (CoT) prompting enables transformer models to approximate recurrent computation by externalizing intermediate steps, we show that the success of such reasoning is fundamentally bounded by the structure of tokenized inputs. This work presents a theoretical and empirical investigation into how tokenization schemes, particularly subword-based methods like byte-pair encoding (BPE), impede symbolic computation by merging or obscuring atomic reasoning units. We introduce the notion of Token Awareness to formalize how poor token granularity disrupts logical alignment and prevents models from generalizing symbolic procedures. Through systematic evaluation on arithmetic and symbolic tasks, we demonstrate that token structure dramatically affect reasoning performance, causing failure even with CoT, while atomically-aligned formats unlock strong generalization, allowing small models (e.g., GPT-4o-mini) to outperform larger systems (e.g., o1) in structured reasoning. Our findings reveal that symbolic reasoning ability in LLMs is not purely architectural, but deeply conditioned on token-level representations.