 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenization Constraints in LLMs: A Study of Symbolic and Arithmetic Reasoning Limits
May 20, 2025Tokenization is the first - and often underappreciated - layer of computation in language models. While Chain-of-Thought (CoT) prompting enables transformer models to approximate recurrent computation by externalizing intermediate steps, we show that the success of such reasoning is fundamentally bounded by the structure of tokenized inputs. This work presents a theoretical and empirical investigation into how tokenization schemes, particularly subword-based methods like byte-pair encoding (BPE), impede symbolic computation by merging or obscuring atomic reasoning units. We introduce the notion of Token Awareness to formalize how poor token granularity disrupts logical alignment and prevents models from generalizing symbolic procedures. Through systematic evaluation on arithmetic and symbolic tasks, we demonstrate that token structure dramatically affect reasoning performance, causing failure even with CoT, while atomically-aligned formats unlock strong generalization, allowing small models (e.g., GPT-4o-mini) to outperform larger systems (e.g., o1) in structured reasoning. Our findings reveal that symbolic reasoning ability in LLMs is not purely architectural, but deeply conditioned on token-level representations.
Why Does Your CoT Prompt (Not) Work? Theoretical Analysis of Prompt Space Complexity, its Interaction with Answer Space During CoT Reasoning with LLMs: A Recurrent Perspective
Mar 13, 2025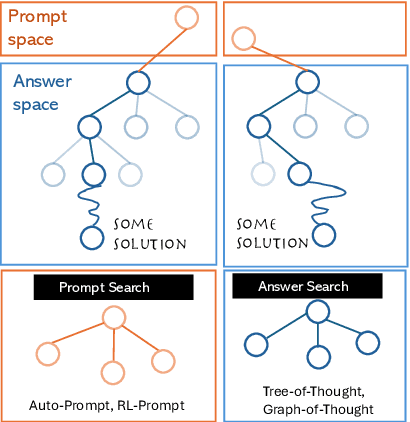
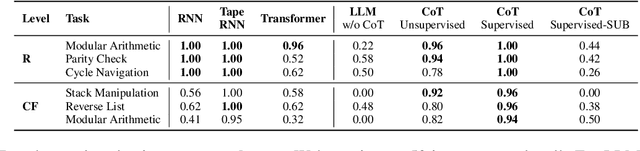

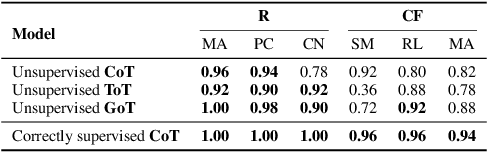
Despite the remarkable successes of Large Language Models (LLMs), their fundamental Transformer architecture possesses inherent theoretical limitations that restrict their capability to handle reasoning tasks with increasing computational complexity. Chain-of-Thought (CoT) prompting has emerged as a practical solution, supported by several theoretical studies. However, current CoT-based methods (including ToT, GoT, etc.) generally adopt a "one-prompt-fits-all" strategy, using fixed templates (e.g., "think step by step") across diverse reasoning tasks. This method forces models to navigate an extremely complex prompt space to identify effective reasoning paths. The current prompt designing research are also heavily relying on trial-and-error rather than theoretically informed guidance. In this paper, we provide a rigorous theoretical analysis of the complexity and interplay between two crucial spaces: the prompt space (the space of potential prompt structures) and the answer space (the space of reasoning solutions generated by LLMs) in CoT reasoning. We demonstrate how reliance on a single universal prompt (e.g. think step by step) can negatively impact the theoretical computability of LLMs, illustrating that prompt complexity directly influences the structure and effectiveness of the navigation in answer space. Our analysis highlights that sometimes human supervision is critical for efficiently navigating the prompt space. We theoretically and empirically show that task-specific prompting significantly outperforms unsupervised prompt generation, emphasizing the necessity of thoughtful human guidance in CoT prompting.
Multi$^2$: Multi-Agent Test-Time Scalable Framework for Multi-Document Processing
Feb 27, 2025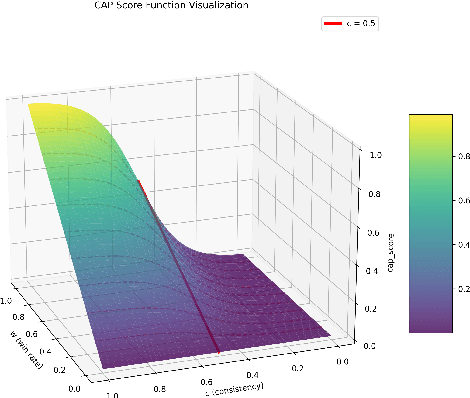
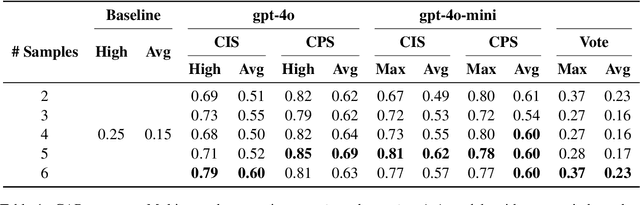
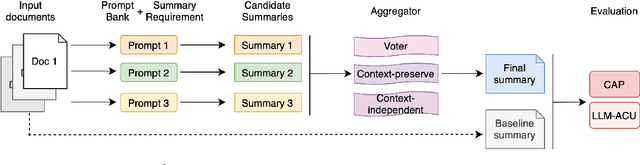
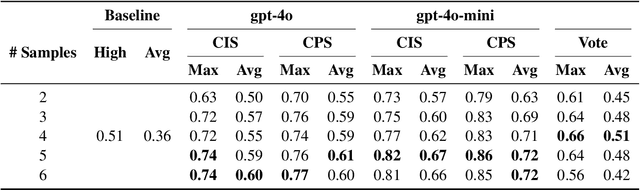
Recent advances in test-time scaling have shown promising results in improving Large Language Models (LLMs) performance through strategic computation allocation during inference. While this approach has demonstrated strong performance improvements in logical and mathematical reasoning tasks, its application to natural language generation (NLG), especially summarization, has yet to be explored. Multi-Document Summarization (MDS) is a challenging task that focuses on extracting and synthesizing useful information from multiple lengthy documents. Unlike reasoning tasks, MDS requires a more nuanced approach to prompt design and ensemble, as there is no "best" prompt to satisfy diverse summarization requirements. To address this, we propose a novel framework that leverages inference-time scaling for this task. Precisely, we take prompt ensemble approach by leveraging various prompt to first generate candidate summaries and then ensemble them with an aggregator to produce a refined summary. We also introduce two new evaluation metrics: Consistency-Aware Preference (CAP) score and LLM Atom-Content-Unit (ACU) score, to enhance LLM's contextual understanding while mitigating its positional bias. Extensive experiments demonstrate the effectiveness of our approach in improving summary quality while identifying and analyzing the scaling boundaries in summarization tasks.
Counting Ability of Large Language Models and Impact of Tokenization
Oct 25, 2024



Transformers, the backbone of modern large language models (LLMs), face inherent architectural limitations that impede their reasoning capabilities. Unlike recurrent networks, Transformers lack recurrent connections, confining them to constant-depth computation. This restriction places them in the complexity class TC$^0$, making them theoretically incapable of solving tasks that demand increasingly deep reasoning as input length grows. Counting, a fundamental component of many reasoning tasks, also requires reasoning depth to grow linearly to be performed inductively. While previous studies have established the upper limits of counting ability in Transformer-based expert models (i.e., models specifically trained for counting tasks), these findings do not directly extend to general-purpose LLMs due to differences in reasoning mechanisms. Recent work has highlighted how Chain of Thought (CoT) reasoning can help alleviate some of the architectural limitations of Transformers in counting tasks. However, little attention has been paid to the role of tokenization in these models. Unlike expert models that often use character-level tokenization, LLMs typically rely on byte-level (BPE) tokenizers, which fundamentally alters the way reasoning is processed. Our work investigates the impact of tokenization on the counting abilities of LLMs, uncovering substantial performance variations based on input tokenization differences. We provide both theoretical and experimental analyses, offering insights into how tokenization choices can undermine models' theoretical computability, thereby inspiring the design of new tokenization methods to enhance reasoning in LLMs.