 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime to Talk: LLM Agents for Asynchronous Group Communication in Mafia Games
Jun 05, 2025LLMs are used predominantly in synchronous communication, where a human user and a model communicate in alternating turns. In contrast, many real-world settings are inherently asynchronous. For example, in group chats, online team meetings, or social games, there is no inherent notion of turns; therefore, the decision of when to speak forms a crucial part of the participant's decision making. In this work, we develop an adaptive asynchronous LLM-agent which, in addition to determining what to say, also decides when to say it. To evaluate our agent, we collect a unique dataset of online Mafia games, including both human participants, as well as our asynchronous agent. Overall, our agent performs on par with human players, both in game performance, as well as in its ability to blend in with the other human players. Our analysis shows that the agent's behavior in deciding when to speak closely mirrors human patterns, although differences emerge in message content. We release all our data and code to support and encourage further research for more realistic asynchronous communication between LLM agents. This work paves the way for integration of LLMs into realistic human group settings, from assistance in team discussions to educational and professional environments where complex social dynamics must be navigated.
Improving Image Captioning by Mimicking Human Reformulation Feedback at Inference-time
Jan 08, 2025



Incorporating automatically predicted human feedback into the process of training generative models has attracted substantial recent interest, while feedback at inference time has received less attention. The typical feedback at training time, i.e., preferences of choice given two samples, does not naturally transfer to the inference phase. We introduce a novel type of feedback -- caption reformulations -- and train models to mimic reformulation feedback based on human annotations. Our method does not require training the image captioning model itself, thereby demanding substantially less computational effort. We experiment with two types of reformulation feedback: first, we collect a dataset of human reformulations that correct errors in the generated captions. We find that incorporating reformulation models trained on this data into the inference phase of existing image captioning models results in improved captions, especially when the original captions are of low quality. We apply our method to non-English image captioning, a domain where robust models are less prevalent, and gain substantial improvement. Second, we apply reformulations to style transfer. Quantitative evaluations reveal state-of-the-art performance on German image captioning and English style transfer, while human validation with a detailed comparative framework exposes the specific axes of improvement.
SAUCE: Synchronous and Asynchronous User-Customizable Environment for Multi-Agent LLM Interaction
Nov 05, 2024



Many human interactions, such as political debates, are carried out in group settings, where there are arbitrarily many participants, each with different views and agendas. To explore such complex social settings, we present SAUCE: a customizable Python platform, allowing researchers to plug-and-play various LLMs participating in discussions on any topic chosen by the user. Our platform takes care of instantiating the models, scheduling their responses, managing the discussion history, and producing a comprehensive output log, all customizable through configuration files, requiring little to no coding skills. A novel feature of SAUCE is our asynchronous communication feature, where models decide when to speak in addition to what to say, thus modeling an important facet of human communication. We show SAUCE's attractiveness in two initial experiments, and invite the community to use it in simulating various group simulations.
Cross-Lingual and Cross-Cultural Variation in Image Descriptions
Sep 25, 2024



Do speakers of different languages talk differently about what they see? Behavioural and cognitive studies report cultural effects on perception; however, these are mostly limited in scope and hard to replicate. In this work, we conduct the first large-scale empirical study of cross-lingual variation in image descriptions. Using a multimodal dataset with 31 languages and images from diverse locations, we develop a method to accurately identify entities mentioned in captions and present in the images, then measure how they vary across languages. Our analysis reveals that pairs of languages that are geographically or genetically closer tend to mention the same entities more frequently. We also identify entity categories whose saliency is universally high (such as animate beings), low (clothing accessories) or displaying high variance across languages (landscape). In a case study, we measure the differences in a specific language pair (e.g., Japanese mentions clothing far more frequently than English). Furthermore, our method corroborates previous small-scale studies, including 1) Rosch et al. (1976)'s theory of basic-level categories, demonstrating a preference for entities that are neither too generic nor too specific, and 2) Miyamoto et al. (2006)'s hypothesis that environments afford patterns of perception, such as entity counts. Overall, our work reveals the presence of both universal and culture-specific patterns in entity mentions.
A Language-agnostic Model of Child Language Acquisition
Aug 22, 2024



This work reimplements a recent semantic bootstrapping child-language acquisition model, which was originally designed for English, and trains it to learn a new language: Hebrew. The model learns from pairs of utterances and logical forms as meaning representations, and acquires both syntax and word meanings simultaneously. The results show that the model mostly transfers to Hebrew, but that a number of factors, including the richer morphology in Hebrew, makes the learning slower and less robust. This suggests that a clear direction for future work is to enable the model to leverage the similarities between different word forms.
Surveying the Landscape of Image Captioning Evaluation: A Comprehensive Taxonomy and Novel Ensemble Method
Aug 09, 2024The task of image captioning has recently been gaining popularity, and with it the complex task of evaluating the quality of image captioning models. In this work, we present the first survey and taxonomy of over 70 different image captioning metrics and their usage in hundreds of papers. We find that despite the diversity of proposed metrics, the vast majority of studies rely on only five popular metrics, which we show to be weakly correlated with human judgements. Instead, we propose EnsembEval -- an ensemble of evaluation methods achieving the highest reported correlation with human judgements across 5 image captioning datasets, showing there is a lot of room for improvement by leveraging a diverse set of metrics.
In-Context Learning on a Budget: A Case Study in Named Entity Recognition
Jun 19, 2024Few shot in-context learning (ICL) typically assumes access to large annotated training sets. However, in many real world scenarios, such as domain adaptation, there is only a limited budget to annotate a small number of samples, with the goal of maximizing downstream performance. We study various methods for selecting samples to annotate within a predefined budget, specifically focusing on the named entity recognition (NER) task, which has real-world applications, is expensive to annotate, and is relatively less studied in ICL setups. Across different models and datasets, we find that a relatively small pool of annotated samples can achieve results comparable to using the entire training set. Moreover, we discover that random selection of samples for annotation yields surprisingly good performance. Finally, we observe that a diverse annotation pool is correlated with improved performance. We hope that future work adopts our realistic paradigm which takes annotation budget into account.
A Large-Scale Multilingual Study of Visual Constraints on Linguistic Selection of Descriptions
Feb 09, 2023We present a large, multilingual study into how vision constrains linguistic choice, covering four languages and five linguistic properties, such as verb transitivity or use of numerals. We propose a novel method that leverages existing corpora of images with captions written by native speakers, and apply it to nine corpora, comprising 600k images and 3M captions. We study the relation between visual input and linguistic choices by training classifiers to predict the probability of expressing a property from raw images, and find evidence supporting the claim that linguistic properties are constrained by visual context across languages. We complement this investigation with a corpus study, taking the test case of numerals. Specifically, we use existing annotations (number or type of objects) to investigate the effect of different visual conditions on the use of numeral expressions in captions, and show that similar patterns emerge across languages. Our methods and findings both confirm and extend existing research in the cognitive literature. We additionally discuss possible applications for language generation.
A Computational Acquisition Model for Multimodal Word Categorization
May 12, 2022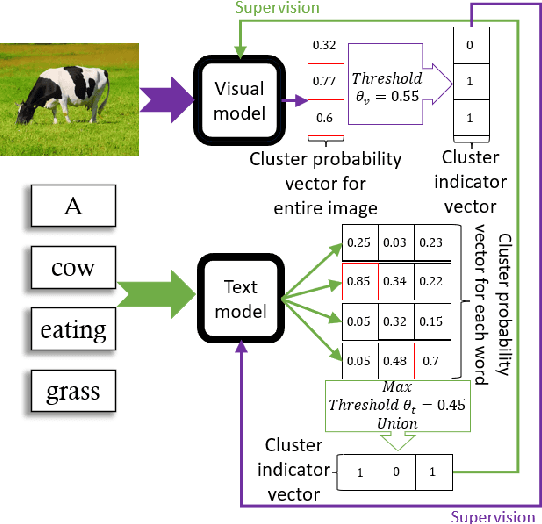


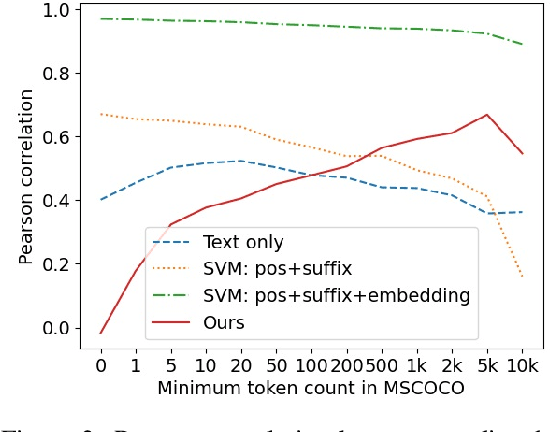
Recent advances in self-supervised modeling of text and images open new opportunities for computational models of child language acquisition, which is believed to rely heavily on cross-modal signals. However, prior studies have been limited by their reliance on vision models trained on large image datasets annotated with a pre-defined set of depicted object categories. This is (a) not faithful to the information children receive and (b) prohibits the evaluation of such models with respect to category learning tasks, due to the pre-imposed category structure. We address this gap, and present a cognitively-inspired, multimodal acquisition model, trained from image-caption pairs on naturalistic data using cross-modal self-supervision. We show that the model learns word categories and object recognition abilities, and presents trends reminiscent of those reported in the developmental literature. We make our code and trained models public for future reference and use.