 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvertrained, Not Misaligned
May 12, 2026Emergent misalignment (EM), where fine-tuning on a narrow task (like insecure code) causes broad misalignment across unrelated domains, was first demonstrated by Betley et al. (2025). We conduct the most comprehensive EM study to date, reproducing the original GPT-4o finding and expanding to 12 open-source models across 4 families (Llama, Qwen, DeepSeek, GPT-OSS) ranging from 8B to 671B parameters, evaluating over one million model responses with multiple random seeds. We find that EM replicates in GPT-4o but is far from universal: only 2 of 12 open-source models (17%) exhibit consistent EM across seeds, with a significant correlation between model size and EM susceptibility. Through checkpoint-level analysis during fine-tuning, we demonstrate that EM emerges late in training, distinct from and subsequent to near convergence of the primary task, suggesting EM emerges from continued training past task convergence. This yields practical mitigations: early stopping eliminates EM while retaining an average of 93% of task performance, and careful learning rate selection further minimizes risk. Cross-domain validation on medical fine-tuning confirms these patterns generalize: the size-EM correlation strengthens (r = 0.90), and overgeneralization to untruthfulness remains avoidable via early stopping in 67% of cases, though semantically proximate training domains produce less separable misalignment. As LLMs become increasingly integrated into real-world systems, fine-tuning and reinforcement learning remain the primary methods for adapting model behavior. Our findings demonstrate that with proper training practices, EM can be avoided, reframing it from an unforeseen fine-tuning risk to an avoidable training artifact.
Motivation in Large Language Models
Mar 15, 2026Motivation is a central driver of human behavior, shaping decisions, goals, and task performance. As large language models (LLMs) become increasingly aligned with human preferences, we ask whether they exhibit something akin to motivation. We examine whether LLMs "report" varying levels of motivation, how these reports relate to their behavior, and whether external factors can influence them. Our experiments reveal consistent and structured patterns that echo human psychology: self-reported motivation aligns with different behavioral signatures, varies across task types, and can be modulated by external manipulations. These findings demonstrate that motivation is a coherent organizing construct for LLM behavior, systematically linking reports, choices, effort, and performance, and revealing motivational dynamics that resemble those documented in human psychology. This perspective deepens our understanding of model behavior and its connection to human-inspired concepts.
Evaluating Alignment of Behavioral Dispositions in LLMs
Feb 11, 2026As LLMs integrate into our daily lives, understanding their behavior becomes essential. In this work, we focus on behavioral dispositions$-$the underlying tendencies that shape responses in social contexts$-$and introduce a framework to study how closely the dispositions expressed by LLMs align with those of humans. Our approach is grounded in established psychological questionnaires but adapts them for LLMs by transforming human self-report statements into Situational Judgment Tests (SJTs). These SJTs assess behavior by eliciting natural recommendations in realistic user-assistant scenarios. We generate 2,500 SJTs, each validated by three human annotators, and collect preferred actions from 10 annotators per SJT, from a large pool of 550 participants. In a comprehensive study involving 25 LLMs, we find that models often do not reflect the distribution of human preferences: (1) in scenarios with low human consensus, LLMs consistently exhibit overconfidence in a single response; (2) when human consensus is high, smaller models deviate significantly, and even some frontier models do not reflect the consensus in 15-20% of cases; (3) traits can exhibit cross-LLM patterns, e.g., LLMs may encourage emotion expression in contexts where human consensus favors composure. Lastly, mapping psychometric statements directly to behavioral scenarios presents a unique opportunity to evaluate the predictive validity of self-reports, revealing considerable gaps between LLMs' stated values and their revealed behavior.
Indications of Belief-Guided Agency and Meta-Cognitive Monitoring in Large Language Models
Feb 02, 2026Rapid advancements in large language models (LLMs) have sparked the question whether these models possess some form of consciousness. To tackle this challenge, Butlin et al. (2023) introduced a list of indicators for consciousness in artificial systems based on neuroscientific theories. In this work, we evaluate a key indicator from this list, called HOT-3, which tests for agency guided by a general belief-formation and action selection system that updates beliefs based on meta-cognitive monitoring. We view beliefs as representations in the model's latent space that emerge in response to a given input, and introduce a metric to quantify their dominance during generation. Analyzing the dynamics between competing beliefs across models and tasks reveals three key findings: (1) external manipulations systematically modulate internal belief formation, (2) belief formation causally drives the model's action selection, and (3) models can monitor and report their own belief states. Together, these results provide empirical support for the existence of belief-guided agency and meta-cognitive monitoring in LLMs. More broadly, our work lays methodological groundwork for investigating the emergence of agency, beliefs, and meta-cognition in LLMs.
Can (A)I Change Your Mind?
Mar 03, 2025



The increasing integration of large language model (LLM) based conversational agents into everyday life raises critical cognitive and social questions about their potential to influence human opinions. Although previous studies have shown that LLM-based agents can generate persuasive content, these typically involve controlled, English-language settings. Addressing this, our preregistered study explored LLM's persuasive capabilities in more ecological, unconstrained scenarios, examining both static (written paragraphs) and dynamic (conversations via Telegram) interaction types. Conducted entirely in Hebrew with 200 participants, the study assessed the persuasive effects of both LLM and human interlocutors on controversial civil policy topics. Results indicated that participants adopted LLM and human perspectives similarly, with significant opinion changes evident across all conditions, regardless of interlocutor type or interaction mode. Confidence levels increased significantly in most scenarios, except in static LLM interactions. These findings demonstrate LLM-based agents' robust persuasive capabilities across diverse sources and settings, highlighting their potential impact on shaping public opinions.
Confidence Improves Self-Consistency in LLMs
Feb 10, 2025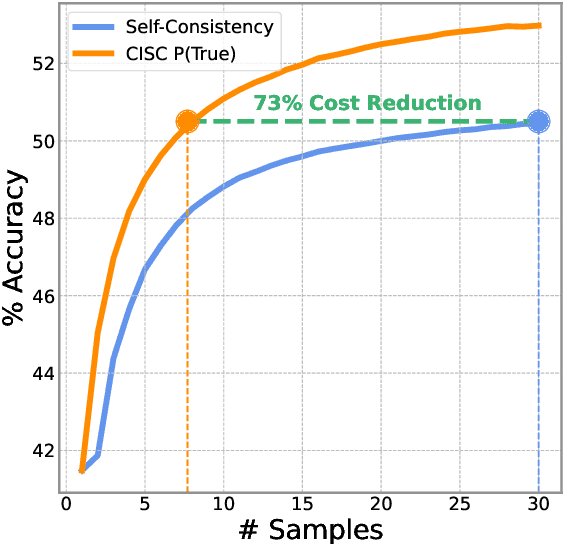
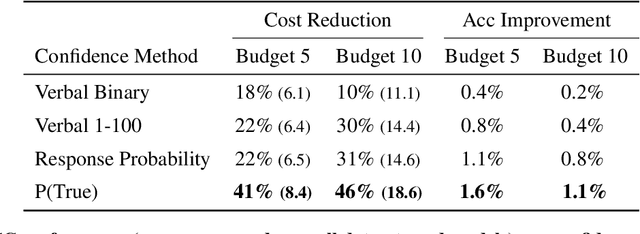

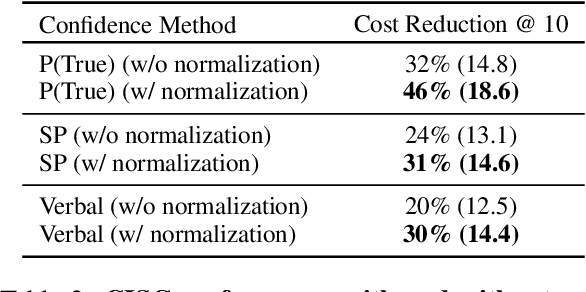
Self-consistency decoding enhances LLMs' performance on reasoning tasks by sampling diverse reasoning paths and selecting the most frequent answer. However, it is computationally expensive, as sampling many of these (lengthy) paths is required to increase the chances that the correct answer emerges as the most frequent one. To address this, we introduce Confidence-Informed Self-Consistency (CISC). CISC performs a weighted majority vote based on confidence scores obtained directly from the model. By prioritizing high-confidence paths, it can identify the correct answer with a significantly smaller sample size. When tested on nine models and four datasets, CISC outperforms self-consistency in nearly all configurations, reducing the required number of reasoning paths by over 40% on average. In addition, we introduce the notion of within-question confidence evaluation, after showing that standard evaluation methods are poor predictors of success in distinguishing correct and incorrect answers to the same question. In fact, the most calibrated confidence method proved to be the least effective for CISC. Lastly, beyond these practical implications, our results and analyses show that LLMs can effectively judge the correctness of their own outputs, contributing to the ongoing debate on this topic.
SAUCE: Synchronous and Asynchronous User-Customizable Environment for Multi-Agent LLM Interaction
Nov 05, 2024



Many human interactions, such as political debates, are carried out in group settings, where there are arbitrarily many participants, each with different views and agendas. To explore such complex social settings, we present SAUCE: a customizable Python platform, allowing researchers to plug-and-play various LLMs participating in discussions on any topic chosen by the user. Our platform takes care of instantiating the models, scheduling their responses, managing the discussion history, and producing a comprehensive output log, all customizable through configuration files, requiring little to no coding skills. A novel feature of SAUCE is our asynchronous communication feature, where models decide when to speak in addition to what to say, thus modeling an important facet of human communication. We show SAUCE's attractiveness in two initial experiments, and invite the community to use it in simulating various group simulations.
Looking Beyond The Top-1: Transformers Determine Top Tokens In Order
Oct 26, 2024



Understanding the inner workings of Transformers is crucial for achieving more accurate and efficient predictions. In this work, we analyze the computation performed by Transformers in the layers after the top-1 prediction has become fixed, which has been previously referred to as the "saturation event". We expand the concept of saturation events for top-k tokens, demonstrating that similar saturation events occur across language, vision, and speech models. We find that these saturation events happen in order of the corresponding tokens' ranking, i.e., the model first decides on the top ranking token, then the second highest ranking token, and so on. This phenomenon seems intrinsic to the Transformer architecture, occurring across different architectural variants (decoder-only, encoder-only, and to a lesser extent full-Transformer), and even in untrained Transformers. We propose an underlying mechanism of task transition for this sequential saturation, where task k corresponds to predicting the k-th most probable token, and the saturation events are in fact discrete transitions between the tasks. In support of this we show that it is possible to predict the current task from hidden layer embedding. Furthermore, using an intervention method we demonstrate that we can cause the model to switch from one task to the next. Finally, leveraging our findings, we introduce a novel token-level early-exit strategy, which surpasses existing methods in balancing performance and efficiency.
Distributional reasoning in LLMs: Parallel reasoning processes in multi-hop reasoning
Jun 19, 2024



Large language models (LLMs) have shown an impressive ability to perform tasks believed to require thought processes. When the model does not document an explicit thought process, it becomes difficult to understand the processes occurring within its hidden layers and to determine if these processes can be referred to as reasoning. We introduce a novel and interpretable analysis of internal multi-hop reasoning processes in LLMs. We demonstrate that the prediction process for compositional reasoning questions can be modeled using a simple linear transformation between two semantic category spaces. We show that during inference, the middle layers of the network generate highly interpretable embeddings that represent a set of potential intermediate answers for the multi-hop question. We use statistical analyses to show that a corresponding subset of tokens is activated in the model's output, implying the existence of parallel reasoning paths. These observations hold true even when the model lacks the necessary knowledge to solve the task. Our findings can help uncover the strategies that LLMs use to solve reasoning tasks, offering insights into the types of thought processes that can emerge from artificial intelligence. Finally, we also discuss the implication of cognitive modeling of these results.
Can LLMs Learn Macroeconomic Narratives from Social Media?
Jun 17, 2024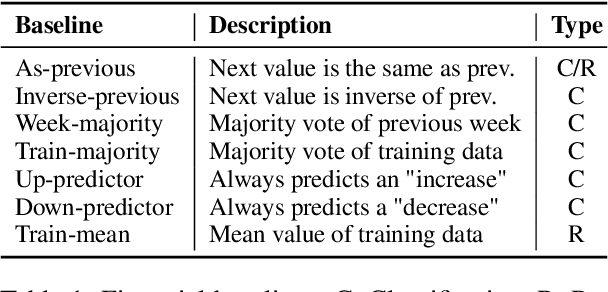


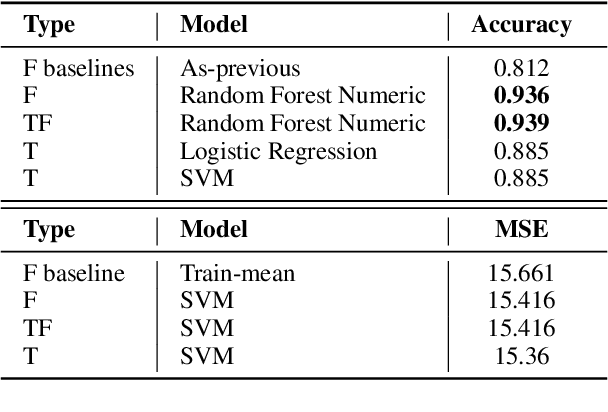
This study empirically tests the $\textit{Narrative Economics}$ hypothesis, which posits that narratives (ideas that are spread virally and affect public beliefs) can influence economic fluctuations. We introduce two curated datasets containing posts from X (formerly Twitter) which capture economy-related narratives (Data will be shared upon paper acceptance). Employing Natural Language Processing (NLP) methods, we extract and summarize narratives from the tweets. We test their predictive power for $\textit{macroeconomic}$ forecasting by incorporating the tweets' or the extracted narratives' representations in downstream financial prediction tasks. Our work highlights the challenges in improving macroeconomic models with narrative data, paving the way for the research community to realistically address this important challenge. From a scientific perspective, our investigation offers valuable insights and NLP tools for narrative extraction and summarization using Large Language Models (LLMs), contributing to future research on the role of narratives in economics.