 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons From Red Teaming 100 Generative AI Products
Jan 13, 2025In recent years, AI red teaming has emerged as a practice for probing the safety and security of generative AI systems. Due to the nascency of the field, there are many open questions about how red teaming operations should be conducted. Based on our experience red teaming over 100 generative AI products at Microsoft, we present our internal threat model ontology and eight main lessons we have learned: 1. Understand what the system can do and where it is applied 2. You don't have to compute gradients to break an AI system 3. AI red teaming is not safety benchmarking 4. Automation can help cover more of the risk landscape 5. The human element of AI red teaming is crucial 6. Responsible AI harms are pervasive but difficult to measure 7. LLMs amplify existing security risks and introduce new ones 8. The work of securing AI systems will never be complete By sharing these insights alongside case studies from our operations, we offer practical recommendations aimed at aligning red teaming efforts with real world risks. We also highlight aspects of AI red teaming that we believe are often misunderstood and discuss open questions for the field to consider.
Controllable Synthetic Clinical Note Generation with Privacy Guarantees
Sep 12, 2024



In the field of machine learning, domain-specific annotated data is an invaluable resource for training effective models. However, in the medical domain, this data often includes Personal Health Information (PHI), raising significant privacy concerns. The stringent regulations surrounding PHI limit the availability and sharing of medical datasets, which poses a substantial challenge for researchers and practitioners aiming to develop advanced machine learning models. In this paper, we introduce a novel method to "clone" datasets containing PHI. Our approach ensures that the cloned datasets retain the essential characteristics and utility of the original data without compromising patient privacy. By leveraging differential-privacy techniques and a novel fine-tuning task, our method produces datasets that are free from identifiable information while preserving the statistical properties necessary for model training. We conduct utility testing to evaluate the performance of machine learning models trained on the cloned datasets. The results demonstrate that our cloned datasets not only uphold privacy standards but also enhance model performance compared to those trained on traditional anonymized datasets. This work offers a viable solution for the ethical and effective utilization of sensitive medical data in machine learning, facilitating progress in medical research and the development of robust predictive models.
Re-aligning Shadow Models can Improve White-box Membership Inference Attacks
Jun 08, 2023



Machine learning models have been shown to leak sensitive information about their training datasets. As models are being increasingly used, on devices, to automate tasks and power new applications, there have been concerns that such white-box access to its parameters, as opposed to the black-box setting which only provides query access to the model, increases the attack surface. Directly extending the shadow modelling technique from the black-box to the white-box setting has been shown, in general, not to perform better than black-box only attacks. A key reason is misalignment, a known characteristic of deep neural networks. We here present the first systematic analysis of the causes of misalignment in shadow models and show the use of a different weight initialisation to be the main cause of shadow model misalignment. Second, we extend several re-alignment techniques, previously developed in the model fusion literature, to the shadow modelling context, where the goal is to re-align the layers of a shadow model to those of the target model.We show re-alignment techniques to significantly reduce the measured misalignment between the target and shadow models. Finally, we perform a comprehensive evaluation of white-box membership inference attacks (MIA). Our analysis reveals that (1) MIAs suffer from misalignment between shadow models, but that (2) re-aligning the shadow models improves, sometimes significantly, MIA performance. On the CIFAR10 dataset with a false positive rate of 1\%, white-box MIA using re-aligned shadow models improves the true positive rate by 4.5\%.Taken together, our results highlight that on-device deployment increase the attack surface and that the newly available information can be used by an attacker.
Bayesian Estimation of Differential Privacy
Jun 15, 2022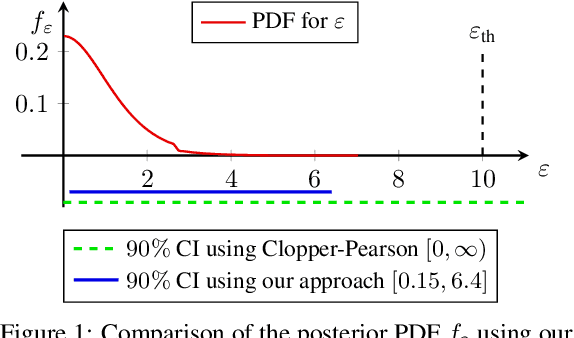

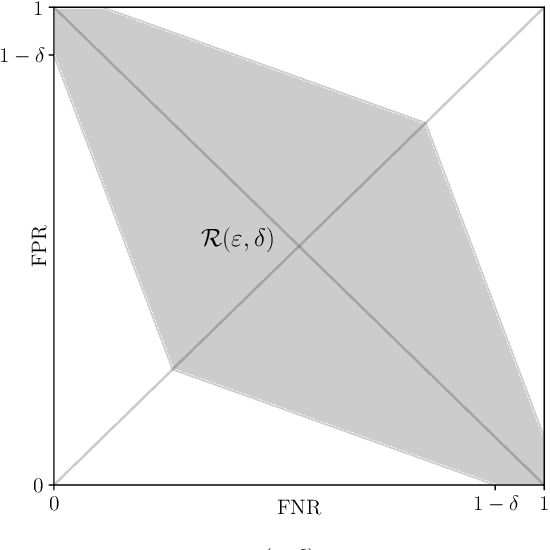
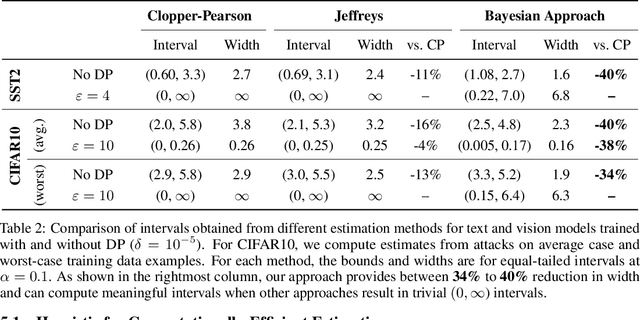
Algorithms such as Differentially Private SGD enable training machine learning models with formal privacy guarantees. However, there is a discrepancy between the protection that such algorithms guarantee in theory and the protection they afford in practice. An emerging strand of work empirically estimates the protection afforded by differentially private training as a confidence interval for the privacy budget $\varepsilon$ spent on training a model. Existing approaches derive confidence intervals for $\varepsilon$ from confidence intervals for the false positive and false negative rates of membership inference attacks. Unfortunately, obtaining narrow high-confidence intervals for $\epsilon$ using this method requires an impractically large sample size and training as many models as samples. We propose a novel Bayesian method that greatly reduces sample size, and adapt and validate a heuristic to draw more than one sample per trained model. Our Bayesian method exploits the hypothesis testing interpretation of differential privacy to obtain a posterior for $\varepsilon$ (not just a confidence interval) from the joint posterior of the false positive and false negative rates of membership inference attacks. For the same sample size and confidence, we derive confidence intervals for $\varepsilon$ around 40% narrower than prior work. The heuristic, which we adapt from label-only DP, can be used to further reduce the number of trained models needed to get enough samples by up to 2 orders of magnitude.
Privacy Analysis in Language Models via Training Data Leakage Report
Jan 14, 2021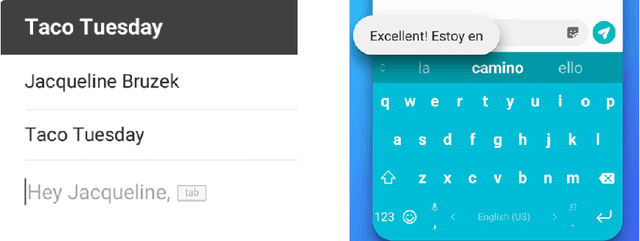

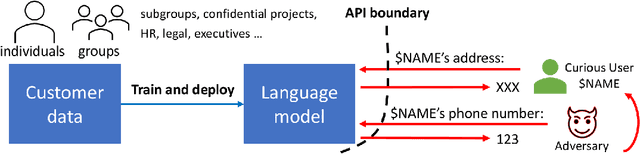
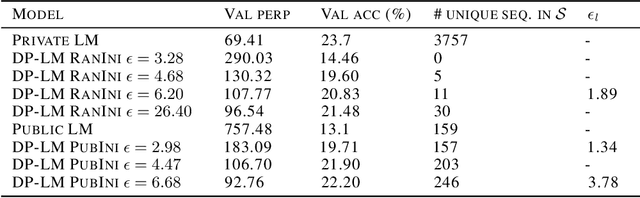
Recent advances in neural network based language models lead to successful deployments of such models, improving user experience in various applications. It has been demonstrated that strong performance of language models may come along with the ability to memorize rare training samples, which poses serious privacy threats in case the model training is conducted on confidential user content. This necessitates privacy monitoring techniques to minimize the chance of possible privacy breaches for the models deployed in practice. In this work, we introduce a methodology that investigates identifying the user content in the training data that could be leaked under a strong and realistic threat model. We propose two metrics to quantify user-level data leakage by measuring a model's ability to produce unique sentence fragments within training data. Our metrics further enable comparing different models trained on the same data in terms of privacy. We demonstrate our approach through extensive numerical studies on real-world datasets such as email and forum conversations. We further illustrate how the proposed metrics can be utilized to investigate the efficacy of mitigations like differentially private training or API hardening.