 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy Analysis in Language Models via Training Data Leakage Report
Paper and Code
Jan 14, 2021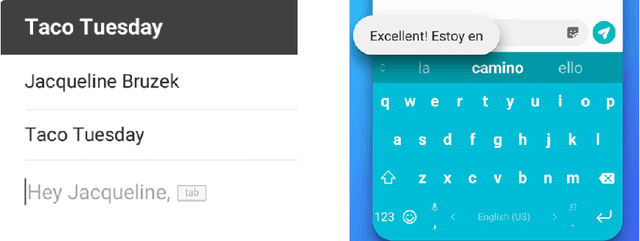

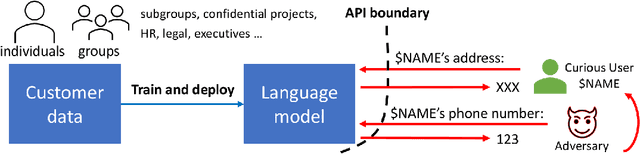
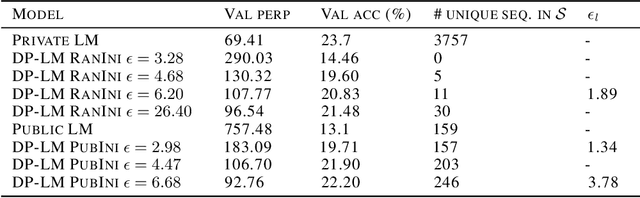
Recent advances in neural network based language models lead to successful deployments of such models, improving user experience in various applications. It has been demonstrated that strong performance of language models may come along with the ability to memorize rare training samples, which poses serious privacy threats in case the model training is conducted on confidential user content. This necessitates privacy monitoring techniques to minimize the chance of possible privacy breaches for the models deployed in practice. In this work, we introduce a methodology that investigates identifying the user content in the training data that could be leaked under a strong and realistic threat model. We propose two metrics to quantify user-level data leakage by measuring a model's ability to produce unique sentence fragments within training data. Our metrics further enable comparing different models trained on the same data in terms of privacy. We demonstrate our approach through extensive numerical studies on real-world datasets such as email and forum conversations. We further illustrate how the proposed metrics can be utilized to investigate the efficacy of mitigations like differentially private training or API hardening.